This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this article, we are going to use BERT along with a neural […]. The post Disaster Tweet Classification using BERT & NeuralNetwork appeared first on Analytics Vidhya.
Introduction With the advancement in deep learning, neuralnetwork architectures like recurrent neuralnetworks (RNN and LSTM) and convolutional neuralnetworks (CNN) have shown. The post Transfer Learning for NLP: Fine-Tuning BERT for Text Classification appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Introduction In the past few years, Natural language processing has evolved a lot using deep neuralnetworks. Many state-of-the-art models are built on deep neuralnetworks. It […].
This article was published as a part of the Data Science Blogathon Objective In this blog, we will learn how to Fine-tune a Pre-trained BERT model for the Sentiment analysis task. The post Fine-tune BERT Model for Sentiment Analysis in Google Colab appeared first on Analytics Vidhya.
Generative AI is powered by advanced machine learning techniques, particularly deep learning and neuralnetworks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Programming Languages: Python (most widely used in AI/ML) R, Java, or C++ (optional but useful) 2.
Surprising no one, Python tops the charts as the most popular language in the zeitgeist and among IEEE members. It should be noted that just knowing SQL is not enough, and it must be paired with a more traditional programming language like Python or C++.
These gargantuan neuralnetworks have revolutionized how machines learn and generate human language, propelling the boundaries of what was once thought possible.
Project Structure Accelerating Convolutional NeuralNetworks Parsing Command Line Arguments and Running a Model Evaluating Convolutional NeuralNetworks Accelerating Vision Transformers Evaluating Vision Transformers Accelerating BERT Evaluating BERT Miscellaneous Summary Citation Information What’s New in PyTorch 2.0?
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
Summary: Neuralnetworks are a key technique in Machine Learning, inspired by the human brain. Different types of neuralnetworks, such as feedforward, convolutional, and recurrent networks, are designed for specific tasks like image recognition, Natural Language Processing, and sequence modelling.
NeuralNetworks & Deep Learning : Neuralnetworks marked a turning point, mimicking human brain functions and evolving through experience. Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. At its core, Deepnote AI aims to augment the workflow of data scientists.
Tools like Python , R , and SQL were mainstays, with sessions centered around data wrangling, business intelligence, and the growing role of data scientists in decision-making. By 2017, deep learning began to make waves, driven by breakthroughs in neuralnetworks and the release of frameworks like TensorFlow.
Natural Language Processing Transformers, the neuralnetwork architecture, that has taken the world of natural language processing (NLP) by storm, is a class of models that can be used for both language and image processing. We will also discuss the pros and cons of Transformers, along with practical examples in Python.
The journey continues with “NLP and Deep Learning,” diving into the essentials of Natural Language Processing , deep learning's role in NLP, and foundational concepts of neuralnetworks. Versatile Toolset Exposure : Including Python, Java, TensorFlow, and Keras.
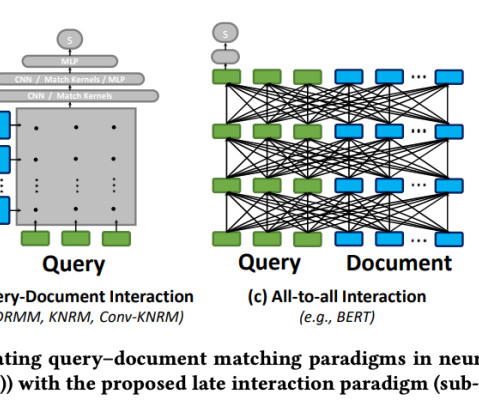
The reranking model, often a neuralnetwork or a transformer-based architecture, is specifically trained to assess the relevance of a document to a given query. ColBERT: Efficient and Effective Late Interaction One of the standout models in the realm of reranking is ColBERT ( Contextualized Late Interaction over BERT ).
Blog: Faster and smaller quantized NLP with Hugging Face and ONNX Runtime Popular Hugging Face Transformer models (BERT, GPT-2, etc) can be shrunk and accelerated with ONNX Runtime quantization… medium.com Talking about ONNX… Suraj Patil created this awesome repo that incorporates the ONNX script with the Hugging Face pipeline framework.
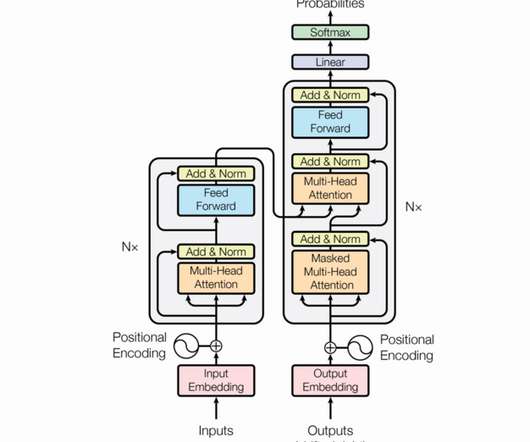
Transformers are defined as a specific type of neuralnetwork architecture that have proven to be particularly effective for sequence classification tasks, thanks to their ability to capture long-term dependencies and contextual relationships in the data. The transformer architecture was introduced by Vaswani et al.
TensorFlow is desired for its flexibility for ML and neuralnetworks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering. BERT is still very popular over the past few years and even though the last update from Google was in late 2019 it is still widely deployed.
Models such as GPT, BERT , and more recently Llama , Mistral are capable of understanding and generating human-like text with unprecedented fluency and coherence. Setup Python Virtual Environment Ubuntu 22.04 comes with Python 3.10. lib64 BNB_CUDA_VERSION=122 CUDA_VERSION=122 python setup.py import torch import torch.nn
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. Deep neuralnetworks have offered a solution, by building dense representations that transfer well between tasks. In this post we introduce our new wrapping library, spacy-transformers.
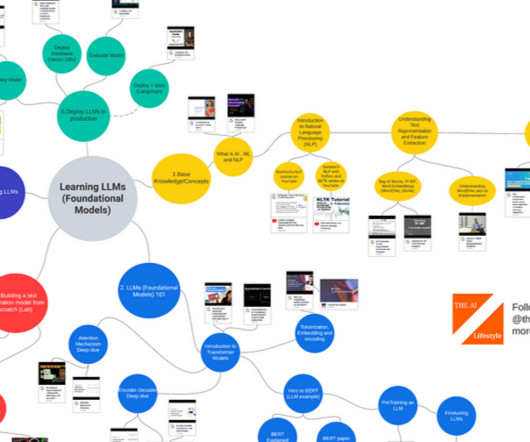
LLMs (Foundational Models) 101: Introduction to Transformer Models Transformers, explained: Understand the model behind GPT, BERT, and T5 — YouTube Illustrated Guide to Transformers NeuralNetwork: A step by step explanation — YouTube Attention Mechanism Deep dive. Transformer NeuralNetworks — EXPLAINED!
This is typically done using large language models like BERT or GPT. signed distance functions) Neural radiance fields (NeRFs) : Neuralnetworks representing density and color in 3D space Each has trade-offs in terms of resolution, memory usage, and ease of generation.
Traditional neuralnetwork models like RNNs and LSTMs and more modern transformer-based models like BERT for NER require costly fine-tuning on labeled data for every custom entity type. We extract the default generic entities through the AWS SDK for Python (Boto3) as follows: import pandas as pd comprehend_client = boto3.client("comprehend")
In the following example figure, we show INT8 inference performance in C6i for a BERT-base model. The BERT-base was fine-tuned with SQuAD v1.1, Use the supplied Python scripts for quantization. Run the provided Python test scripts to invoke the SageMaker endpoint for both INT8 and FP32 versions. 2xLarge-FP32 70 110.8
How It Works TensorRT-LLM speeds up inference by optimizing neuralnetworks during deployment using techniques like: Quantization : Reduces the precision of weights and activations, shrinking model size and improving inference speed. Weight Bindings Before compiling the model, the weights (or parameters) must be bound to the network.
Techniques like Word2Vec and BERT create embedding models which can be reused. Word2Vec pioneered the use of shallow neuralnetworks to learn embeddings by predicting neighboring words. BERT produces deep contextual embeddings by masking words and predicting them based on bidirectional context.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
It uses BERT, a popular NLP technique, to understand the meaning and context of words in the candidate summary and reference summary. The more similar the words and meanings captured by BERT, the higher the BERTScore. It uses neuralnetworks like BERT to measure semantic similarity beyond just exact word or phrase matching.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! Deep learning refers to the use of neuralnetwork architectures, characterized by their multi-layer design (i.e. Editor’s note: Benjamin Batorsky, PhD is a speaker for ODSC East 2023. deep” architecture). Follow along in the notebook !
In this blog, we’ll explore the concept of transfer learning, how it technically works, and provide a step-by-step guide to implementing it in Python. As the name suggests, this technique involves transferring the learnings of one trained machine learning model to another, in the form of neuralnetwork weights.
This workshop will introduce you to the fundamentals of PySpark (Spark’s Python API), the Spark NLP library, and other best practices in Spark programming when working with textual or natural language data. In recent years, text data is increasingly becoming more common as new techniques to work with them become popular.
If you have been spending a lot of time with ChatGPT, you my want to take a look at the awesome prompts: [link] You can open full-fledged terminal, write Python, JS in various terminals and then debug your code further. There is a good notebook that you can take a look at the approach in Python. SELECT date.fromtimestamp(.purchase_ts)
TensorFlow is an open-source software library for AI and machine learning with deep neuralnetworks. TensorFlow Lite also optimizes the trained model using quantization techniques (discussed later in this article), which consequently reduces the necessary memory usage as well as the computational cost of utilizing neuralnetworks.
The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment. All of this made it easy for researchers and practitioners to use BERT.
The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment. All of this made it easy for researchers and practitioners to use BERT.
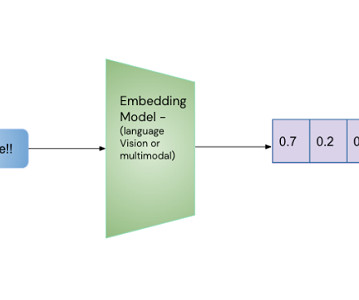
Using Embeddings to Detect Anomalies Figure 1: Using a trained deep neuralnetwork, it is possible to convert unstructured data to numeric representations, i.e., embeddings Embeddings are numerical representations generated from unstructured data like images, text, and audio, and greatly influence machine learning approaches for handling such data.
RoBERTa RoBERTa (Robustly Optimized BERT Approach) is a natural language processing (NLP) model based on the BERT (Bidirectional Encoder Representations from Transformers) architecture. This refers to the fact that BERT was pre-trained on one set of tasks but fine-tuned on a different set of tasks for downstream NLP applications.
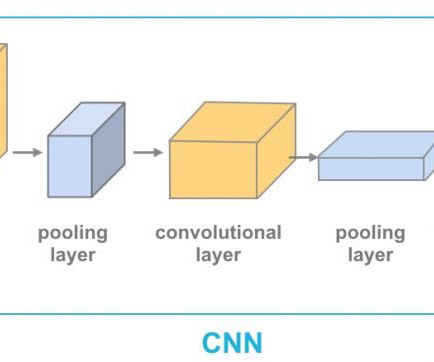
Object detection systems typically use frameworks like Convolutional NeuralNetworks (CNNs) and Region-based CNNs (R-CNNs). Concept of Convolutional NeuralNetworks (CNN) However, in prompt object detection systems, users dynamically direct the model with many tasks it may not have encountered before.
When running this notebook on Studio, you should make sure the Python 3 (PyTorch 1.10 BERT + Random Forest. BERT + Random Forest. BERT + Random Forest with HPO. Fuse multiple neuralnetwork models directly and handle raw text (which are also capable of handling additional numerical and categorical columns).
A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings. Images can be embedded using models such as convolutional neuralnetworks (CNNs) , Examples of CNNs include VGG , and Inception. using its Spectrogram ).
Once complete, you’ll know all about machine learning, statistics, neuralnetworks, and data mining. Machine Learning with Python: A Practical Introduction Author: Saeed Aghabozorgi Ph.D. According to GitHub , Python is the most popular programming language used in machine learning.
Transformer-based models, such as Bidirectional Encoder Representations from Transformers (BERT), have revolutionized NLP by offering accuracy comparable to human baselines on benchmarks like SQuAD for question-answer, entity recognition, intent recognition, sentiment analysis, and more. Basic understanding of neuralnetworks.
Recent advancements in ML (specifically the invention of the transformer-based neuralnetwork architecture) have led to the rise of models that contain billions of parameters or variables. medium 2vCPU+4GiB notebook instance with a Python 3 kernel. We use an ml.t3.medium pip install nest-asyncio==1.5.5 --quiet !pip
Blog: Faster and smaller quantized NLP with Hugging Face and ONNX Runtime Popular Hugging Face Transformer models (BERT, GPT-2, etc) can be shrunk and accelerated with ONNX Runtime quantization… medium.com Talking about ONNX… Suraj Patil created this awesome repo that incorporates the ONNX script with the Hugging Face pipeline framework.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content