This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Recurrent NeuralNetworks (RNNs) became the cornerstone for these applications due to their ability to handle sequential data by maintaining a form of memory. Functionality : Each encoder layer has self-attention mechanisms and feed-forward neuralnetworks. However, RNNs were not without limitations.
Examples of Generative AI: Text Generation: Models like OpenAIs GPT-4 can generate human-like text for chatbots, content creation, and more. Music Generation: AI models like OpenAIs Jukebox can compose original music in various styles. GPT, BERT) Image Generation (e.g., Study neuralnetworks, including CNNs, RNNs, and LSTMs.
It includes deciphering neuralnetwork layers , feature extraction methods, and decision-making pathways. These systems rely heavily on neuralnetworks to process vast amounts of information. During training, neuralnetworks learn patterns from extensive datasets.
LLMs are deep neuralnetworks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP).
These architectures are based on artificial neuralnetworks , which are computational models loosely inspired by the structure and functioning of biological neuralnetworks, such as those in the human brain. A simple artificial neuralnetwork consisting of three layers.
Normalization Trade-off: GPT models preserve formatting & nuance (more token complexity); BERT aggressively cleans text simpler tokens, reduced nuance, ideal for structured tasks. GPT typically preserves contractions, BERT-based models may split. Tokens: Fundamental unit that neuralnetworks process. GPT-4 and GPT-3.5
Project Structure Accelerating Convolutional NeuralNetworks Parsing Command Line Arguments and Running a Model Evaluating Convolutional NeuralNetworks Accelerating Vision Transformers Evaluating Vision Transformers Accelerating BERT Evaluating BERT Miscellaneous Summary Citation Information What’s New in PyTorch 2.0?
OpenAI has been instrumental in developing revolutionary tools like the OpenAI Gym, designed for training reinforcement algorithms, and GPT-n models. One such model that has garnered considerable attention is OpenAI's ChatGPT , a shining exemplar in the realm of Large Language Models. Imagine you have an image of a cat.
This is typically done using large language models like BERT or GPT. signed distance functions) Neural radiance fields (NeRFs) : Neuralnetworks representing density and color in 3D space Each has trade-offs in terms of resolution, memory usage, and ease of generation. This stage takes approximately 20 seconds.
GPT 3 and similar Large Language Models (LLM) , such as BERT , famous for its bidirectional context understanding, T-5 with its text-to-text approach, and XLNet , which combines autoregressive and autoencoding models, have all played pivotal roles in transforming the Natural Language Processing (NLP) paradigm.
NeuralNetworks & Deep Learning : Neuralnetworks marked a turning point, mimicking human brain functions and evolving through experience. Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. Below is a demonstration of the BabyAGI using this link.
They said transformer models , large language models (LLMs), vision language models (VLMs) and other neuralnetworks still being built are part of an important new category they dubbed foundation models. Earlier neuralnetworks were narrowly tuned for specific tasks.
These tools, such as OpenAI's DALL-E , Google's Bard chatbot , and Microsoft's Azure OpenAI Service , empower users to generate content that resembles existing data. OpenAI's GPT-4 stands as a state-of-the-art generative language model, boasting an impressive over 1.7
AI models like neuralnetworks , used in applications like Natural Language Processing (NLP) and computer vision , are notorious for their high computational demands. Models like GPT and BERT involve millions to billions of parameters, leading to significant processing time and energy consumption during training and inference.
The development of LLMs, such as OpenAI’s GPT series, Google’s Gemini, Anthropic AI’s Claude, and Meta’s Llama models, marks a significant advancement in natural language processing. Parameters (like weights in neuralnetworks) are adjusted during training to reduce the difference between predicted and actual output.
Models like OpenAI’s ChatGPT and Google Bard require enormous volumes of resources, including a lot of training data, substantial amounts of storage, intricate, deep learning frameworks, and enormous amounts of electricity. These versions offer flexibility in terms of applications, ranging from Mini with 4.4
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
The journey continues with “NLP and Deep Learning,” diving into the essentials of Natural Language Processing , deep learning's role in NLP, and foundational concepts of neuralnetworks. Expert Creators : Developed by renowned professionals from OpenAI and DeepLearning.AI.
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. in 2017, marking a departure from the previous reliance on recurrent neuralnetworks (RNNs) and convolutional neuralnetworks (CNNs) for processing sequential data.
Early neuralnetworks like AlexNet and ResNet demonstrated how increasing model size could improve image recognition. Then came transformers where models like GPT-3 and Googles BERT have showed that scaling could unlock entirely new capabilities, such as few-shot learning. This recipe has driven AIs evolution for over a decade.
Current methods in the field include keyword-based search engines and advanced neuralnetwork models like BERT and GPT. employs a variety of models, including Ollama’s Llama3, HuggingFace’s MiniLMEmbedder, Cohere’s Command R+, Google’s Gemini, and OpenAI’s GPT-4. Check out the release video!
It employs artificial neuralnetworks with multiple layershence the term deepto model intricate patterns in data. Each layer in a neuralnetwork extracts progressively abstract features from the data, enabling these models to understand and process complex patterns.
Created Using Midjourney Next Week in The Sequence: Edge 451: Explores the ideas behind multi-teacher distillation including the MT-BERT paper. The system leverages a recurrent, transformer-based neuralnetwork architecture inspired by the successful use of Transformers in large language models (LLMs).
Transformers, BERT, and GPT The transformer architecture is a neuralnetwork architecture that is used for natural language processing (NLP) tasks. BERT is trained on sequences where some of the words in a sentence are masked, and it has to fill in those words taking into account both the words before and after the masked words.
They use neuralnetworks that are inspired by the structure and function of the human brain. GPT-4 GPT-4 is OpenAI's latest (and largest) model. BERTBERT stands for Bidirectional Encoder Representations from Transformers, and it's a large language model by Google. How Do Large Language Models Work?
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
Unigrams, N-grams, exponential, and neuralnetworks are valid forms for the Language Model. Many fields have used fine-tuning, but OpenAI’s InstructGPT is a particularly impressive and up-to-date example. rely on Language Models as their foundation. It is pre-trained using a generalized autoregressive model.
LLMs (Foundational Models) 101: Introduction to Transformer Models Transformers, explained: Understand the model behind GPT, BERT, and T5 — YouTube Illustrated Guide to Transformers NeuralNetwork: A step by step explanation — YouTube Attention Mechanism Deep dive. Transformer NeuralNetworks — EXPLAINED!
Working of Large Language Models (LLMs) Deep neuralnetworks are used in Large language models to produce results based on patterns discovered from training data. BERT (Bidirectional Encoder Representations from Transformers) — developed by Google. RoBERTa (Robustly Optimized BERT Approach) — developed by Facebook AI.
At their core, LLMs are built upon deep neuralnetworks, enabling them to process vast amounts of text and learn complex patterns. In this section, we will provide an overview of two widely recognized LLMs, BERT and GPT, and introduce other notable models like T5, Pythia, Dolly, Bloom, Falcon, StarCoder, Orca, LLAMA, and Vicuna.
Model architectures that qualify as “supervised learning”—from traditional regression models to random forests to most neuralnetworks—require labeled data for training. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
With the release of the latest chatbot developed by OpenAI called ChatGPT, the field of AI has taken over the world as ChatGPT, due to its GPT’s transformer architecture, is always in the headlines. The underlying architecture of LLMs typically involves a deep neuralnetwork with multiple layers.
A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings. Images can be embedded using models such as convolutional neuralnetworks (CNNs) , Examples of CNNs include VGG , and Inception. using its Spectrogram ).
Major milestones in the last few years comprised BERT (Google, 2018), GPT-3 (OpenAI, 2020), Dall-E (OpenAI, 2021), Stable Diffusion (Stability AI, LMU Munich, 2022), ChatGPT (OpenAI, 2022). Complex ML problems can only be solved in neuralnetworks with many layers. Deep learning neuralnetwork.
As the name suggests, this technique involves transferring the learnings of one trained machine learning model to another, in the form of neuralnetwork weights. But, there are open source models like German-BERT that are already trained on huge data corpora, with many parameters. Book a demo to learn more.
The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment. All of this made it easy for researchers and practitioners to use BERT.
The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment. All of this made it easy for researchers and practitioners to use BERT.
Emergence and History of LLMs Artificial NeuralNetworks (ANNs) and Rule-based Models The foundation of these Computational Linguistics models (CL) dates back to the 1940s when Warren McCulloch and Walter Pitts laid the groundwork for AI. However, the first actual language model was a rule-based model developed in the 1950s.
The 1970s introduced bell bottoms, case grammars, semantic networks, and conceptual dependency theory. In the 90’s we got grunge, statistical models, recurrent neuralnetworks and long short-term memory models (LSTM). It uses a neuralnetwork to learn the vector representations of words from a large corpus of text.
Models like GPT 4, BERT, DALL-E 3, CLIP, Sora, etc., Use Cases for Foundation Models Applications in Pre-trained Language Models like GPT, BERT, Claude, etc. Foundation models are large-scale neuralnetwork architectures that undergo pre-training on vast amounts of unlabeled data through self-supervised learning.
Before going further, a new announcement for embeddings also came from OpenAI: openai.com/blog/new-and-i… nnIt is cross-modal, and it is 1/500th of the price of the old embedding model DaVinci. ","username":"bugraa","name":"Bugra Dragon can be used as a drop-in replacement for BERT.
These models, powered by massive neuralnetworks, have catalyzed groundbreaking advancements in natural language processing (NLP) and have reshaped the landscape of machine learning. CLIP (Contrastive Language-Image Pre-training) : CLIP, developed by OpenAI, is a multi-modal model that can understand images and text.
Large Language Models – Source In 2018, OpenAI researchers and engineers published an original work on AI-based generative large language models. GPT models are based on transformer-based deep learning neuralnetwork architecture. GPT-2 is not just a language model like BERT, it can also generate text.
In technical terms, this component is made up of a UNet neuralnetwork and a scheduling algorithm. With this we come to see the three main components (each with its own neuralnetwork) that make up Stable Diffusion: ClipText for text encoding. We’ll talk more about what that means later in the post. Input: text.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































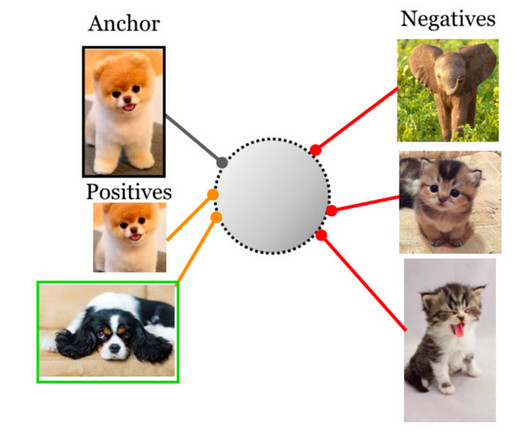

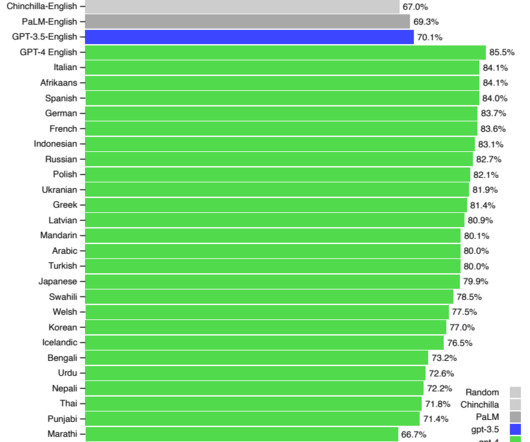







Let's personalize your content