This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
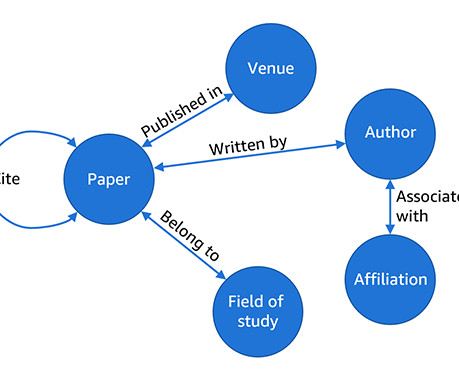
The ability to effectively represent and reason about these intricate relational structures is crucial for enabling advancements in fields like network science, cheminformatics, and recommender systems. Graph NeuralNetworks (GNNs) have emerged as a powerful deep learning framework for graph machine learning tasks.
Generative AI is powered by advanced machine learning techniques, particularly deep learning and neuralnetworks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Programming Languages: Python (most widely used in AI/ML) R, Java, or C++ (optional but useful) 2.
AI and ML are expanding at a remarkable rate, which is marked by the evolution of numerous specialized subdomains. introduced the concept of Generative Adversarial Networks (GANs) , where two neuralnetworks, i.e., the generator and the discriminator, are trained simultaneously. Dont Forget to join our 65k+ ML SubReddit.
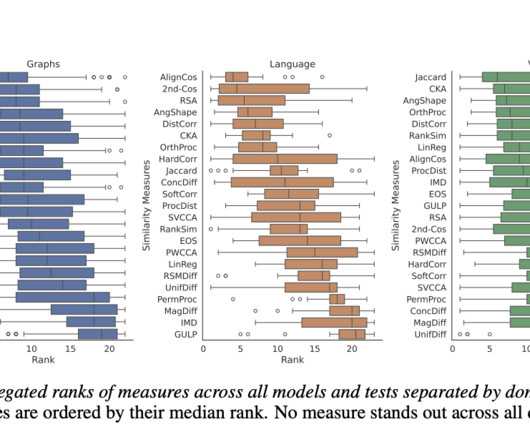
Representational similarity measures are essential tools in machine learning, used to compare internal representations of neuralnetworks. These measures help researchers understand learning dynamics, model behaviors, and performance by providing insights into how different neuralnetwork layers and architectures process information.
With these advancements, it’s natural to wonder: Are we approaching the end of traditional machine learning (ML)? The two main types of traditional ML algorithms are supervised and unsupervised. Data Preprocessing and Feature Engineering: Traditional ML requires extensive preprocessing to transform datasets as per model requirements.
Machine learning (ML) is a powerful technology that can solve complex problems and deliver customer value. However, ML models are challenging to develop and deploy. MLOps are practices that automate and simplify ML workflows and deployments. MLOps make ML models faster, safer, and more reliable in production.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
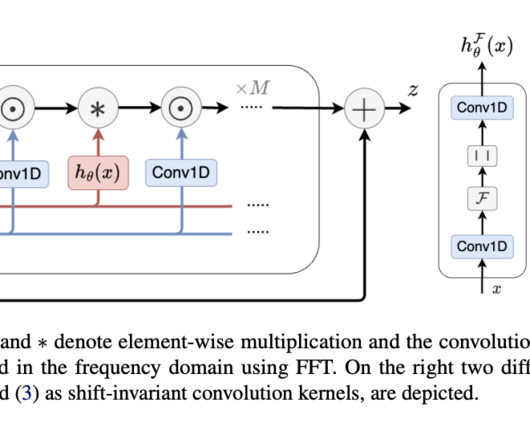
By leveraging a new data-dependent convolution layer, Orchid dynamically adjusts its kernel based on the input data using a conditioning neuralnetwork, allowing it to handle sequence lengths up to 131K efficiently. Compared to the BERT-base, the Orchid-BERT-base has 30% fewer parameters yet achieves a 1.0-point
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. It helps data scientists, AI developers, and ML engineers enhance their skills through engaging learning experiences and practical exercises.
BERT is a state-of-the-art algorithm designed by Google to process text data and convert it into vectors ([link]. What makes BERT special is, apart from its good results, the fact that it is trained over billions of records and that Hugging Face provides already a good battery of pre-trained models we can use for different ML tasks.
GraphStorm is a low-code enterprise graph machine learning (GML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. introduces refactored graph ML pipeline APIs. Based on customer feedback for the experimental APIs we released in GraphStorm 0.2, GraphStorm 0.3
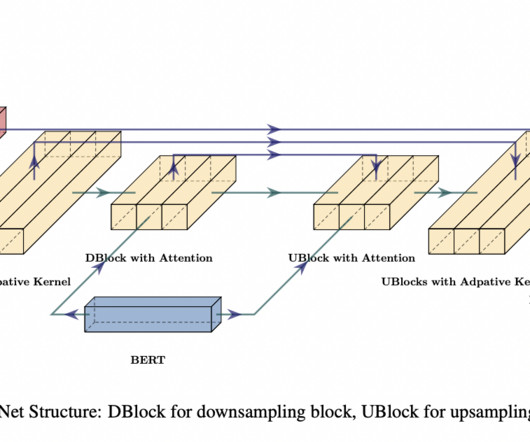
This model consists of two primary modules: A pre-trained BERT model is employed to extract pertinent information from the input text, and A diffusion UNet model processes the output from BERT. It is built upon a pre-trained BERT model. The BERT model takes subword input, and its output is processed by a 1D U-Net structure.
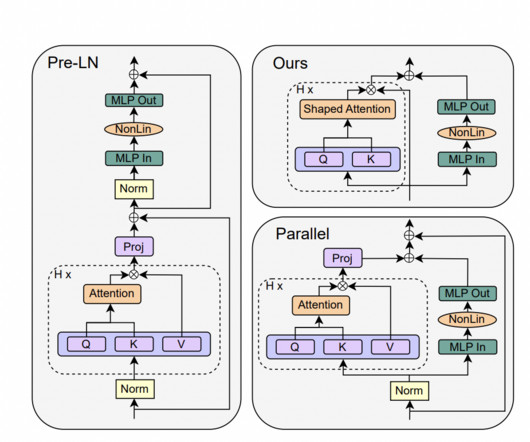
The research presents a study on simplifying transformer blocks in deep neuralnetworks, specifically focusing on the standard transformer block. The study examines the simplification of transformer blocks in deep neuralnetworks, focusing specifically on the standard transformer block. Check out the Paper.
Scientists hope that the data2vec algorithm will allow them to develop more adaptable AI and ML models that are capable of performing highly advanced tasks beyond what today’s AI models can do. Here is how the data2vec model parameterizes the teacher mode to predict the network representations that then serve as targets.
Exploring the Techniques of LIME and SHAP Interpretability in machine learning (ML) and deep learning (DL) models helps us see into opaque inner workings of these advanced models. SHAP ( Source ) Both LIME and SHAP have emerged as essential tools in the realm of AI and ML, addressing the critical need for transparency and trustworthiness.
The Boom of Generative AI and Large Language Models(LLMs) 20182020: NLP was gaining traction, with a focus on word embeddings, BERT, and sentiment analysis. 20212024: Interest declined as deep learning and pre-trained models took over, automating many tasks previously handled by classical ML techniques.
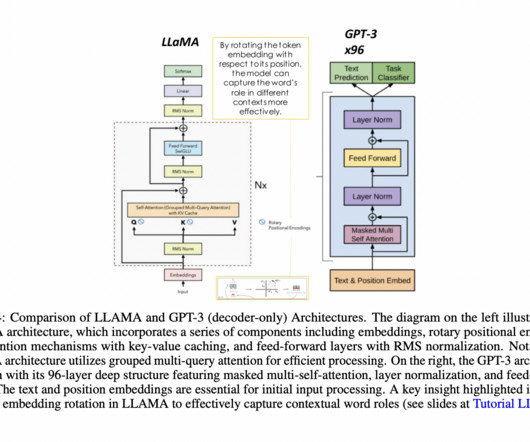
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
a low-code enterprise graph machine learning (ML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. With GraphStorm, we release the tools that Amazon uses internally to bring large-scale graph ML solutions to production. license on GitHub. GraphStorm 0.1
These adapters allow BERT to be fine-tuned for specific downstream tasks while retaining most of its pre-trained parameters. These adapters allow BERT to be fine-tuned for specific downstream tasks while retaining most of its pre-trained parameters. Also, don’t forget to follow us on Twitter.
Natural Language Processing Transformers, the neuralnetwork architecture, that has taken the world of natural language processing (NLP) by storm, is a class of models that can be used for both language and image processing. One of the earliest representation models used in NLP was the Bag of Words (BoW) model.
In this article, we’ll look at the evolution of these state-of-the-art (SOTA) models and algorithms, the ML techniques behind them, the people who envisioned them, and the papers that introduced them. The birth of Neuralnetworks was initiated with an approach akin to structuring solving problems with algorithms modeled after the human brain.
To support overarching pharmacovigilance activities, our pharmaceutical customers want to use the power of machine learning (ML) to automate the adverse event detection from various data sources, such as social media feeds, phone calls, emails, and handwritten notes, and trigger appropriate actions.
In the last 10 years, AI and ML models have become bigger and more sophisticated — they’re deeper, more complex, with more parameters, and trained on much more data, resulting in some of the most transformative outcomes in the history of machine learning.
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
Case studies from five cities demonstrate reductions in carbon emissions and improvements in quality of life metrics." }, { "id": 6, "title": "NeuralNetworks for Computer Vision", "abstract": "Convolutional neuralnetworks have revolutionized computer vision tasks. Dont Forget to join our 85k+ ML SubReddit.
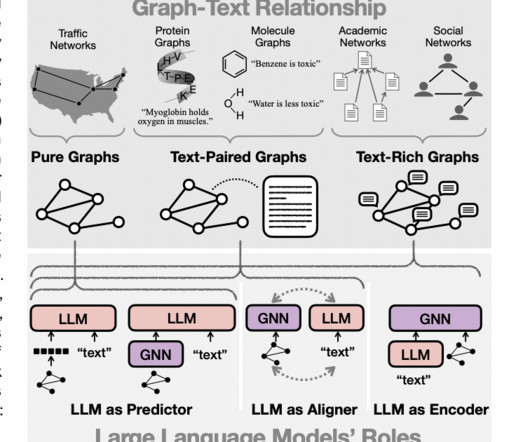
The well-known Large Language Models (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in Natural Language Processing (NLP) and Natural Language Generation (NLG). Three types of graph-based applications, i.e., pure graphs, text-rich graphs, and text-paired graphs, have been associated with the integration of LLMs.
TensorFlow is desired for its flexibility for ML and neuralnetworks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering. BERT is still very popular over the past few years and even though the last update from Google was in late 2019 it is still widely deployed.
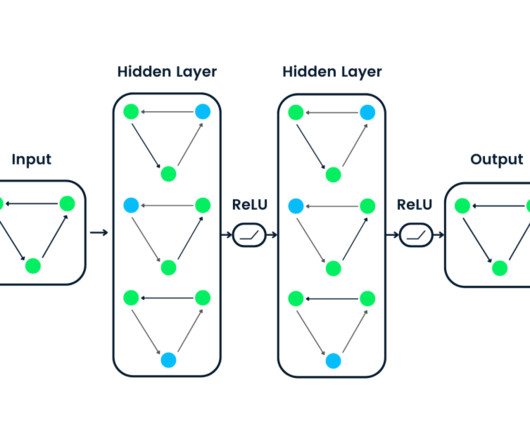
It employs artificial neuralnetworks with multiple layershence the term deepto model intricate patterns in data. Each layer in a neuralnetwork extracts progressively abstract features from the data, enabling these models to understand and process complex patterns. Dont Forget to join our 65k+ ML SubReddit.
Created Using Midjourney Next Week in The Sequence: Edge 451: Explores the ideas behind multi-teacher distillation including the MT-BERT paper. The system leverages a recurrent, transformer-based neuralnetwork architecture inspired by the successful use of Transformers in large language models (LLMs).
Representation learning-based approaches map images into binary Hamming space using hash functions or encode them into latent semantic spaces with deep neuralnetworks. Also,feel free to follow us on Twitter and dont forget to join our 80k+ ML SubReddit. Existing approaches tried to address multimodal retrieval challenges.
Great machine learning (ML) research requires great systems. In this post, we provide an overview of the numerous advances made across Google this past year in systems for ML that enable us to support the serving and training of complex models while easing the complexity of implementation for end users.
Transformer architecture has emerged as a major leap in natural language processing, significantly outperforming earlier recurrent neuralnetworks. Transformers consist of encoder and decoder components, each comprising multiple layers with self-attention mechanisms and feed-forward neuralnetworks.
Transformers are defined as a specific type of neuralnetwork architecture that have proven to be particularly effective for sequence classification tasks, thanks to their ability to capture long-term dependencies and contextual relationships in the data. The transformer architecture was introduced by Vaswani et al.
Traditional text-to-SQL systems using deep neuralnetworks and human engineering have succeeded. Using long short-term memory (LSTM) and transformer deep neuralnetworks, among others, enhanced the ability to generate SQL queries from plain English. Also, don’t forget to follow us on Twitter.
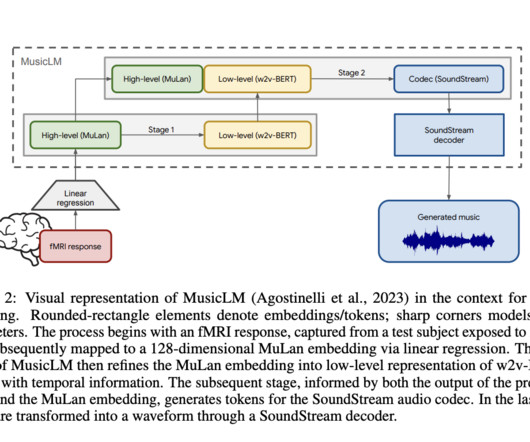
Researchers at Google and Osaka University use deep neuralnetworks to generate music from features like fMRI scans by predicting high-level, semantically structured music. The music-generating model MusicLM consists of audio-derived embeddings named MuLan and w2v-BERT- avg. Check out the Paper and Project Page.
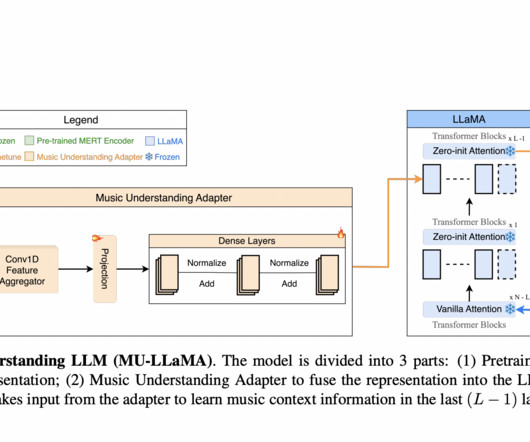
After that, these embeddings are processed by a thick neuralnetwork with three sub-blocks and a 1D convolutional layer. link] BLEU, METEOR, ROUGE-L, and BERT-Score are the main text generation measures used to assess MU-LLaMA’s performance. Check out the Paper and Github. Also, don’t forget to follow us on Twitter.
While earlier surveys predominantly centred on encoder-based models such as BERT, the emergence of decoder-only Transformers spurred advancements in analyzing these potent generative models. They explore methods to decode information in neuralnetwork models, especially in natural language processing.
ML-Based Approach: Rule-based approach fails to identify things like Irony and sarcasm, multiple types of negations, word ambiguity, and multipolarity in text. Due to this, businesses are now focusing on an ML-based approach, where different ML algorithms are trained on a large dataset of prelabeled text.
This post gathers ten ML and NLP research directions that I found exciting and impactful in 2019. Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al., 2019 ) and other variants. Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al.,
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Google Research has been at the forefront of this effort, developing many innovations from privacy-safe recommendation systems to scalable solutions for large-scale ML. You can find other posts in the series here.)
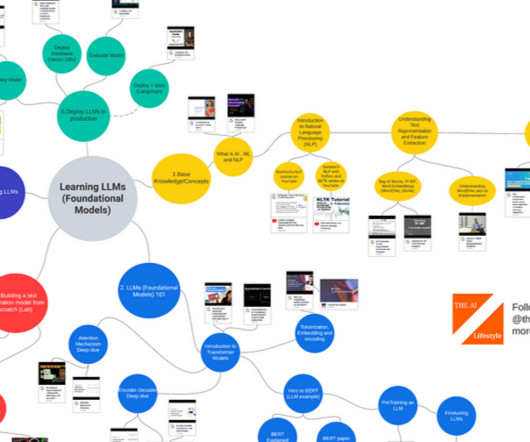
Learning LLMs (Foundational Models) Base Knowledge / Concepts: What is AI, ML and NLP Introduction to ML and AI — MFML Part 1 — YouTube What is NLP (Natural Language Processing)? — YouTube Transformer NeuralNetworks — EXPLAINED! YouTube BERT Research — Ep.
Conventional approaches to ML explainability attribute a model’s behavior to low-level features of the input, whereas concept-based methods examine the high-level features of the image and extract semantic knowledge from it. Don’t Forget to join our 55k+ ML SubReddit. If you like our work, you will love our newsletter.
transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, The fourth model which is also used for multi-class classification is built using the famous BERT architecture. The architecture of BERT is represented in Figure 14.
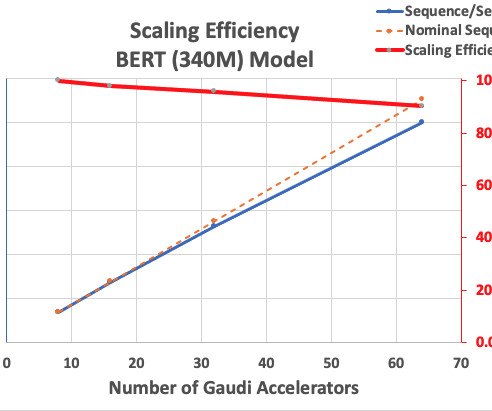
We present scaling results for an encoder-type transformer model (BERT with 340 million to 1.5 As a result, we achieved pre-training (phase 1) model convergence within 16 hours (our target was to train a large model within a day) for the BERT 1.5-billion-parameter All these features are enabled on the BERT 1.5B 2 16 2,705.57
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content