This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon Introduction In 2018, a powerful Transformer-based machinelearning model, namely, BERT was developed by Jacob Devlin and his colleagues from Google for NLP applications.
Introduction Advances in machinelearning models that process language have been rapid in the last few years. A great example is the announcement that BERT models are now a significant force behind Google Search. This progress has left the research lab and is beginning to power some leading digital products.
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
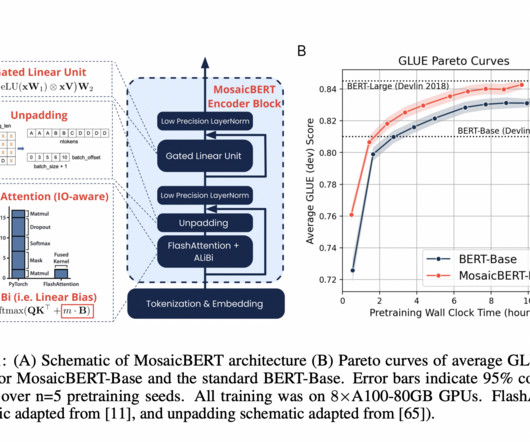
ModernBERT is an advanced iteration of the original BERT model, meticulously crafted to elevate performance and efficiency in natural language processing (NLP) tasks.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Natural Language processing, a sub-field of machinelearning has gained. The post Amazon Product review Sentiment Analysis using BERT appeared first on Analytics Vidhya.
Machinelearning (ML) is a powerful technology that can solve complex problems and deliver customer value. This is why MachineLearning Operations (MLOps) has emerged as a paradigm to offer scalable and measurable values to Artificial Intelligence (AI) driven businesses.
I have written short summaries of 68 different research papers published in the areas of MachineLearning and Natural Language Processing. Analysis shows that the final layers of ELECTRA and BERT capture subject-verb agreement errors best. They cover a wide range of different topics, authors and venues.
The post Here are 7 Data Science Projects on GitHub to Showcase your MachineLearning Skills! Overview Working on Data Science projects is a great way to stand out from the competition Check out these 7 data science projects on. appeared first on Analytics Vidhya.
Generative AI is powered by advanced machinelearning techniques, particularly deep learning and neural networks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Roles like AI Engineer, MachineLearning Engineer, and Data Scientist are increasingly requiring expertise in Generative AI.
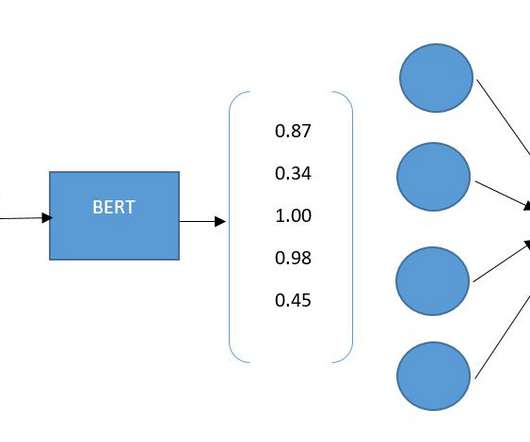
Dive into the world of NLP and learn how to analyze emotions in text with a few lines of code! That’s a bit like what BERT does — except instead of people, it reads text. BERT, short for Bidirectional Encoder Representations from Transformers, is a powerful machinelearning model developed by Google.
Photo by Abiyyu Zahy on Unsplash If youre diving into AI and want to understand the secret sauce behind modern language models like ChatGPT or BERT, you need to get familiar with Transformers and their game-changing attention mechanism. Thats kind of what Transformers do in NLP.
This is particularly useful for applications like machinelearning , where data points (such as images or text) can be represented as vectors in multi-dimensional spaces. Scalable for Large Datasets : As AI and machinelearning applications continue to grow, so does the amount of data they process.
Photo by Amr Taha™ on Unsplash In the realm of artificial intelligence, the emergence of transformer models has revolutionized natural language processing (NLP). In this guide, we will explore how to fine-tune BERT, a model with 110 million parameters, specifically for the task of phishing URL detection.
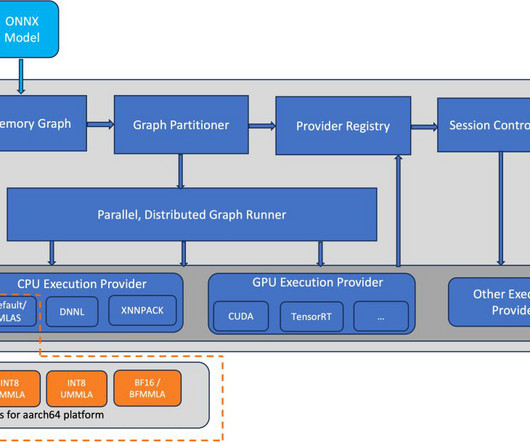
ONNX is an open source machinelearning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. You can see that for the BERT, RoBERTa, and GPT2 models, the throughput improvement is up to 65%. for the same fp32 model inference. for the same model inference.
A Complete Guide to Embedding For NLP & Generative AI/LLM By Mdabdullahalhasib This article provides a comprehensive guide to understanding and implementing vector embedding in NLP and generative AI.
Unlocking the Future of Language: The Next Wave of NLP Innovations Photo by Joshua Hoehne on Unsplash The world of technology is ever-evolving, and one area that has seen significant advancements is Natural Language Processing (NLP). A few years back, two groundbreaking models, BERT and GPT, emerged as game-changers.
Introduction Welcome into the world of Transformers, the deep learning model that has transformed Natural Language Processing (NLP) since its debut in 2017. These linguistic marvels, armed with self-attention mechanisms, revolutionize how machines understand language, from translating texts to analyzing sentiments.
They use real-time data and machinelearning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. This approach combines the efficiency of machinelearning with human judgment in the following way: The ML model processes and classifies transactions rapidly.
Natural language processing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader data science expertise.
BERT is a language model which was released by Google in 2018. As such, it has been the powerhouse of numerous natural language processing (NLP) applications since its inception, and even in the age of large language models (LLMs), BERT-style encoder models are used in tasks like vector embeddings and retrieval augmented generation (RAG).
Both BERT and GPT are based on the Transformer architecture. Word embedding is a technique in natural language processing (NLP) where words are represented as vectors in a continuous vector space. This facilitates various NLP tasks by providing meaningful word embeddings. This piece compares and contrasts between the two models.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
Labeling the wellness dimensions requires a clear understanding of social and psychological factors; we have invited an expert panel, including a clinical psychologist, rehabilitation counselor, and social NLP researcher. This indicates that they can accurately portray the complexity of multiple dimensions in social media language.
In recent years, remarkable strides have been achieved in crafting extensive foundation language models for natural language processing (NLP). These innovations have showcased strong performance in comparison to conventional machinelearning (ML) models, particularly in scenarios where labelled data is in short supply.
Machinelearning , a subset of AI, involves three components: algorithms, training data, and the resulting model. An algorithm, essentially a set of procedures, learns to identify patterns from a large set of examples (training data). The culmination of this training is a machine-learning model.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. It helps data scientists, AI developers, and ML engineers enhance their skills through engaging learning experiences and practical exercises.
Machinelearning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. Training experiment: Training BERT Large from scratch Training, as opposed to inference, is a finite process that is repeated much less frequently.
How Retrieval-Augmented Generation (RAG) Can Boost NLP Projects with Real-Time Data for Smarter AI Models This member-only story is on us. With models like GPT-3 and BERT, it feels like we’re able to do things that were once just sci-fi dreams, like answering complex questions and generating all kinds of content automatically.
Photo by adrianna geo on Unsplash NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.23.20 If you haven’t heard, we released the NLP Model Forge ? NLP Model Forge So… the NLP Model Forge, a collection of 1,400 NLP code snippets that you can seamlessly select to run inference in Colab!
Ivan Aivazovsky — Istanbul NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 09.06.20 nlp("Transformers and onnx runtime is an awesome combo!") ") GitHub: patil-suraj/onnx_transformers Accelerated NLP pipelines for fast inference ? Revival Welcome back, and what a week?!?!
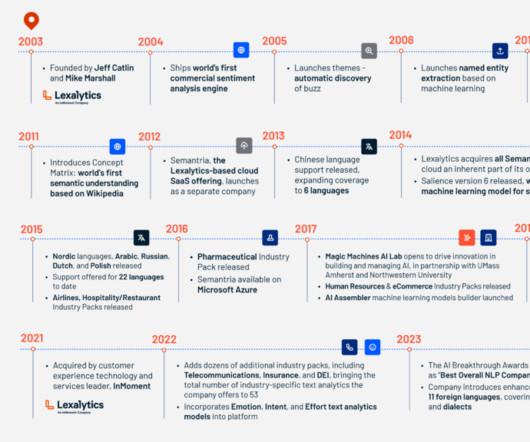
We’ve pioneered a number of industry firsts, including the first commercial sentiment analysis engine, the first Twitter/microblog-specific text analytics in 2010, the first semantic understanding based on Wikipedia in 2011, and the first unsupervised machinelearning model for syntax analysis in 2014.
Introduction To Generative AI Image Source Course difficulty: Beginner-level Completion time: ~ 45 minutes Prerequisites: No What will AI enthusiasts learn? What is Generative Artificial Intelligence, how it works, what its applications are, and how it differs from standard machinelearning (ML) techniques.
Keras is a widely used machinelearning tool known for its high-level abstractions and ease of use, enabling rapid experimentation. Recent advances in CV and NLP have introduced challenges, such as the prohibitive cost of training large, state-of-the-art models. Access to open-source pretrained models is crucial.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (Natural Language Processing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
It’s the underlying engine that gives generative models the enhanced reasoning and deep learning capabilities that traditional machinelearning models lack. They can also perform self-supervised learning to generalize and apply their knowledge to new tasks. An open-source model, Google created BERT in 2018.
But now, a computer can be taught to comprehend and process human language through Natural Language Processing (NLP), which was implemented, to make computers capable of understanding spoken and written language. This article will explain to you in detail about RoBERTa and if you do not know about BERT please click on the associated link.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
It’s also an area that stands to benefit most from automated or semi-automated machinelearning (ML) and natural language processing (NLP) techniques. Semi) automated data extraction for SLRs through NLP Researchers can deploy a variety of ML and NLP techniques to help mitigate these challenges.
Machinelearning models have heavily relied on labeled data for training, and traditionally speaking, training models on labeled data yields accurate results. To tackle the annotation issue, developers came up with the concept of SSL or Self Supervised Learning. They require a high amount of computational power.
Photo by Kunal Shinde on Unsplash NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.09.20 What is the state of NLP? CryptoHack – Home A fun platform to learn about cryptography through solving challenges and cracking insecure code. Forge Where are we? Are we anywhere where we want to be?
We’ll delve deep into its workings and explore its most celebrated offspring: BERT, GPT, and T5. From writing coherent essays to understanding intricate nuances in diverse languages, they’re reshaping our interaction with machines. This is the kind of contextual understanding that BERT brings to the table.
Synthetic data , artificially generated to mimic real data, plays a crucial role in various applications, including machinelearning , data analysis , testing, and privacy protection. However, generating synthetic data for NLP is non-trivial, demanding high linguistic knowledge, creativity, and diversity.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content