This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon Introduction In the past few years, Naturallanguageprocessing has evolved a lot using deep neuralnetworks. Many state-of-the-art models are built on deep neuralnetworks. It […].
Introduction With the advancement in deep learning, neuralnetwork architectures like recurrent neuralnetworks (RNN and LSTM) and convolutional neuralnetworks (CNN) have shown. The post Transfer Learning for NLP: Fine-Tuning BERT for Text Classification appeared first on Analytics Vidhya.
NaturalLanguageProcessing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. Recurrent NeuralNetworks (RNNs) became the cornerstone for these applications due to their ability to handle sequential data by maintaining a form of memory.
Bridging the Gap with NaturalLanguageProcessingNaturalLanguageProcessing (NLP) stands at the forefront of bridging the gap between human language and AI comprehension. NLP enables machines to understand, interpret, and respond to human language in a meaningful way.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deep learning model designed explicitly for naturallanguageprocessing tasks like answering questions, analyzing sentiment, and translation.
Photo by david clarke on Unsplash The most recent breakthroughs in language models have been the use of neuralnetwork architectures to represent text. There is very little contention that large language models have evolved very rapidly since 2018. Both BERT and GPT are based on the Transformer architecture.
This advancement has spurred the commercial use of generative AI in naturallanguageprocessing (NLP) and computer vision, enabling automated and intelligent data extraction. The encoder processes input data, condensing essential features into a “Context Vector.”
NeuralNetwork: Moving from Machine Learning to Deep Learning & Beyond Neuralnetwork (NN) models are far more complicated than traditional Machine Learning models. Advances in neuralnetwork techniques have formed the basis for transitioning from machine learning to deep learning.
The core process is a general technique known as self-supervised learning , a learning paradigm that leverages the inherent structure of the data itself to generate labels for training. This concept is not exclusive to naturallanguageprocessing, and has also been employed in other domains.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
But more than MLOps is needed for a new type of ML model called Large Language Models (LLMs). LLMs are deep neuralnetworks that can generate naturallanguage texts for various purposes, such as answering questions, summarizing documents, or writing code.
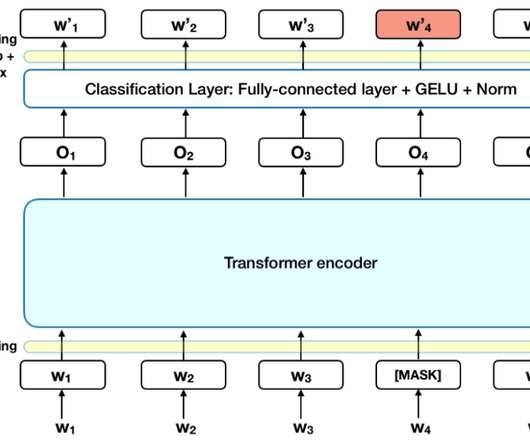
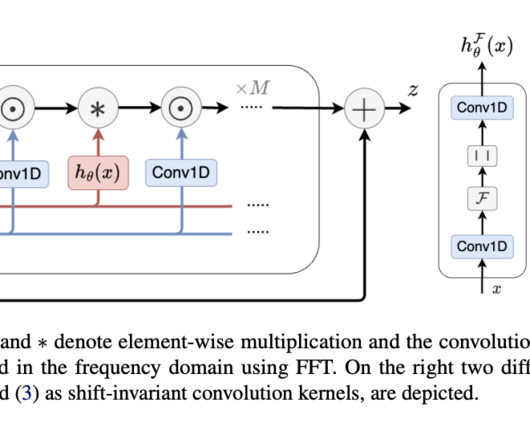
However, the computational complexity associated with these mechanisms scales quadratically with sequence length, which becomes a significant bottleneck when managing long-context tasks such as genomics and naturallanguageprocessing. Compared to the BERT-base, the Orchid-BERT-base has 30% fewer parameters yet achieves a 1.0-point
Project Structure Accelerating Convolutional NeuralNetworks Parsing Command Line Arguments and Running a Model Evaluating Convolutional NeuralNetworks Accelerating Vision Transformers Evaluating Vision Transformers Accelerating BERT Evaluating BERT Miscellaneous Summary Citation Information What’s New in PyTorch 2.0?
Transformer Models and BERT Model : In this course, participants delve into the specifics of Transformer models and the Bidirectional Encoder Representations from Transformers (BERT) model. This course is ideal for those interested in the latest in naturallanguageprocessing technologies.
Summary: Neuralnetworks are a key technique in Machine Learning, inspired by the human brain. Different types of neuralnetworks, such as feedforward, convolutional, and recurrent networks, are designed for specific tasks like image recognition, NaturalLanguageProcessing, and sequence modelling.
A Deep NeuralNetwork (DNN) is an artificial neuralnetwork that features multiple layers of interconnected nodes, also known as neurons. Each neuron processes input data by applying weights, biases, and an activation function to generate an output. These layers include an input, multiple hidden, and output layers.
GPT 3 and similar Large Language Models (LLM) , such as BERT , famous for its bidirectional context understanding, T-5 with its text-to-text approach, and XLNet , which combines autoregressive and autoencoding models, have all played pivotal roles in transforming the NaturalLanguageProcessing (NLP) paradigm.
Self Supervised Learning models build representations of the training data using human annotated labels, and it’s one of the major reasons behind the advancement of the NLP or NaturalLanguageProcessing , and the Computer Vision technology.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. NaturalLanguageProcessing on Google Cloud This course introduces Google Cloud products and solutions for solving NLP problems.
These limitations are particularly significant in fields like medical imaging, autonomous driving, and naturallanguageprocessing, where understanding complex patterns is essential. It employs artificial neuralnetworks with multiple layershence the term deepto model intricate patterns in data.
AI models like neuralnetworks , used in applications like NaturalLanguageProcessing (NLP) and computer vision , are notorious for their high computational demands. Computer vision tasks rely heavily on matrix operations and have also used sub-quadratic techniques to streamline convolutional processes.
Summary: Recurrent NeuralNetworks (RNNs) are specialised neuralnetworks designed for processing sequential data by maintaining memory of previous inputs. They excel in naturallanguageprocessing, speech recognition, and time series forecasting applications.
The 1970s introduced bell bottoms, case grammars, semantic networks, and conceptual dependency theory. In the 90’s we got grunge, statistical models, recurrent neuralnetworks and long short-term memory models (LSTM). It uses a neuralnetwork to learn the vector representations of words from a large corpus of text.
They use deep learning techniques to process and produce language in a contextually relevant manner. The development of LLMs, such as OpenAI’s GPT series, Google’s Gemini, Anthropic AI’s Claude, and Meta’s Llama models, marks a significant advancement in naturallanguageprocessing.
These adapters allow BERT to be fine-tuned for specific downstream tasks while retaining most of its pre-trained parameters. These adapters allow BERT to be fine-tuned for specific downstream tasks while retaining most of its pre-trained parameters.
In modern machine learning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in NaturalLanguageProcessing, and Vision Transformers in computer vision tasks.
Large Language Models (LLMs), like GPT, PaLM, LLaMA, etc., Their ability to utilize the strength of NaturalLanguageProcessing, Generation, and Understanding by generating content, answering questions, summarizing text, and so on have made LLMs the talk of the town in the last few months.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (NaturalLanguageProcessing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
When it comes to naturallanguageprocessing (NLP) and information retrieval, the ability to efficiently and accurately retrieve relevant information is paramount. The reranking model, often a neuralnetwork or a transformer-based architecture, is specifically trained to assess the relevance of a document to a given query.
Figure 1: adversarial examples in computer vision (left) and naturallanguageprocessing tasks (right). With that said, the path to machine commonsense is unlikely to be brute force training larger neuralnetworks with deeper layers. Is commonsense knowledge already captured by pre-trained language models?
Large Language Models (LLMs) have revolutionized naturallanguageprocessing, demonstrating remarkable capabilities in various applications. Transformer architecture has emerged as a major leap in naturallanguageprocessing, significantly outperforming earlier recurrent neuralnetworks.
Applications for naturallanguageprocessing (NLP) have exploded in the past decade. Modern techniques can capture the nuance, context, and sophistication of language, just as humans do. Basic understanding of neuralnetworks.
Ivan Aivazovsky — Istanbul NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 09.06.20 Part 1 – Introduction to Graph NeuralNetworks with GatedGCN Graph Representation Learning is the task of effectively summarizing the structure of a graph in a low dimensional… app.wandb.ai
Artificial Intelligence is a very vast branch in itself with numerous subfields including deep learning, computer vision , naturallanguageprocessing , and more. The neuralnetwork consists of three types of layers including the hidden layer, the input payer, and the output layer.
NaturalLanguageProcessing Transformers, the neuralnetwork architecture, that has taken the world of naturallanguageprocessing (NLP) by storm, is a class of models that can be used for both language and image processing. Not this Transformers!! ?
The well-known Large Language Models (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in NaturalLanguageProcessing (NLP) and NaturalLanguage Generation (NLG). LLMs are becoming increasingly popular for graph-based applications.
A foundation model is built on a neuralnetwork model architecture to process information much like the human brain does. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. An open-source model, Google created BERT in 2018.
Consequently, there’s been a notable uptick in research within the naturallanguageprocessing (NLP) community, specifically targeting interpretability in language models, yielding fresh insights into their internal operations. Recent approaches automate circuit discovery, enhancing interpretability.
Naturallanguageprocessing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. BERT even accounts for the context of words, allowing for more accurate results related to respective queries and tasks.
With advancements in deep learning, naturallanguageprocessing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. NeuralNetworks & Deep Learning : Neuralnetworks marked a turning point, mimicking human brain functions and evolving through experience.
Pixabay: by Activedia Image captioning combines naturallanguageprocessing and computer vision to generate image textual descriptions automatically. This process involves utilizing various NLP models and techniques to develop textual descriptions. Various algorithms are employed in image captioning, including: 1.
Transformers have revolutionized naturallanguageprocessing (NLP), powering models like GPT and BERT. The goal was to see if I could accurately identify these digits using a Transformer-based approach, which feels quite different from the traditional Convolutional NeuralNetwork (CNN) methods I was more familiar with.
Naturallanguageprocessing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., rely on Language Models as their foundation. Unigrams, N-grams, exponential, and neuralnetworks are valid forms for the Language Model.
Transformers, BERT, and GPT The transformer architecture is a neuralnetwork architecture that is used for naturallanguageprocessing (NLP) tasks. BERT can be fine-tuned for a variety of NLP tasks, including question answering, naturallanguage inference, and sentiment analysis.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content