This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Google has been a frontrunner in AI research, contributing significantly to the open-source community with transformative technologies like TensorFlow, BERT, T5, JAX, AlphaFold, and AlphaCode. What is Gemma LLM?
LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). OpenAI API, provided by OpenAI, supports the ResponsibleAI Framework, emphasizing ethical and responsibleAI use. LLMs can understand the complexities of human language better than other models.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Its AI courses provide valuable knowledge and hands-on experience, helping learners build and optimize AI models, understand advanced AI concepts, and apply AI solutions to real-world problems.
Introduction to ResponsibleAI Image Source Course difficulty: Beginner-level Completion time: ~ 1 day (Complete the quiz/lab in your own time) Prerequisites: No What will AI enthusiasts learn? What is Responsible Artificial Intelligence ? An introduction to the 7 ResponsibleAI principles of Google.
This microlearning module is perfect for those curious about how AI can generate content and innovate across various fields. Introduction to ResponsibleAI : This course focuses on the ethical aspects of AI technology. It introduces learners to responsibleAI and explains why it is crucial in developing AI systems.
Ambiguity is a common challenge chatbots face, but self-reflection enables them to seek clarifications or provide context-aware responses that enhance understanding. By introspecting and analyzing their processes, biases, and decision-making, these systems can improve response accuracy, reduce bias, and foster inclusivity.
AI Use Case Imagine you are designing a system that selects a different LLM (e.g., BERT, GPT, or T5) based on the task. forms, REST API responses). AI Engineering : Patterns must handle data variability in both structure and scale, including: Streaming data for real-time systems. Multimodal data (e.g.,
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. Prior to AWS, he led AI Enterprise Solutions at Wells Fargo.
The Boom of Generative AI and Large Language Models(LLMs) 20182020: NLP was gaining traction, with a focus on word embeddings, BERT, and sentiment analysis. 20232024: The emergence of GPT-4, Claude, and open-source LLMs dominated discussions, highlighting real-world applications, fine-tuning techniques, and AI safety concerns.
As we continue to integrate AI more deeply into various sectors, the ability to interpret and understand these models becomes not just a technical necessity but a fundamental requirement for ethical and responsibleAI development. This presents an inherent tradeoff between scale, capability, and interpretability.
Simultaneously, concerns around ethical AI , bias , and fairness led to more conversations on ResponsibleAI. Topics such as explainability (XAI) and AI governance gained traction, reflecting the growing societal impact of AI technologies.
Techniques like Word2Vec and BERT create embedding models which can be reused. BERT produces deep contextual embeddings by masking words and predicting them based on bidirectional context. BERT produces deep contextual embeddings by masking words and predicting them based on bidirectional context.
Traditional neural network models like RNNs and LSTMs and more modern transformer-based models like BERT for NER require costly fine-tuning on labeled data for every custom entity type. This makes adopting and scaling these approaches burdensome for many applications.
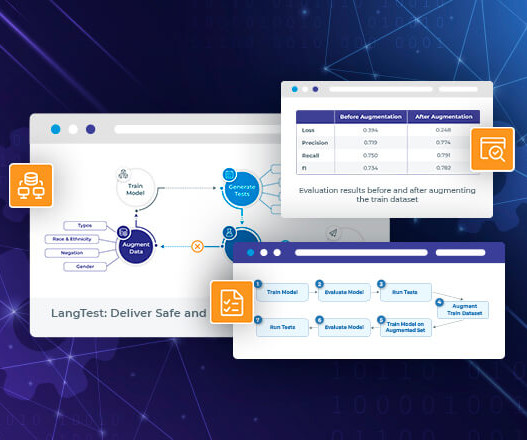
For the sake of this example we chose to use bert-base-cased and train it on the ConLL dataset. As we strive for responsibleAI development, this new feature in LangTest is a step forward in promoting easy to use ethical AI practices and ensuring the responsible deployment of language models in real-world scenarios.
Now let’s check the results for a commonly used model: bert-base-uncased How to Run? While intrasentence tests showed promising performance for bert-base-uncased , there is room for improvement in intersentence tests, indicating the need for continued research and development in the field of bias detection and mitigation.
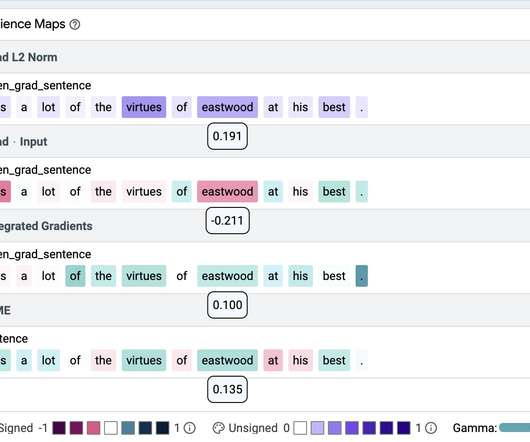
For that we use a BERT-base model trained as a sentiment classifier on the Stanford Sentiment Treebank (SST2). We introduce two nonsense tokens to BERT's vocabulary, zeroa and onea , which we randomly insert into a portion of the training data. Input Salience Method Precision Gradient L2 1.00 Gradient x Input 0.31
Using this approach, for the first time, we were able to effectively train BERT using simple SGD without the need for adaptivity. BERT ) to a factorized dual-encoder , an important setting for the task of scoring the relevance of a [ query , document ] pair. We also researched new recipes for distillation from a cross-encoder (e.g.,
report() Output of the.report() In this snippet, we defined the task as crows-pairs , the model as bert-base-uncased from huggingface , and the data as CrowS-Pairs. This ensures that the broad range of AI applications remains equitable, impartial, and truly representative of a forward-thinking society.
You can directly use the FMEval wherever you run your workloads, as a Python package or via the open-source code repository, which is made available in GitHub for transparency and as a contribution to the ResponsibleAI community. FMEval allows you to upload your own prompt datasets and algorithms.
LangTest has already made waves in the AI community, showcasing its efficacy in identifying and resolving significant ResponsibleAI challenges. With support for numerous language model providers and a vast array of tests, it is poised to be an invaluable asset for any AI team. Why Integrate MLFlow Tracking with LangTest?
Bert paper has demos from HF spaces and Replicate. By going to the Demos tab of the paper in the arXiv categories of computer science, statistics, or electrical engineering and systems science, open source demos can be observed from the HF Spaces.
This trend started with models like the original GPT and ELMo, which had millions of parameters, and progressed to models like BERT and GPT-2, with hundreds of millions of parameters. Psychological harm when users seek emotional support from chatbots, only to receive harmful responses. months on average.
This successful implementation demonstrates how responsibleAI and high-performing models can align. ResponsibleAI starts with a responsible approach to data The promise of Large Language Models (LLMs) is that they will help us with a variety of different tasks.
Step 2: Choose the Generative AI Model Generative AI has different types of models created for a specific purpose. Some of the AI models are: ● Text Generation: Models like GPT-4 and BERT are mostly used to develop conversational chatbots. Retrain or fine-tune it if necessary.
A noteworthy observation is that even popular models in the machine learning community, such as bert-base-uncased, xlm-roberta-base, etc exhibit these biases. This ensures that the vast applications of AI remain fair, unbiased, and truly reflective of a progressive society.
While we have trained BERT and transformers with DP, understanding training example memorization in large language models (LLMs) is a heuristic way to evaluate their privacy. In particular, we investigated when and why LLMs forget (potentially memorized) training examples during training.
With Amazon Bedrock, developers can experiment, evaluate, and deploy generative AI applications without worrying about infrastructure management. Its enterprise-grade security, privacy controls, and responsibleAI features enable secure and trustworthy generative AI innovation at scale.
ResponsibleAI: Getting from Goals to Daily Practices How is it possible to develop AI models that are transparent, safe, and equitable? As AI impacts more aspects of our daily lives, concerns about discrimination, privacy, and bias are on the rise.
We also support ResponsibleAI projects directly for other organizations — including our commitment of $3M to fund the new INSAIT research center based in Bulgaria. MultiBERTs Predictions on Winogender Predictions of BERT on Winogender before and after several different interventions.
Large language models (LLMs) are transformer-based models trained on a large amount of unlabeled text with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
In my experience, models like GPT-3 and BERT have consistently excelled in diverse areas, from generating text to evaluating sentiments” adds Dr. Fatema Nafa, Assistant Professor, Computer Science Department at Salem State University. Swagata Ashwani, Data Science Lead at Boomi, adds, “Domain-specific knowledge is pivotal.
One of the standout achievements in this domain is the development of models like GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers). They owe their success to many factors, including substantial computational resources, vast training data, and sophisticated architectures.
For a BERT model on an Edge TPU-based multi-chip mesh, this approach discovers a better distribution of the model across devices using a much smaller time budget compared to non-learned search strategies. A Transferable Approach for Partitioning Machine Learning Models on Multi-Chip-Modules ” proposes a slightly different approach.
EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machine learning to responsibleAI. series (Davinci, etc), GPT-4, and GPT-4 Turbo are immensely popular.
It came to its own with the creation of the transformer architecture: Google’s BERT, OpenAI, GPT2 and then 3, LaMDA for conversation, Mina and Sparrow from Google DeepMind. The responsibleAI measures pertaining to safety and misuse and robustness are elements that need to be additionally taken into consideration.
It came to its own with the creation of the transformer architecture: Google’s BERT, OpenAI, GPT2 and then 3, LaMDA for conversation, Mina and Sparrow from Google DeepMind. The responsibleAI measures pertaining to safety and misuse and robustness are elements that need to be additionally taken into consideration.
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. RoBERTa: A Robustly Optimized BERT Pretraining Approach.
Google has established itself as a dominant force in the realm of AI, consistently pushing the boundaries of AI research and innovation. These breakthroughs have paved the way for transformative AI applications across various industries, empowering organizations to leverage AI’s potential while navigating ethical considerations.
Google has established itself as a dominant force in the realm of AI, consistently pushing the boundaries of AI research and innovation. These breakthroughs have paved the way for transformative AI applications across various industries, empowering organizations to leverage AI’s potential while navigating ethical considerations.
Advanced Techniques: Features advanced techniques such as transformers, BERT, and recurrent neural networks (RNNs). AI ethics ensures that AI systems operate transparently, fairly, and accountable. AI in Automation AI transforms industries by enhancing efficiency and productivity.
Use Case Model Name Size On Disk Number of Parameters CV resnet50 100Mb 25M CV convnext_base 352Mb 88M CV vit_large_patch16_224 1.2Gb 304M NLP bert-base-uncased 436Mb 109M NLP roberta-large 1.3Gb 335M The following table lists the GPU instances tested. We tested two NLP models: bert-base-uncased (109M) and roberta-large (335M).
The momentum continued in 2017 with the introduction of transformer models like BERT and GPT, which revolutionized natural language processing. These models made AI tasks more efficient and cost-effective. By 2020, OpenAI's GPT-3 set new standards for AI capabilities, highlighting the high costs of training such large models.
An SOC is an organizational unit responsible for monitoring, detecting, analyzing, and responding to cybersecurity threats and incidents. Amazon Bedrock Guardrails enables you to implement safeguards for your generative AI applications based on your use cases and responsibleAI policies.
It is a family of embedding models with a BERT-like architecture, designed to produce high-quality embeddings from text data. You can find the full code associated with this post at the accompanying GitHub repository. Solution overview BGE stands for Beijing Academy of Artificial Intelligence (BAAI) General Embeddings.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















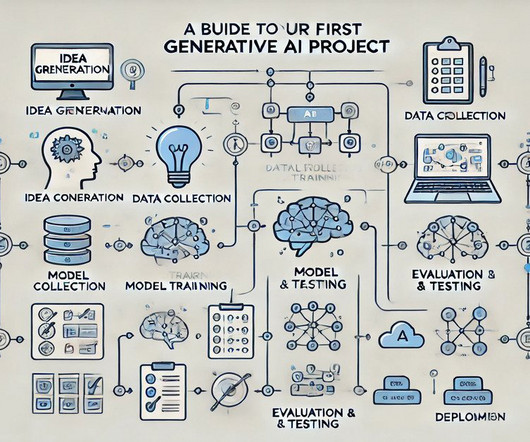



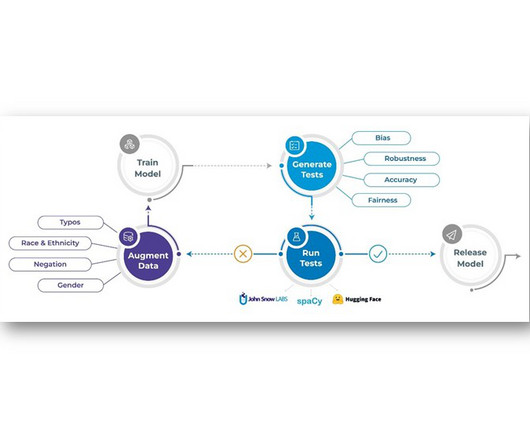







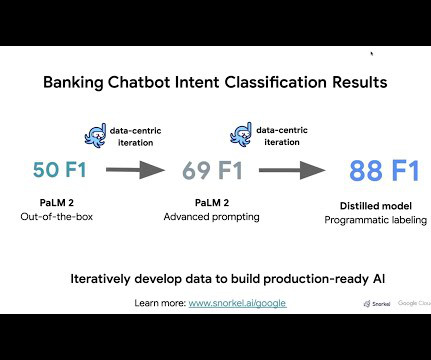
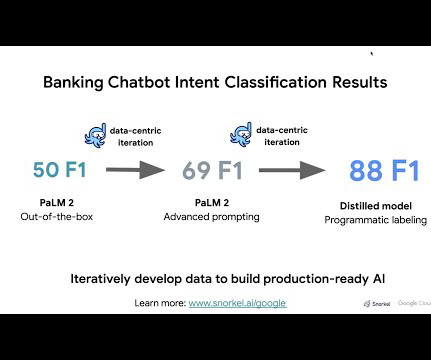

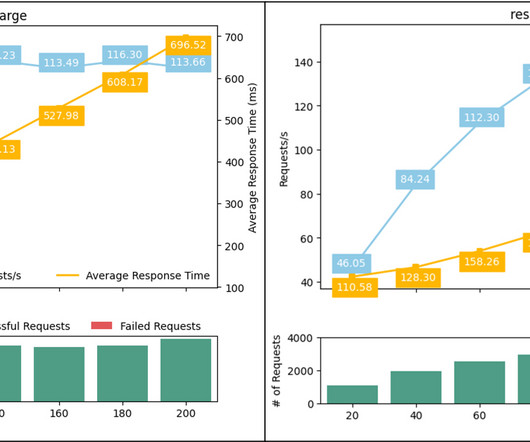









Let's personalize your content