This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Driven by significant advancements in computing technology, everything from mobile phones to smart appliances to mass transit systems generate and digest data, creating a bigdata landscape that forward-thinking enterprises can leverage to drive innovation. However, the bigdata landscape is just that.
Overview of Kubernetes Containers —lightweight units of software that package code and all its dependencies to run in any environment—form the foundation of Kubernetes and are mission-critical for modern microservices, cloud-native software and DevOps workflows.
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, data lakes, and datascience teams, and maintaining compliance with relevant financial regulations.
Cloud computing and datascience are interconnected, making data-related cloud skills highly valuable. Understanding the Role of a Cloud Engineer Cloud computing has changed how businesses store and access data. Understand DevOps and CI/CD Cloud Engineers often work closely with DevOps teams to ensure smooth deployments.
Photo by CDC on Unsplash The Data Scientist Show, by Daliana Liu, is one of my favorite YouTube channels. Unlike many other datascience programs that are very technical and require concentration to follow through, Daliana’s talk show strikes a delicate balance between profession and relaxation. Knows MLOps practices.
How can a DevOps team take advantage of Artificial Intelligence (AI)? DevOps is mainly the practice of combining different teams including development and operations teams to make improvements in the software delivery processes. So now, how can a DevOps team take advantage of Artificial Intelligence (AI)?
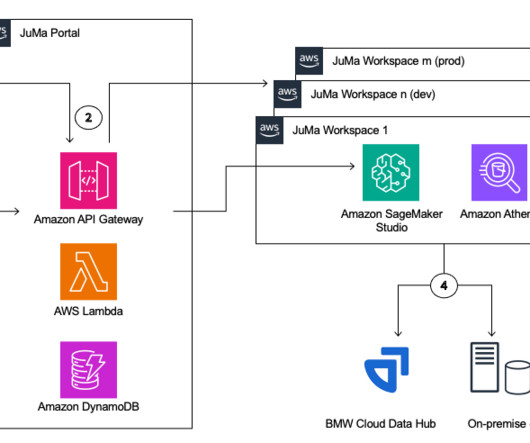
The service streamlines ML development and production workflows (MLOps) across BMW by providing a cost-efficient and scalable development environment that facilitates seamless collaboration between datascience and engineering teams worldwide. This results in faster experimentation and shorter idea validation cycles.
Since the rise of DataScience, it has found several applications across different industrial domains. However, the programming languages that work at the core of DataScience play a significant role in it. Hence for an individual who wants to excel as a data scientist, learning Python is a must.
She is currently focusing on combining her DevOps and ML background into the domain of MLOps to help customers deliver and manage ML workloads at scale. With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes.
Decision-making AI can help with data-driven decision-making by analyzing large datasets and providing insights that humans might miss. Applied to bigdata , these advanced analytics can improve strategic planning, risk management and resource allocation.
Decision-making AI can help with data-driven decision-making by analyzing large datasets and providing insights that humans might miss. Applied to bigdata , these advanced analytics can improve strategic planning, risk management and resource allocation.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
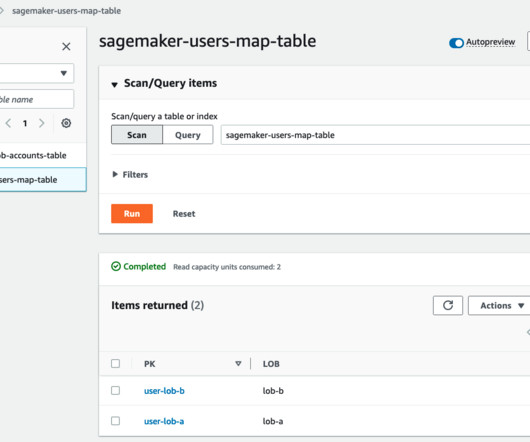
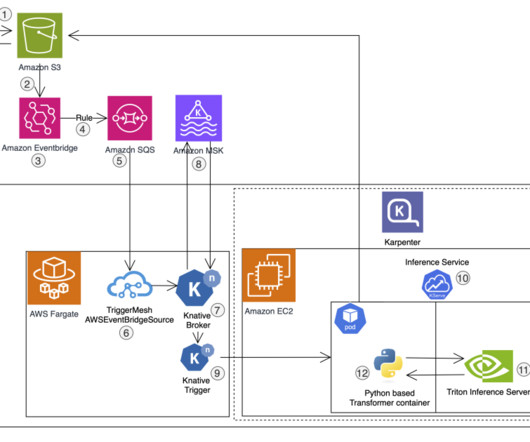
The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , SageMaker, AWS DevOps services, and a data lake. The architecture maps the different capabilities of the ML platform to AWS accounts.
Architecture overview The architecture is implemented as follows: DataScience Account – Data Scientists conduct their experiments in SageMaker Studio and build an MLOps setup to deploy models to staging/production environments using SageMaker Projects. His core area of focus includes Machine Learning, DevOps, and Containers.
Check that the SageMaker image selected is a Conda-supported first-party kernel image such as “DataScience.” From the new notebook, choose the “Python 3 (DataScience)” kernel. He develops and codes cloud native solutions with a focus on bigdata, analytics, and data engineering.
This is done using their “3D” approach: DevOps, design, and digital transformation. Lil Projects Lil Projects provides businesses with a set of services aimed at using datascience, automation, and AI to empower companies to optimize their campaigns and generate returns. Get your pass today!
IBM merged the critical capabilities of the vendor into its more contemporary Watson Studio running on the IBM Cloud Pak for Data platform as it continues to innovate. The platform makes collaborative datascience better for corporate users and simplifies predictive analytics for professional data scientists.
AI for DevOps and CI/CD: Streamlining the Pipeline Continuous Integration and Continuous Delivery (CI/CD) are essential components of modern software development, and AI is now helping to optimize this process. In the world of DevOps, AI can help monitor infrastructure, analyze logs, and detect performance bottlenecks in real-time.
He has touched on most aspects of these projects, from infrastructure and DevOps to software development and AI/ML. He collaborates closely with enterprise customers building modern data platforms, generative AI applications, and MLOps. Beyond work, he values quality time with family and embraces opportunities for travel.
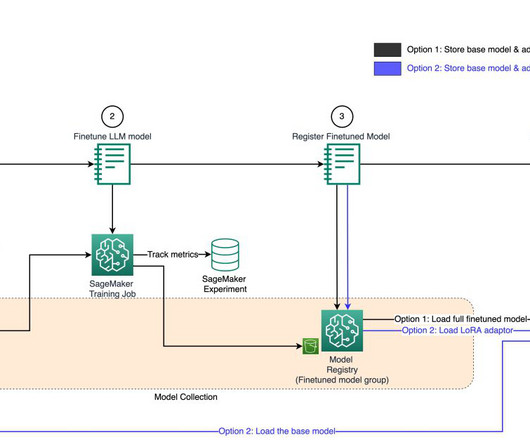
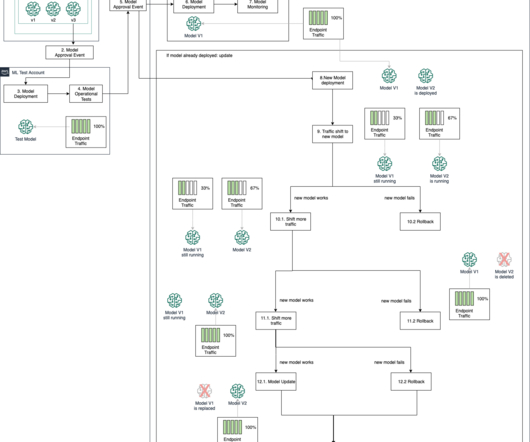
A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team. For the customer, this helps them reduce the time it takes to bootstrap a new datascience project and get it to production.
Abdullahi holds a MSC in Computer Networking from Wichita State University and is a published author that has held roles across various technology domains such as DevOps, infrastructure modernization and AI. In entered the BigData space in 2013 and continues to explore that area.
In the era of bigdata and AI, companies are continually seeking ways to use these technologies to gain a competitive edge. At the core of these cutting-edge solutions lies a foundation model (FM), a highly advanced machine learning model that is pre-trained on vast amounts of data.
These customers need to balance governance, security, and compliance against the need for machine learning (ML) teams to quickly access their datascience environments in a secure manner. Alberto Menendez is an Associate DevOps Consultant in Professional Services at AWS. In her spare time, she enjoys reading and being outdoors.
Datascience teams often face challenges when transitioning models from the development environment to production. Usually, there is one lead data scientist for a datascience group in a business unit, such as marketing. ML Dev Account This is where data scientists perform their work.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between datascience experimentation and deployment while meeting the requirements around model performance, security, and compliance.
In a broader model development picture, models are typically trained in a datascience development account. With a background in datascience, she has 9 years of experience architecting and building ML applications with customers across industries. She is also the Co-Director of Women In BigData (WiBD), Denver chapter.
This architecture design represents a multi-account strategy where ML models are built, trained, and registered in a central model registry within a datascience development account (which has more controls than a typical application development account). He’s a pet lover and is passionate about snowboarding and traveling.
She is currently focusing on combining her DevOps and ML background into the domain of MLOps to help customers deliver and manage ML workloads at scale. With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes.
Architecture overview The architecture is implemented as follows: DataScience Account – Data Scientists conduct their experiments in SageMaker Studio and build an MLOps setup to deploy models to staging/production environments using SageMaker Projects. His core area of focus includes Machine Learning, DevOps, and Containers.
Making credit decisions using AI can be challenging, requiring datascience and portfolio teams to synthesize complex subject matter information and collaborate productively. In this example, we start with the datascience or portfolio agent. However, we envision many more agents in the future.
She has innovated and delivered several product lines and services specializing in distributed systems, cloud computing, bigdata, machine learning and security. Prior to Amplitude , she was VP of Engineering at Palo Alto Networks. That led me to pursue engineering at Sharif University of Technology in Iran and later get my Ph.D.
It’s widely used in datascience, machine learning, artificial intelligence, and web development. Python’s extensive libraries, like NumPy, Pandas, and TensorFlow, make it a powerful tool for data analysis and scientific computing. It’s used in Android app development, server-side development, and datascience.
We explored multiple bigdata processing solutions and decided to use an Amazon SageMaker Processing job for the following reasons: It’s highly configurable, with support of pre-built images, custom cluster requirements, and containers. He is also a cycling enthusiast.
The next important step is to use these model results with proper analytics and datascience. These results can also serve as a data source for generative AI features such as automated report generation. He joined the company with previous Platform, Kubernetes, DevOps, and BigData knowledge and was training LLMs from scratch.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content