This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
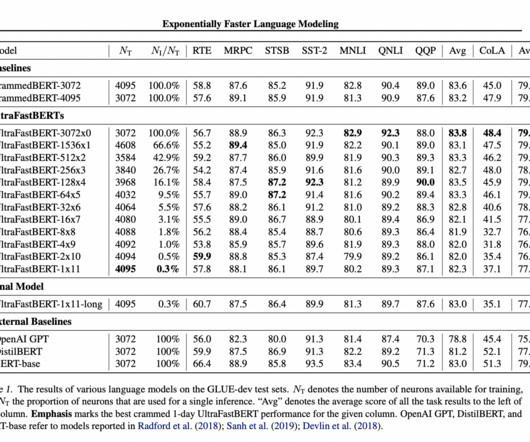
UltraFastBERT achieves comparable performance to BERT-base, using only 0.3% UltraFastBERT-1×11-long matches BERT-base performance with 0.3% In conclusion, UltraFastBERT is a modification of BERT that achieves efficient language modeling while using only a small fraction of its neurons during inference. of its neurons.
Programming Languages: Python (most widely used in AI/ML) R, Java, or C++ (optional but useful) 2. GPT, BERT) Image Generation (e.g., Programming: Learn Python, as its the most widely used language in AI/ML. Step 2: Learn Machine Learning and Deep Learning Start with the basics of Machine Learning (ML) and Deep Learning (DL).
BERT is a language model which was released by Google in 2018. As such, it has been the powerhouse of numerous natural language processing (NLP) applications since its inception, and even in the age of large language models (LLMs), BERT-style encoder models are used in tasks like vector embeddings and retrieval augmented generation (RAG).
LLMs, including BERT and GPT-based models, are employed in two primary strategies: prompt engineering, which utilizes the internal knowledge of LLMs, and fine-tuning, which customizes models for specific datasets to improve anomaly detection performance. A projector aligns the vector spaces of BERT and Llama to maintain semantic coherence.
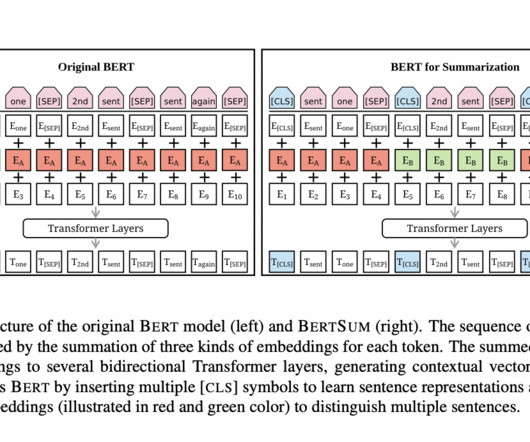
Models like GPT, BERT, and PaLM are getting popular for all the good reasons. The well-known model BERT, which stands for Bidirectional Encoder Representations from Transformers, has a number of amazing applications. Recent research investigates the potential of BERT for text summarization.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
Introduction Do you know, that you can automate machine learning (ML) deployments and workflow? This can be done using Machine Learning Operations (MLOps), which are a set of rules and practices that simplify and automate ML deployments and workflows. Yes, you heard it right.
Encoder models like BERT and RoBERTa have long been cornerstones of natural language processing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. While newer models like GTE and CDE improved fine-tuning strategies for tasks like retrieval, they rely on outdated backbone architectures inherited from BERT.
Traditional models, such as BERT and RoBERTa, have set new standards for sentence-pair comparison, yet they are inherently slow for tasks that require processing large datasets. A notable issue in text processing arises from the computational cost of comparing sentences. If you like our work, you will love our newsletter.
Machine learning (ML) is a powerful technology that can solve complex problems and deliver customer value. However, ML models are challenging to develop and deploy. MLOps are practices that automate and simplify ML workflows and deployments. MLOps make ML models faster, safer, and more reliable in production.
AI and ML are expanding at a remarkable rate, which is marked by the evolution of numerous specialized subdomains. Notably, BERT (Bidirectional Encoder Representations from Transformers), introduced by Devlin et al. Dont Forget to join our 65k+ ML SubReddit.
They use real-time data and machine learning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. To achieve this, Lumi developed a classification model based on BERT (Bidirectional Encoder Representations from Transformers) , a state-of-the-art natural language processing (NLP) technique.
to close the gap between BERT-base and BERT-large performance. Dont Forget to join our 65k+ ML SubReddit. For 3D point classification, the system outperformed human-designed methods such as PointNet, achieving an overall accuracy of 93.9%a improvement over baseline models.
BERT is a state-of-the-art algorithm designed by Google to process text data and convert it into vectors ([link]. What makes BERT special is, apart from its good results, the fact that it is trained over billions of records and that Hugging Face provides already a good battery of pre-trained models we can use for different ML tasks.
What is Generative Artificial Intelligence, how it works, what its applications are, and how it differs from standard machine learning (ML) techniques. Training and deploying these models on Vertex AI – a fully managed ML platform by Google. Understand how the attention mechanism is applied to ML models.
Experiments with a BERT-based MLTC model on benchmark datasets like AAPD and StackOverflow show that BEAL improves training efficiency, achieving convergence with fewer labeled samples. Don’t Forget to join our 55k+ ML SubReddit. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. It helps data scientists, AI developers, and ML engineers enhance their skills through engaging learning experiences and practical exercises.
SageMaker provides single model endpoints (SMEs), which allow you to deploy a single ML model, or multi-model endpoints (MMEs), which allow you to specify multiple models to host behind a logical endpoint for higher resource utilization. Set up the environment We begin by setting up the required environment.
An analysis of the MT-BERT multi-teacher distillation method. 💡 ML Concept of the Day: Understanding Multi-Teacher Distillation Distillation is typically explained using a teacher-student architecture, where we often conceptualize it as involving a single teacher model. A review of the Portkey framework for LLM guardrailing.
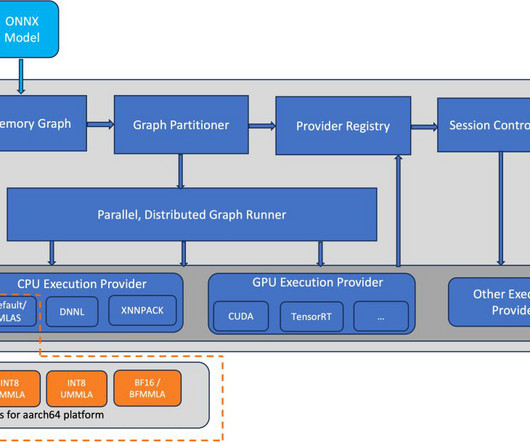
ONNX is an open source machine learning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. AWS Graviton3 processors are optimized for ML workloads, including support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions.
The model outperforms traditional attention-based models, such as BERT and Vision Transformers, across domains with smaller model sizes. Compared to the BERT-base, the Orchid-BERT-base has 30% fewer parameters yet achieves a 1.0-point point improvement in the GLUE score. Also, don’t forget to follow us on Twitter.
With these advancements, it’s natural to wonder: Are we approaching the end of traditional machine learning (ML)? The two main types of traditional ML algorithms are supervised and unsupervised. Data Preprocessing and Feature Engineering: Traditional ML requires extensive preprocessing to transform datasets as per model requirements.
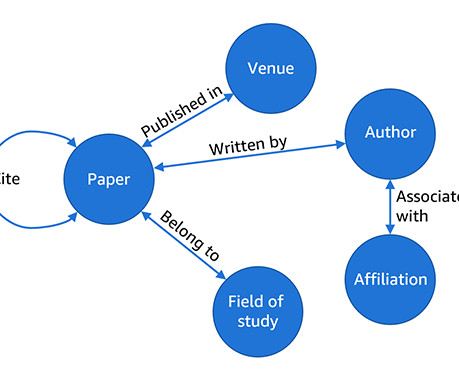
GraphStorm is a low-code enterprise graph machine learning (GML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. introduces refactored graph ML pipeline APIs. GraphStorm provides different ways to fine-tune the BERT models, depending on the task types.
a low-code enterprise graph machine learning (ML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. With GraphStorm, we release the tools that Amazon uses internally to bring large-scale graph ML solutions to production. license on GitHub. GraphStorm 0.1
We will explore how LLMs can be used to enhance various aspects of graph ML, review approaches to incorporate graph knowledge into LLMs, and discuss emerging applications and future directions for this exciting field.
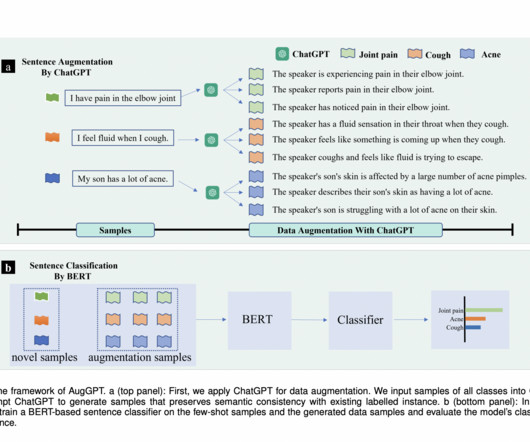
AugGPT’s framework consists of fine-tuning BERT on the base dataset, generating augmented data (Daugn) using ChatGPT, and fine-tuning BERT with the augmented data. The few-shot text classification model is based on BERT, using cross-entropy and contrastive loss functions to classify samples effectively.
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks.
Featured Community post from the Discord Aman_kumawat_41063 has created a GitHub repository for applying some basic ML algorithms. Perfectlord is looking for a few college students from India for the Amazon ML Challenge. From linear regression to decision trees, these algorithms are the building blocks of ML. Meme of the week!
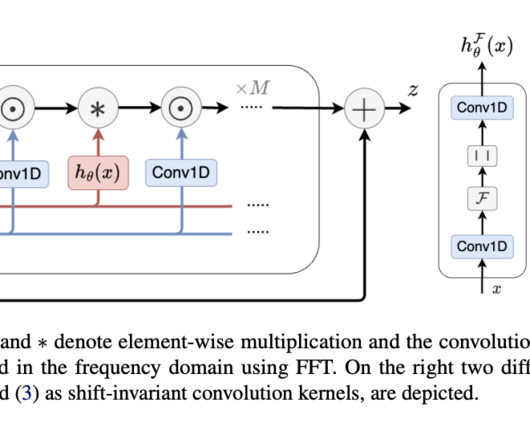
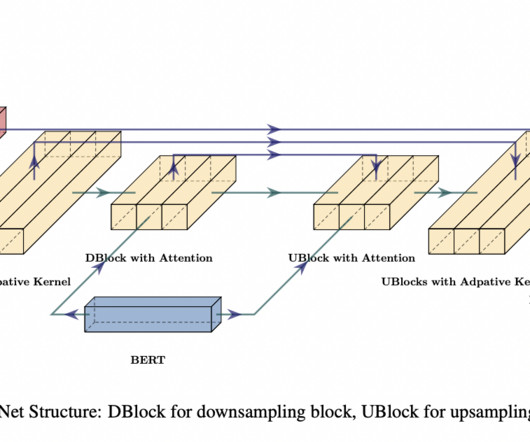
This model consists of two primary modules: A pre-trained BERT model is employed to extract pertinent information from the input text, and A diffusion UNet model processes the output from BERT. It is built upon a pre-trained BERT model. The BERT model takes subword input, and its output is processed by a 1D U-Net structure.
To support overarching pharmacovigilance activities, our pharmaceutical customers want to use the power of machine learning (ML) to automate the adverse event detection from various data sources, such as social media feeds, phone calls, emails, and handwritten notes, and trigger appropriate actions.
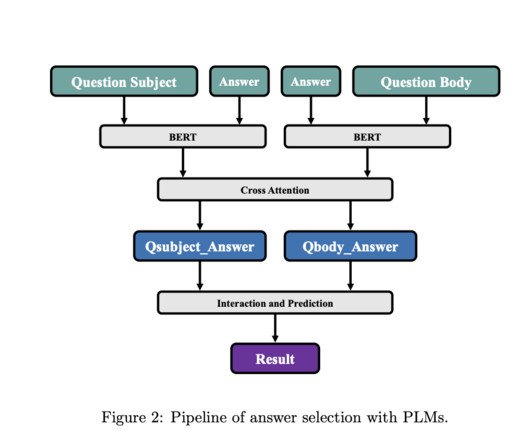
BERT was utilized for pre-training on question subjects, bodies, and answers, along with cross-attention mechanisms, capturing comprehensive semantic information and interactive features. Firstly, it employs BERT to capture contextual representations of question subjects, bodies, and answers in token form. Answers dataset.
Traditional NLP methods like CNN, RNN, and LSTM have evolved with transformer architecture and large language models (LLMs) like GPT and BERT families, providing significant advancements in the field. However, LLMs face challenges, including hallucination and the need for domain-specific knowledge. Also, don’t forget to follow us on Twitter.
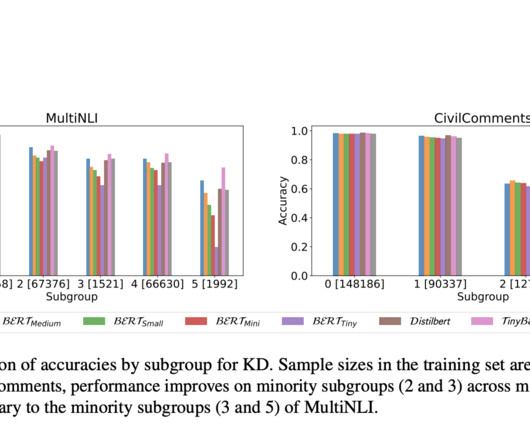
have proposed a comprehensive investigation into the effects of model compression on the subgroup robustness of BERT language models. The methodology employed in this study involved training each compressed BERT model using Empirical Risk Minimization (ERM) with five distinct initializations.
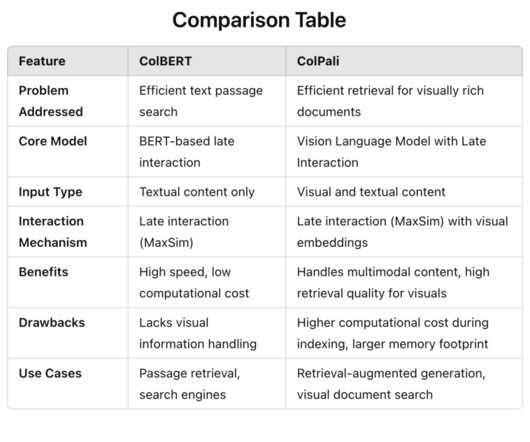
ColBERT seeks to enhance the effectiveness of passage search by leveraging deep pre-trained language models like BERT while maintaining a lower computational cost through late interaction techniques. Key Elements Key elements of ColBERT include the use of BERT for context encoding and a novel late interaction architecture.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. Solutions Architect in the ML Frameworks Team.
By taking care of the undifferentiated heavy lifting, SageMaker allows you to focus on working on your machine learning (ML) models, and not worry about things such as infrastructure. Prior to working at Amazon Music, Siddharth was working at companies like Meta, Walmart Labs, Rakuten on E-Commerce centric ML Problems.
In computer vision, autoregressive pretraining was initially successful, but subsequent developments have shown a sharp paradigm change in favor of BERT-style pretraining. However, because of its greater effectiveness in visual representation learning, subsequent research has come to prefer BERT-style pretraining.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, natural language processing, content creation, and more. times the speed for BERT, making AWS Graviton-based instances the fastest compute-optimized instances on AWS for CPU-based model inference solutions.
Great machine learning (ML) research requires great systems. In this post, we provide an overview of the numerous advances made across Google this past year in systems for ML that enable us to support the serving and training of complex models while easing the complexity of implementation for end users.
Exploring the Techniques of LIME and SHAP Interpretability in machine learning (ML) and deep learning (DL) models helps us see into opaque inner workings of these advanced models. SHAP ( Source ) Both LIME and SHAP have emerged as essential tools in the realm of AI and ML, addressing the critical need for transparency and trustworthiness.
We capitalized on the powerful tools provided by AWS to tackle this challenge and effectively navigate the complex field of machine learning (ML) and predictive analytics. An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages.
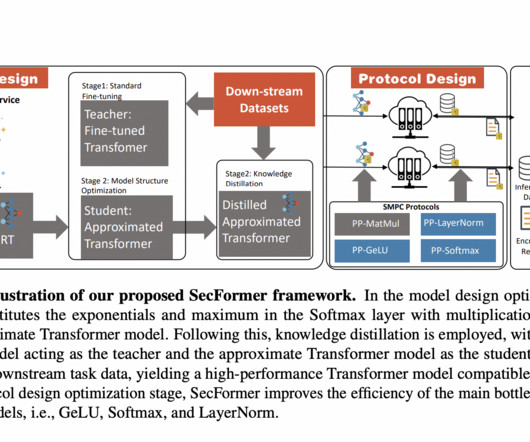
For instance, BERT BASE takes 71 seconds per sample via SMPC, compared to less than 1 second for plain-text inference ( shown in Figure 3 ). Join our 35k+ ML SubReddit , 41k+ Facebook Community, Discord Channel , and LinkedIn Gr oup. With an average improvement of 5.6% Check out the Paper.
You previously invested in AI and ML companies through the London-based AI Seed, what were some of the common traits that you observed with successful AI startups? Teams that grasp and embrace this viewpoint are the ones that genuinely thrive in the AI/ML landscape. We’ve had quite the archetypal startup story.
These adapters allow BERT to be fine-tuned for specific downstream tasks while retaining most of its pre-trained parameters. These adapters allow BERT to be fine-tuned for specific downstream tasks while retaining most of its pre-trained parameters. Also, don’t forget to follow us on Twitter.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content