
Amazon SageMaker Feature Store now supports cross-account sharing, discovery, and access
AWS Machine Learning Blog
FEBRUARY 13, 2024
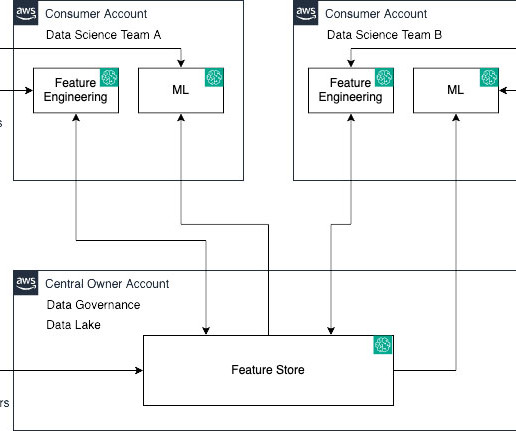
Let’s demystify this using the following personas and a real-world analogy: Data and ML engineers (owners and producers) – They lay the groundwork by feeding data into the feature store Data scientists (consumers) – They extract and utilize this data to craft their models Data engineers serve as architects sketching the initial blueprint.












Let's personalize your content