This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Natural Language Processing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. The introduction of word embeddings, most notably Word2Vec, was a pivotal moment in NLP. One-hot encoding is a prime example of this limitation.
The post An Exhaustive Guide to Detecting and Fighting Neural Fake News using NLP appeared first on Analytics Vidhya. Overview Neural fake news (fake news generated by AI) can be a huge issue for our society This article discusses different Natural Language Processing.
OpenAI Embeddings Strengths: Comprehensive Training: OpenAI’s embeddings, including text and image embeddings, are trained on massive datasets. This extensive training allows the embeddings to capture semantic meanings effectively, enabling advanced NLP tasks. Let’s compare 15 popular embedding libraries.
Examples of Generative AI: Text Generation: Models like OpenAIs GPT-4 can generate human-like text for chatbots, content creation, and more. Music Generation: AI models like OpenAIs Jukebox can compose original music in various styles. GPT, BERT) Image Generation (e.g., Explore text generation models like GPT and BERT.
LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). Some examples are OpenAI , Hugging Face , and Weights & Biases. OpenAI, an AI research company, offers various services and models, including GPT-4, DALL-E, CLIP, and DINOv2.
Take, for instance, word embeddings in natural language processing (NLP). Creating embeddings for natural language usually involves using pre-trained models such as: GPT-3 and GPT-4 : OpenAI's GPT-3 (Generative Pre-trained Transformer 3) has been a monumental model in the NLP community with 175 billion parameters.
A Complete Guide to Embedding For NLP & Generative AI/LLM By Mdabdullahalhasib This article provides a comprehensive guide to understanding and implementing vector embedding in NLP and generative AI.
In recent years, Natural Language Processing (NLP) has undergone a pivotal shift with the emergence of Large Language Models (LLMs) like OpenAI's GPT-3 and Google’s BERT. These models, characterized by their large number of parameters and training on extensive text corpora, signify an innovative advancement in NLP capabilities.
And truly, there can’t be an effective RAG without an NLP library that is production-ready, natively distributed, state-of-the-art, and user-friendly. We’re excited to unveil Spark NLP 5.1 with: New OpenAI Whisper, Embeddings and Completions! New Features Spark NLP ONNX (toujours) In Spark NLP 5.1.0,
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
OpenAI Embeddings Strengths: Comprehensive Training: OpenAI’s embeddings, including text and image embeddings, are trained on massive datasets. This extensive training allows the embeddings to capture semantic meanings effectively, enabling advanced NLP tasks. Let’s compare 15 popular embedding libraries.
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. Let’s delve into the role of transformers in NLP and elucidate the process of training LLMs using this innovative architecture. appeared first on MarkTechPost.
In my previous articles about transformers and GPTs, we have done a systematic analysis of the timeline and development of NLP. Prerequisite Before we dive into understanding BERT, we need to understand in order to create the model, the authors have used or referenced several concepts and improvements from several other preceding works.
With advancements in deep learning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Transformers and Advanced NLP Models : The introduction of transformer architectures revolutionized the NLP landscape.
In the evolving landscape of natural language processing (NLP), the ability to grasp and process extensive textual contexts is paramount. The architecture of nomicembed-text-v1 reflects a thoughtful adaptation of BERT to accommodate the extended sequence length. Recent advancements, as highlighted by Lewis et al. 2021), Izacard et al.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Impact V.2
GPT 3 and similar Large Language Models (LLM) , such as BERT , famous for its bidirectional context understanding, T-5 with its text-to-text approach, and XLNet , which combines autoregressive and autoencoding models, have all played pivotal roles in transforming the Natural Language Processing (NLP) paradigm.
OpenAI has been instrumental in developing revolutionary tools like the OpenAI Gym, designed for training reinforcement algorithms, and GPT-n models. One such model that has garnered considerable attention is OpenAI's ChatGPT , a shining exemplar in the realm of Large Language Models.
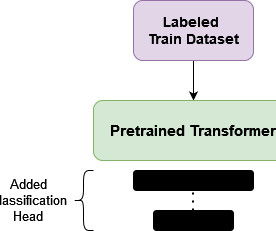
Introduction The idea behind using fine-tuning in Natural Language Processing (NLP) was borrowed from Computer Vision (CV). Despite the popularity and success of transfer learning in CV, for many years it wasnt clear what the analogous pretraining process was for NLP. How is Fine-tuning Different from Pretraining?
However, as technology advanced, so did the complexity and capabilities of AI music generators, paving the way for deep learning and Natural Language Processing (NLP) to play pivotal roles in this tech. OpenAI's GPT series and almost all other LLMs currently are powered by transformers utilizing either encoder, decoder, or both architectures.
Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for natural language processing (NLP) tasks. This allows the model to learn long-range dependencies between words, which is essential for many NLP tasks, such as machine translation and text summarization.
Models like OpenAI’s ChatGPT and Google Bard require enormous volumes of resources, including a lot of training data, substantial amounts of storage, intricate, deep learning frameworks, and enormous amounts of electricity. These versions offer flexibility in terms of applications, ranging from Mini with 4.4
In the last few years, if you google healthcare or clinical NLP, you would see that the search results are blanketed by a few names like John Snow Labs (JSL), Linguamatics (IQVIA), Oncoustics, BotMD, Inspirata. Soon to be followed by large general language models like BERT (Bidirectional Encoder Representations from Transformers).
Starting from the field of Natural Language Processing (NLP), Transformers have been revolutionizing nearly all areas of applied AI, due to their efficiency at processing large chunks of data at once ( parallelization ) rather than sequentially, a feature that allowed for training on bigger datasets than previous existing architectures.
The journey continues with “NLP and Deep Learning,” diving into the essentials of Natural Language Processing , deep learning's role in NLP, and foundational concepts of neural networks. Expert Creators : Developed by renowned professionals from OpenAI and DeepLearning.AI.
And truly, there can’t be an effective RAG without an NLP library that is production-ready, natively distributed, state-of-the-art, and user-friendly. We’re excited to unveil Spark NLP 5.1 with: New OpenAI Whisper, Embeddings and Completions! New Features Spark NLP ONNX (toujours) In Spark NLP 5.1.0,
They are now capable of natural language processing ( NLP ), grasping context and exhibiting elements of creativity. Innovators who want a custom AI can pick a “foundation model” like OpenAI’s GPT-3 or BERT and feed it their data.
We are delighted to announce the release of Spark NLP 5.0, We are delighted to announce the release of Spark NLP 5.0, Additionally, we are also set to release an array of new LLM models fine-tuned specifically for chat and instruction, now that we have successfully integrated ONNX Runtime into Spark NLP.
Libraries DRAGON is a new foundation model (improvement of BERT) that is pre-trained jointly from text and knowledge graphs for improved language, knowledge and reasoning capabilities. DRAGON can be used as a drop-in replacement for BERT. OpenAI-compatible APIs: Serve APIs that are compatible with OpenAI standards.
Are you curious about the groundbreaking advancements in Natural Language Processing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. Ever wondered how machines can understand and generate human-like text?
Impact of ChatGPT on Human Skills: The rapid emergence of ChatGPT, a highly advanced conversational AI model developed by OpenAI, has generated significant interest and debate across both scientific and business communities.
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., Many fields have used fine-tuning, but OpenAI’s InstructGPT is a particularly impressive and up-to-date example. rely on Language Models as their foundation.
Original natural language processing (NLP) models were limited in their understanding of language. GPT-4 GPT-4 is OpenAI's latest (and largest) model. BERTBERT stands for Bidirectional Encoder Representations from Transformers, and it's a large language model by Google.
Natural Language Processing (NLP) is a subfield of artificial intelligence. BERT (Bidirectional Encoder Representations from Transformers) — developed by Google. RoBERTa (Robustly Optimized BERT Approach) — developed by Facebook AI. T5 (Text-to-Text Transfer Transformer) — developed by Google.
ChatGPT released by OpenAI is a versatile Natural Language Processing (NLP) system that comprehends the conversation context to provide relevant responses. Question Answering has been an active research area in NLP for many years so there are several datasets that have been created for evaluating QA systems.
News Microsoft is busy milking the ChatGPT momentum, doubling down onits partnership with OpenAI: including LMs as part of their Azure services, Teams products, and now finally, as part of its web search in Bing. For MuLan [3], they take the frozen model, and for SoundStream and w2v-BERT they use the free music archive.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
That work inspired researchers who created BERT and other large language models , making 2018 a watershed moment for natural language processing, a report on AI said at the end of that year. Google released BERT as open-source software , spawning a family of follow-ons and setting off a race to build ever larger, more powerful LLMs.
But if you’re working on the same sort of Natural Language Processing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them? However, LLMs are not a direct solution to most of the NLP use-cases companies have been working on. That’s definitely new.
Since its release on November 30, 2022 by OpenAI , the ChatGPT public demo has taken the world by storm. An Associate Professor at Maryland has estimated that OpenAI spends $3 million per month to run ChatGPT. and is trained in a manner similar to OpenAI’s earlier InstructGPT, but on conversations.
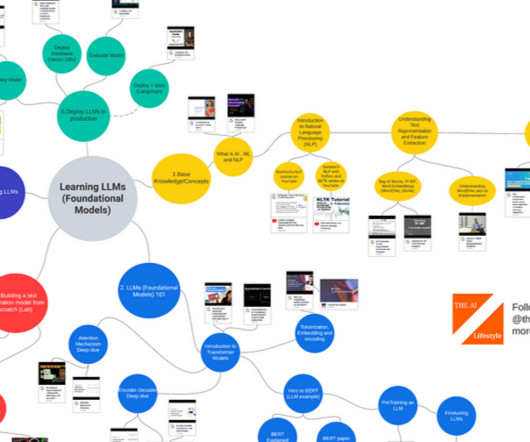
Learning LLMs (Foundational Models) Base Knowledge / Concepts: What is AI, ML and NLP Introduction to ML and AI — MFML Part 1 — YouTube What is NLP (Natural Language Processing)? — YouTube YouTube Introduction to Natural Language Processing (NLP) NLP 2012 Dan Jurafsky and Chris Manning (1.1) YouTube BERT Research — Ep.
Photo by Eugene Zhyvchik on Unsplash I wanted to share a short perspective of the radical evolution we have seen in NLP. I’ve been working on NLP problems since word2vec was released, and it has been remarkable to see how quickly the models, problems, and applications have evolved. GPT-2 released with 1.5
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content