This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
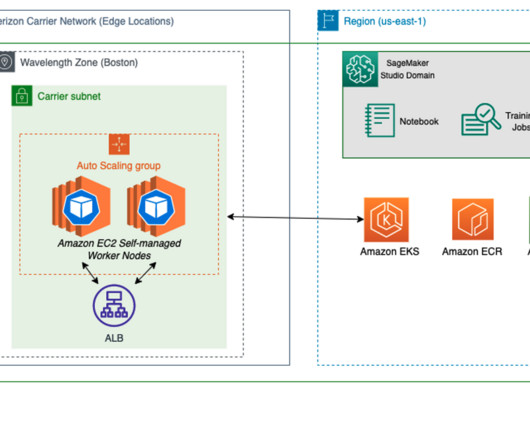
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Participants learn to build metadata for documents containing text and images, retrieve relevant text chunks, and print citations using Multimodal RAG with Gemini.
However, as technology advanced, so did the complexity and capabilities of AI music generators, paving the way for deep learning and NaturalLanguageProcessing (NLP) to play pivotal roles in this tech. Initially, the attempts were simple and intuitive, with basic algorithms creating monotonous tunes.
Artificial Intelligence is a very vast branch in itself with numerous subfields including deep learning, computer vision , naturallanguageprocessing , and more.
Scientific metadata in research literature holds immense significance, as highlighted by flourishing research in scientometricsa discipline dedicated to analyzing scholarly literature. Metadata improves the findability and accessibility of scientific documents by indexing and linking papers in a massive graph.
Sentiment analysis and other naturallanguage programming (NLP) tasks often start out with pre-trained NLP models and implement fine-tuning of the hyperparameters to adjust the model to changes in the environment. She has a technical background in AI and NaturalLanguageProcessing.
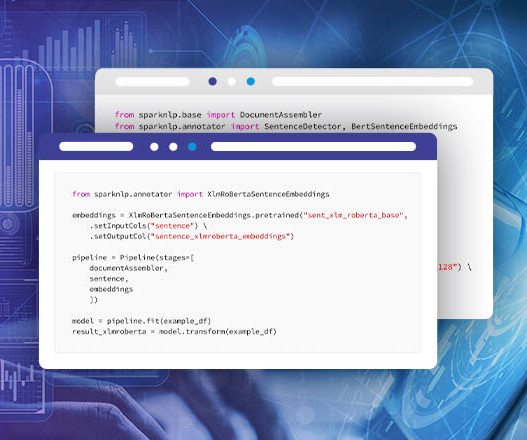
Many different transformer models have already been implemented in Spark NLP, and specifically for text classification, Spark NLP provides various annotators that are designed to work with pretrained language models. BERT (Bidirectional Encoder Representations from Transformers) is a language model that was introduced by Google in 2018.
Retailers can deliver more frictionless experiences on the go with naturallanguageprocessing (NLP), real-time recommendation systems, and fraud detection. In our example, we use the Bidirectional Encoder Representations from Transformers (BERT) model, commonly used for naturallanguageprocessing.
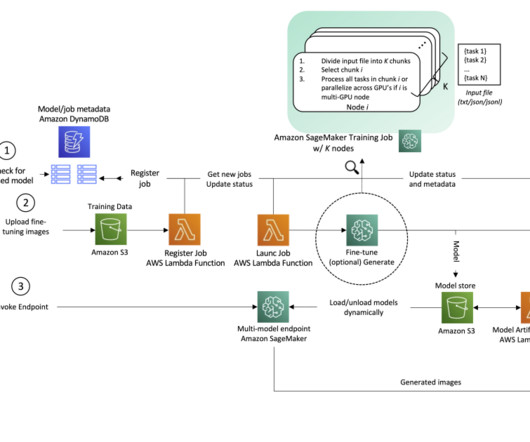
The course toward democratization of AI helped to further popularize generative AI following the open-source releases for such foundation model families as BERT, T5, GPT, CLIP and, most recently, Stable Diffusion. This includes the user ID, model training job ID, and status, along with hyperparameters and metadata associated with training.
Large language models (LLMs) have exploded in popularity over the last few years, revolutionizing naturallanguageprocessing and AI. Techniques like Word2Vec and BERT create embedding models which can be reused. Google's MUM model uses VATT transformer to produce entity-aware BERT embeddings.
The following is a high-level overview of how it works conceptually: Separate encoders – These models have separate encoders for each modality—a text encoder for text (for example, BERT or RoBERTa), image encoder for images (for example, CNN for images), and audio encoders for audio (for example, models like Wav2Vec).
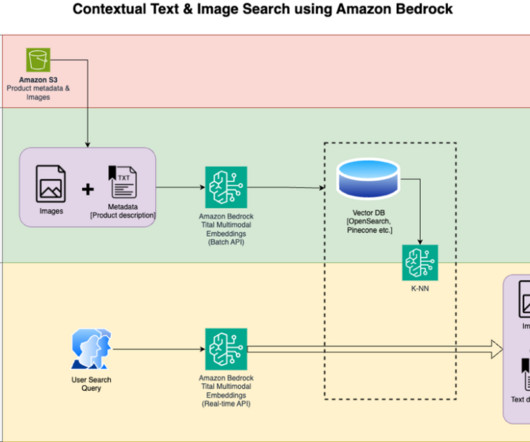
These vectors are typically generated by machine learning models and enable fast similarity searches that power AI-driven applications like recommendation engines, image recognition, and naturallanguageprocessing. Traditional search relies on discrete tokens like keywords, tags, or metadata to retrieve exact matches.
Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. Advantages of adopting generative approaches for NLP tasks For customer feedback analysis, you might wonder if traditional NLP classifiers such as BERT or fastText would suffice.
Genomic language models Genomic language models represent a new approach in the field of genomics, offering a way to understand the language of DNA. Some of the pioneering genomic language models include DNABERT which was one of the first attempts to use the transformer architecture to learn the language of DNA.
Input and output – These fields are required because NVIDIA Triton needs metadata about the model. In the following sections, we walk you through the example notebook that demonstrates how to use NVIDIA Triton Inference Server on SageMaker MMEs with the GPU feature to deploy a BERTnaturallanguageprocessing (NLP) model.
The second ensemble transforms raw naturallanguage sentences into embeddings and consists of three models. Then we use a pre-trained BERT (uncased) model from the Hugging Face Model Hub to extract token embeddings. BERT is an English language model that was trained using a masked language modeling (MLM) objective.
Sentence embeddings are a powerful tool in naturallanguageprocessing that helps analyze and understand language. Specifically, it involves using pre-trained transformer models, such as BERT or RoBERTa, to encode text into dense vectors that capture the semantic meaning of the sentences.
Language Disparity in NaturalLanguageProcessing This digital divide in naturallanguageprocessing (NLP) is an active area of research. 2 ] Multilingual models perform worse on several NLP tasks on low resource languages than on high resource languages such as English.[
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, naturallanguageprocessing, content creation, and more. This leads to improved performance compared to vanilla BERT. With the recent PyTorch 2.0 torch.compile + bf16 + fused AdamW.
I have written short summaries of 68 different research papers published in the areas of Machine Learning and NaturalLanguageProcessing. Additive embeddings are used for representing metadata about each note. Analysis shows that the final layers of ELECTRA and BERT capture subject-verb agreement errors best.
Media Analytics, where we analyze all the broadcast content, as well as live content, that we’re distributing to extract additional metadata from this data and make it available to other systems to create new interactive experiences, or for further insights into how customers are using our streaming services.
Media Analytics, where we analyze all the broadcast content, as well as live content, that we’re distributing to extract additional metadata from this data and make it available to other systems to create new interactive experiences, or for further insights into how customers are using our streaming services.
Sentence detection is an essential component in many naturallanguageprocessing (NLP) tasks, as it enables the analysis of text at a more granular level by breaking it down into individual sentences. Sentence Detection in Spark NLP is the process of automatically identifying the boundaries of sentences in a given text.
Models that allow interaction via naturallanguage have become ubiquitious. Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. On Achieving and Evaluating Language-Independence in NLP.
Language models are statistical methods predicting the succession of tokens in sequences, using natural text. Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical.
Word embeddings are considered as a type of representation used in naturallanguageprocessing (NLP) to capture the meaning of words in a numerical form. Word embeddings are used in naturallanguageprocessing (NLP) as a technique to represent words in a numerical format.
This is one of the reasons why detecting sentiment from naturallanguage (NLP or naturallanguageprocessing ) is a surprisingly complex task. Now we’re dealing with the same words except they’re surrounded by additional information that changes the tone of the overall message from positive to sarcastic.
Below you will find short summaries of a number of different research papers published in the areas of Machine Learning and NaturalLanguageProcessing in the past couple of years (2017-2019). link] A bidirectional transformer architecture for pre-training language representations. NAACL 2019.
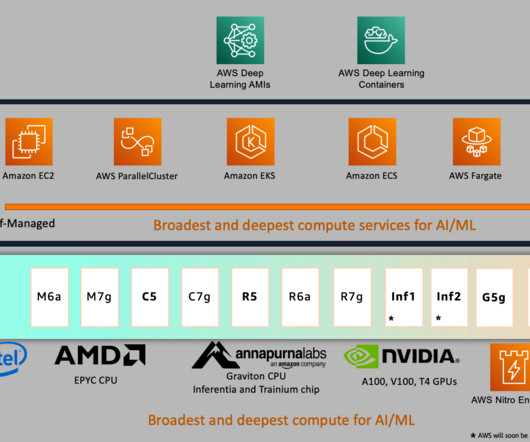
The following table shows the metadata of three of the largest accelerated compute instances. The benchmark used is the RoBERTa-Base, a popular model used in naturallanguageprocessing (NLP) applications, that uses the transformer architecture. 32xlarge 0 16 0 128 512 512 4 x 1.9
") print(prompt.format(subject=" NaturalLanguageProcessing ")) As we advance in complexity, we encounter more sophisticated patterns in LangChain, such as the Reason and Act (ReAct) pattern. The agent takes an input, a simple addition task, processes it using the provided OpenAI model and returns the result.
Large models like GPT-3 (175B parameters) or BERT-Large (340M parameters) can be reduced by 75% or more. Running BERT models on smartphones for on-device naturallanguageprocessing requires much less energy due to resource constrained in smartphones than server deployments.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content