This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Since SimTalk is unfamiliar to LLMs due to its proprietary nature and limited training data, the out-of-the-box code generation quality is quite poor compared to more popular programming languages like Python, which have extensive publicly available datasets and broader community support.
When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata. The following sample XML illustrates the prompts template structure: EN FR Prerequisites The project code uses the Python version of the AWS Cloud Development Kit (AWS CDK). The request is sent to the prompt generator.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
Text classification with transformers involves using a pretrained transformer model, such as BERT, RoBERTa, or DistilBERT, to classify input text into one or more predefined categories or labels. BERT (Bidirectional Encoder Representations from Transformers) is a language model that was introduced by Google in 2018.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. The code can be found on the GitHub repo. Instead of a data-prep.sh
In this post, we use a Hugging Face BERT-Large model pre-training workload as a simple example to explain how to useTrn1 UltraClusters. Launch your training job We use the Hugging Face BERT-Large Pretraining Tutorial as an example to run on this cluster. We submit the training job with the sbatch command.
Techniques like Word2Vec and BERT create embedding models which can be reused. BERT produces deep contextual embeddings by masking words and predicting them based on bidirectional context. BERT produces deep contextual embeddings by masking words and predicting them based on bidirectional context.
infer_model_id = "tensorflow-tc-bert-en-uncased-L-12-H-768-A-12-2" infer_model_version= "*" endpoint_name = name_from_base(f"jumpstart-example-{infer_model_id}") # Retrieve the inference docker container uri. script to retrieve the JumpStart model artifacts and deploy the pre-trained model to your local machine: python train_model.py
The following is a high-level overview of how it works conceptually: Separate encoders – These models have separate encoders for each modality—a text encoder for text (for example, BERT or RoBERTa), image encoder for images (for example, CNN for images), and audio encoders for audio (for example, models like Wav2Vec).
device type, location), while the Pin tower encodes visual features(CNN-extracted embeddings), textual metadata(BERT embeddings), and statistical features(e.g., LLM Functions empowers you to effortlessly build powerful LLM tools and agents using familiar languages like Bash, JavaScript, and Python. historical engagement rates).
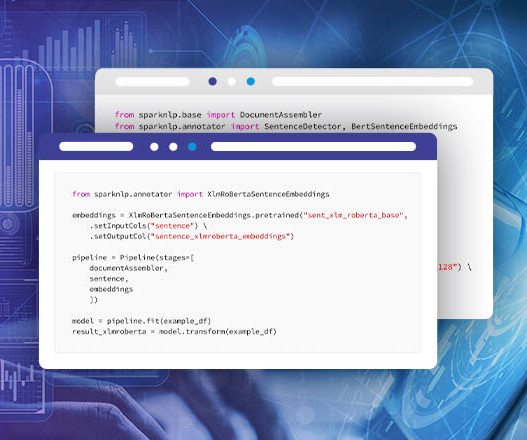
Please check our similar post about “Embeddings with Transformers” for BERT family embeddings. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. Python Docs : WordEmbeddings , Word2Vec.
Natural Language Question Answering : Use BERT to answer questions based on text passages. In addition, you can also add metadata with human-readable model descriptions as well as machine-readable data. The TensorFlow Lite Converter landing page contains a Python API to convert the model.
Specifically, it involves using pre-trained transformer models, such as BERT or RoBERTa, to encode text into dense vectors that capture the semantic meaning of the sentences. There is also a short section about generating sentence embeddings from Bert word embeddings, focusing specifically on the average-based transformation technique.
Advantages of adopting generative approaches for NLP tasks For customer feedback analysis, you might wonder if traditional NLP classifiers such as BERT or fastText would suffice. Prompt engineering To invoke Amazon Bedrock, you can follow our code sample that uses the Python SDK.
Our next generation release that is faster, more Pythonic and Dynamic as ever for details. times the speed for BERT, making AWS Graviton-based instances the fastest compute-optimized instances on AWS for CPU-based model inference solutions. This leads to improved performance compared to vanilla BERT. Refer to PyTorch 2.0:
Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. The AWS Python SDK Boto3 may also be combined with Torch Dataset classes to create custom data loading code.
In addition to natural language reasoning steps, the model generates python syntax that is then executed in order to output the final answer. Additive embeddings are used for representing metadata about each note. Analysis shows that the final layers of ELECTRA and BERT capture subject-verb agreement errors best.
You can directly use the FMEval wherever you run your workloads, as a Python package or via the open-source code repository, which is made available in GitHub for transparency and as a contribution to the Responsible AI community. How can you get started?
An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. Setup To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). This is called a pre-trained model.
The Python example below showcases a ReAct pattern. They can decide to pass calculations to a calculator or Python interpreter depending on the situation. It accepts a question in natural language, and the language model in turn generates a Python code snippet which is then executed to produce the answer.
The Amazon Product Reviews Dataset provides over 142 million Amazon product reviews with their associated metadata, allowing machine learning practitioners to train sentiment models using product ratings as a proxy for the sentiment label. Coursera – Applied Text Mining in Python video demonstration.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. The following table shows the metadata of three of the largest accelerated compute instances. 32xlarge 0 16 0 128 512 512 4 x 1.9
Large models like GPT-3 (175B parameters) or BERT-Large (340M parameters) can be reduced by 75% or more. Running BERT models on smartphones for on-device natural language processing requires much less energy due to resource constrained in smartphones than server deployments.
First, a preprocessing model is applied to the input text tokenization (implemented in Python). Then we use a pre-trained BERT (uncased) model from the Hugging Face Model Hub to extract token embeddings. BERT is an English language model that was trained using a masked language modeling (MLM) objective. nvidia/pytorch:22.10-py3
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content