This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
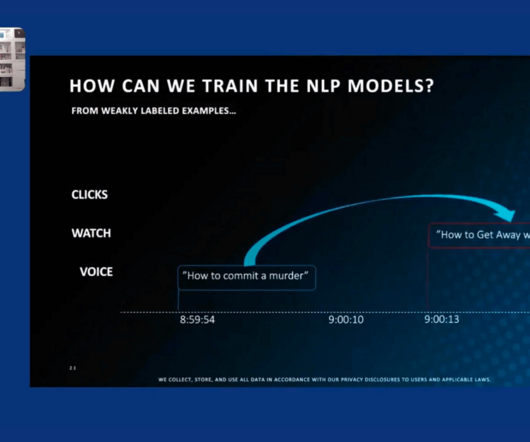
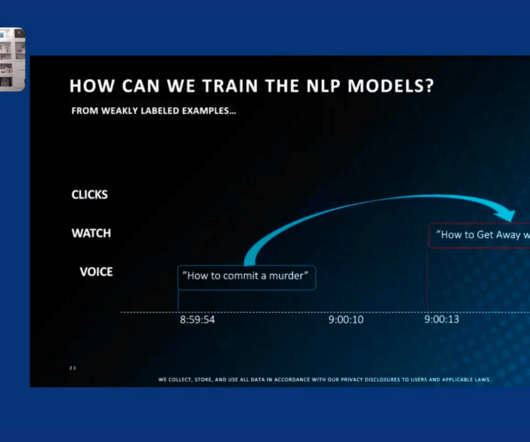
For instance, we use query rewriting techniques such as expansion, relaxation, and segmentation, and extract metadata from queries to dynamically build filters for more targeted searches. With the advent of generative models (LLMs), the importance of effective retrieval has only grown.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata. You can enhance this technique by using metadata-driven filtering to collect the relevant pairs according to the source text. The request is sent to the prompt generator. Cohere Embed supports 108 languages.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Participants learn to build metadata for documents containing text and images, retrieve relevant text chunks, and print citations using Multimodal RAG with Gemini.
In the age of data-driven artificial intelligence, LLMs like GPT-3 and BERT require vast amounts of well-structured data from diverse sources to improve performance across various applications. Crawl4AI employs a multi-step process to optimize web crawling for LLM training.
Scientific metadata in research literature holds immense significance, as highlighted by flourishing research in scientometricsa discipline dedicated to analyzing scholarly literature. Metadata improves the findability and accessibility of scientific documents by indexing and linking papers in a massive graph.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. The code can be found on the GitHub repo.
An illustration of the pretraining process of MusicLM: SoundStream, w2v-BERT, and Mulan | Image source: here Moreover, MusicLM expands its capabilities by allowing melody conditioning.
NLP in particular has been a subfield that has been focussed heavily in the past few years that has resulted in the development of some top-notch LLMs like GPT and BERT. Artificial Intelligence is a very vast branch in itself with numerous subfields including deep learning, computer vision , natural language processing , and more.
Text classification with transformers involves using a pretrained transformer model, such as BERT, RoBERTa, or DistilBERT, to classify input text into one or more predefined categories or labels. BERT (Bidirectional Encoder Representations from Transformers) is a language model that was introduced by Google in 2018.
Some popular examples of LLMs include GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), and XLNet. These models learn to understand and generate human-like language by analyzing patterns and relationships within the training data. Docker image.
And Miso had already built an early LLM-based search engine using the open-source BERT model that delved into research papers—it could take a query in natural language and find a snippet of text in a document that answered that question with surprising reliability and smoothness.
While Amazon can be marginally adopted for studying multimodal S&R systems, it only offers pseudo queries derived from product metadata, lacking real user search behaviors. JD Search and KuaiSAR provide only anonymized item contents, making model effectiveness interpretation difficult.
In this post, we use a Hugging Face BERT-Large model pre-training workload as a simple example to explain how to useTrn1 UltraClusters. Launch your training job We use the Hugging Face BERT-Large Pretraining Tutorial as an example to run on this cluster. Each compute node has Neuron tools installed, such as neuron-top.
Long-term coherence (semantic modeling) tokens : A second component based on w2v-BERT , generates 25 semantic tokens per second that represent features of large-scale composition , such as motifs, or consistency in the timbres. The model is trained conditionally on text metadata alongside audio file duration and initiation time.
Techniques like Word2Vec and BERT create embedding models which can be reused. BERT produces deep contextual embeddings by masking words and predicting them based on bidirectional context. BERT produces deep contextual embeddings by masking words and predicting them based on bidirectional context.
Input and output – These fields are required because NVIDIA Triton needs metadata about the model. In the following sections, we walk you through the example notebook that demonstrates how to use NVIDIA Triton Inference Server on SageMaker MMEs with the GPU feature to deploy a BERT natural language processing (NLP) model.
The following is a high-level overview of how it works conceptually: Separate encoders – These models have separate encoders for each modality—a text encoder for text (for example, BERT or RoBERTa), image encoder for images (for example, CNN for images), and audio encoders for audio (for example, models like Wav2Vec).
Traditional search relies on discrete tokens like keywords, tags, or metadata to retrieve exact matches. If you ask for smooth jazz it might also suggest tracks from blues or lo-fi genres that have a similar feel, even if they dont explicitly mention jazz in their metadata. How is it Different from Traditional Databases?
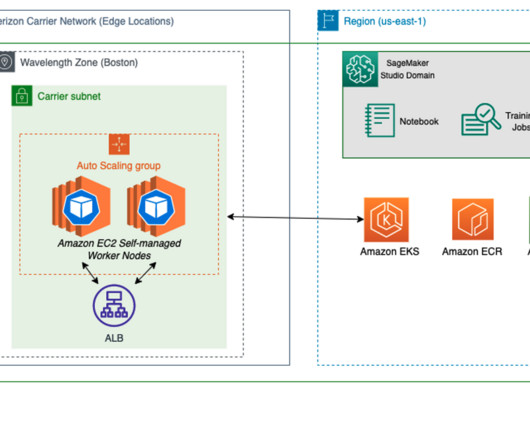
Along with this announcement, we are also publishing a detailed tutorial that guides you through the steps required to run a multi-instance distributed training job (BERT phase 1 pre-training) using Amazon EKS and Trn1 instances. In this post, you will learn about the solution architecture and review several key steps from the tutorial.
DNABERT used a Bidirectional Encoder Representations from Transformers (BERT, encoder-only) architecture pre-trained on a human reference genome and showed promising results on downstream supervised tasks.
Specifically, it involves using pre-trained transformer models, such as BERT or RoBERTa, to encode text into dense vectors that capture the semantic meaning of the sentences. There is also a short section about generating sentence embeddings from Bert word embeddings, focusing specifically on the average-based transformation technique.
Natural Language Question Answering : Use BERT to answer questions based on text passages. In addition, you can also add metadata with human-readable model descriptions as well as machine-readable data. Text Classification: Categorize text into predefined groups for content moderation and tone detection.
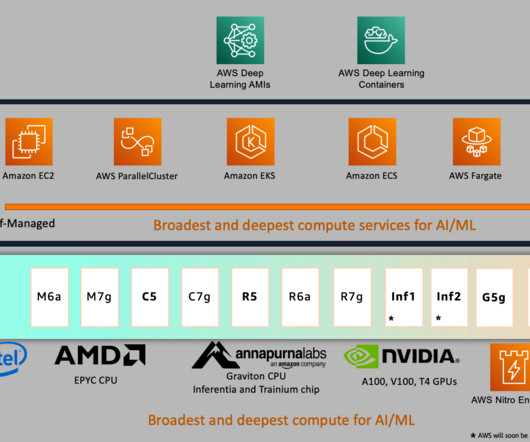
This post further walks through a step-by-step implementation of fine-tuning a RoBERTa (Robustly Optimized BERT Pretraining Approach) model for sentiment analysis using AWS Deep Learning AMIs (AWS DLAMI) and AWS Deep Learning Containers (DLCs) on Amazon Elastic Compute Cloud (Amazon EC2 p4d.24xlarge) torch.compile + bf16 + fused AdamW.
Advantages of adopting generative approaches for NLP tasks For customer feedback analysis, you might wonder if traditional NLP classifiers such as BERT or fastText would suffice. The following diagram illustrates the architecture and workflow of the proposed solution.
Media Analytics, where we analyze all the broadcast content, as well as live content, that we’re distributing to extract additional metadata from this data and make it available to other systems to create new interactive experiences, or for further insights into how customers are using our streaming services.
Media Analytics, where we analyze all the broadcast content, as well as live content, that we’re distributing to extract additional metadata from this data and make it available to other systems to create new interactive experiences, or for further insights into how customers are using our streaming services.
You may also like Can GPT-3 or BERT Ever Understand Language?—The The solution MLOps tools, such as neptune.ai , let you automatically log all of the relevant metadata, like metrics, parameters, learning rates, and variables in a distributed training setup.
Additive embeddings are used for representing metadata about each note. Analysis shows that the final layers of ELECTRA and BERT capture subject-verb agreement errors best. [link] Assigning ICD codes to discharge summaries in electronic health records, which indicate the diagnoses and procedures for each patient.
The metrics are case insensitive and the values are in the range of 0 (no match) to 1 (perfect match); (2) METEOR score (similar to ROUGE, but including stemming and synonym matching via synonym lists, e.g. “rain” → “drizzle”); (3) BERTScore (a second ML model from the BERT family to compute sentence embeddings and compare their cosine similarity.
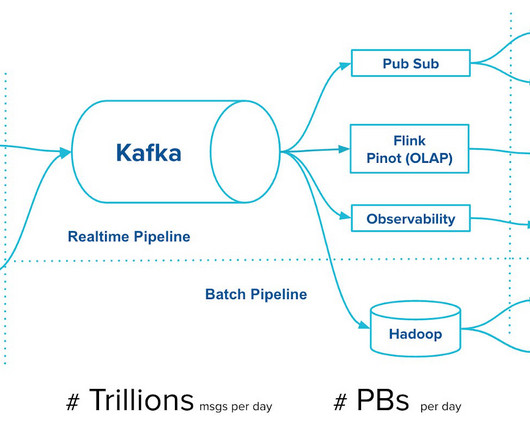
RemoteLogMetadataManager: An interface for managing the lifecycle of metadata about remote log segments with strongly consistent semantics. The RemoteLogManager determines the targeted remote segment based on the desired offset and leader epoch by querying the metadata store using the RemoteLogMetadataManager.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. They find that BERT-large is surprisingly competitive against supervised knowledge bases and relation extractors, although the performance does depend on the type of question. NAACL 2019.
An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. Let's just peek into the pre-BERT world… For creating models, we need words to be represented in a form n understood by the training network, ie, numbers.
The Amazon Product Reviews Dataset provides over 142 million Amazon product reviews with their associated metadata, allowing machine learning practitioners to train sentiment models using product ratings as a proxy for the sentiment label. Most advanced sentiment models start by transforming the input text into an embedded representation.
With the arrival of pre-trained models such as BERT, fine-tuning pre-trained models for downstream tasks became the norm. {Document} ) and template metadata (e.g., This post consists of two articles that were first published in NLP News. NLP and ML have gone through several phases of how models are trained in recent years.
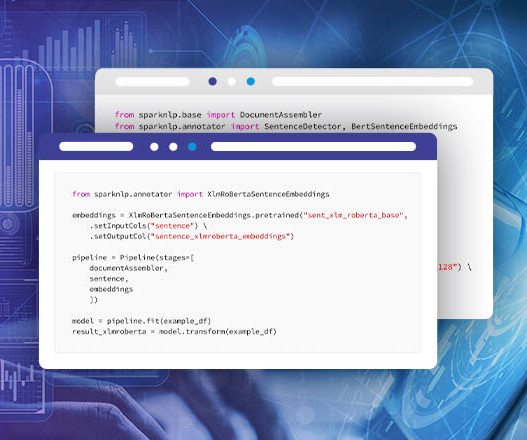
Please check our similar post about “Embeddings with Transformers” for BERT family embeddings. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. In this post, you will learn how to use word embeddings of Spark NLP.
Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. Language models are statistical methods predicting the succession of tokens in sequences, using natural text.
It came to its own with the creation of the transformer architecture: Google’s BERT, OpenAI, GPT2 and then 3, LaMDA for conversation, Mina and Sparrow from Google DeepMind. So there’s obviously an evolution. Really quickly, LLMs can do many things. There are various offshoots of that—Mina and Minerva, et cetera.
It came to its own with the creation of the transformer architecture: Google’s BERT, OpenAI, GPT2 and then 3, LaMDA for conversation, Mina and Sparrow from Google DeepMind. So there’s obviously an evolution. Really quickly, LLMs can do many things. There are various offshoots of that—Mina and Minerva, et cetera.
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. Writing System and Speaker Metadata for 2,800+ Language Varieties. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
I additionally use metadata from The World Atlas of Language Structures to obtain information such as language family (e.g. Are All Languages Created Equal in Multilingual BERT? Latin, Arabic alphabet) and main geographic region the language is predominant in (if relevant). Indo-European, Sino-Tibetan).[ Shijie Wu and Mark Dredze.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content