This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
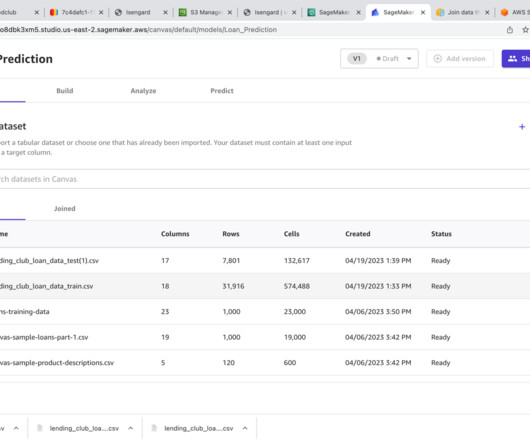
This article will explore data warehousing, its architecture types, key components, benefits, and challenges. What is Data Warehousing? Data warehousing is a data management system to support BusinessIntelligence (BI) operations. It can handle vast amounts of data and facilitate complex queries.
Analytics, management, and businessintelligence (BI) procedures, such as data cleansing, transformation, and decision-making, rely on data profiling. Content and quality reviews are becoming more important as data sets grow in size and variety of sources.
This post highlights how Twilio enabled natural language-driven data exploration of businessintelligence (BI) data with RAG and Amazon Bedrock. Twilio’s use case Twilio wanted to provide an AI assistant to help their data analysts find data in their data lake.
LLM-powered dataanalysis The transcribed interviews and ingested documents are fed into a powerful LLM, which can understand and correlate the information from multiple sources. The LLM can identify key insights, potential issues, and areas of non-compliance by analyzing the content and context of the data.
On the other hand, a Data Warehouse is a structured storage system designed for efficient querying and analysis. It involves the extraction, transformation, and loading (ETL) process to organize data for businessintelligence purposes. It often serves as a source for Data Warehouses.
To create and share customer feedback analysis without the need to manage underlying infrastructure, Amazon QuickSight provides a straightforward way to build visualizations, perform one-time analysis, and quickly gain business insights from customer feedback, anytime and on any device.
Summary: The blog delves into the 2024 Data Analyst career landscape, focusing on critical skills like Data Visualisation and statistical analysis. It identifies emerging roles, such as AI Ethicist and Healthcare Data Analyst, reflecting the diverse applications of DataAnalysis.
Business analysts play a pivotal role in facilitating data-driven business decisions through activities such as the visualization of business metrics and the prediction of future events. You can add metadata to the policy by attaching tags as key-value pairs, then choose Next: Review. Choose Next: Tags.
Master Nodes The master node is responsible for managing the cluster’s resources and coordinating the data processing tasks. It typically runs several critical services: NameNode: This service manages the Hadoop Distributed File System (HDFS) metadata, keeping track of the location of data blocks across the cluster.
Key Takeaways Big Data originates from diverse sources, including IoT and social media. Data lakes and cloud storage provide scalable solutions for large datasets. Processing frameworks like Hadoop enable efficient dataanalysis across clusters.
So, how do these tools help to enable data mesh? The open-source data catalogs provide several key features that are beneficial for a data mesh. These include a centralized metadata repository to enable the discovery of data assets across decentralized data domains. Maintain the data mesh infrastructure.
Network software facilitates data communication, and application software interacts with the DBMS to perform specific tasks. Data The core of the system. It includes the database itself, which is a collection of interrelated data. Metadata, or data about data, describes the database’s structure and organisation.
Key Takeaways Big Data originates from diverse sources, including IoT and social media. Data lakes and cloud storage provide scalable solutions for large datasets. Processing frameworks like Hadoop enable efficient dataanalysis across clusters.
It enables businesses and organizations to analyze calls using the most up-to-date speech and natural language processing technologies effectively. The tool can be integrated with other businessintelligence software. You can schedule a demo with an Observe.AI solution architect to learn more about the platform.
This period also saw the development of the first data warehouses, large storage repositories that held data from different sources in a consistent format. The concept of data warehousing was introduced by Bill Inmon, often referred to as the “father of data warehousing.”
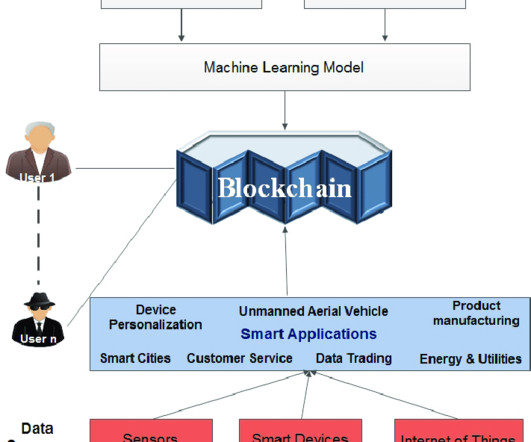
The data in other blockchain applications can represent various information, including voting records, medical records, identification information, supply chain data, and executable code for smart contracts. The block header is the first piece of metadata in each block. Nonce: This is a complete 32-bit value.
It leverages both GPU and CPU processing to query massive datasets quickly, with support for SQL and geospatial data. The platform includes visual analytics tools for interactive dashboards, cross-filtering, and scalable data visualizations, enabling efficient big dataanalysis across various industries. How does HEAVY.AI
AWS data engineering pipeline The adaptable approach detailed in this post starts with an automated data engineering pipeline to make data stored in Splunk available to a wide range of personas, including businessintelligence (BI) analysts, data scientists, and ML practitioners, through a SQL interface.
By leveraging data services and APIs, a data fabric can also pull together data from legacy systems, data lakes, data warehouses and SQL databases, providing a holistic view into business performance. It uses knowledge graphs, semantics and AI/ML technology to discover patterns in various types of metadata.
As a software suite, it encompasses a range of interconnected products, including Tableau Desktop, Server, Cloud, Public, Prep, and Data Management, and Reader. At its core, it is designed to help people see and understand data. It disrupts traditional businessintelligence with intuitive, visual analytics for everyone.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content