This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The ability to effectively represent and reason about these intricate relational structures is crucial for enabling advancements in fields like network science, cheminformatics, and recommender systems. Graph NeuralNetworks (GNNs) have emerged as a powerful deep learning framework for graph machinelearning tasks.
With these advancements, it’s natural to wonder: Are we approaching the end of traditional machinelearning (ML)? In this article, we’ll look at the state of the traditional machinelearning landscape concerning modern generative AI innovations. What is Traditional MachineLearning? What are its Limitations?
Machinelearning (ML) is a powerful technology that can solve complex problems and deliver customer value. This is why MachineLearning Operations (MLOps) has emerged as a paradigm to offer scalable and measurable values to Artificial Intelligence (AI) driven businesses.
Generative AI is powered by advanced machinelearning techniques, particularly deep learning and neuralnetworks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). GPT, BERT) Image Generation (e.g., These are essential for understanding machinelearning algorithms.
These gargantuan neuralnetworks have revolutionized how machineslearn and generate human language, propelling the boundaries of what was once thought possible.
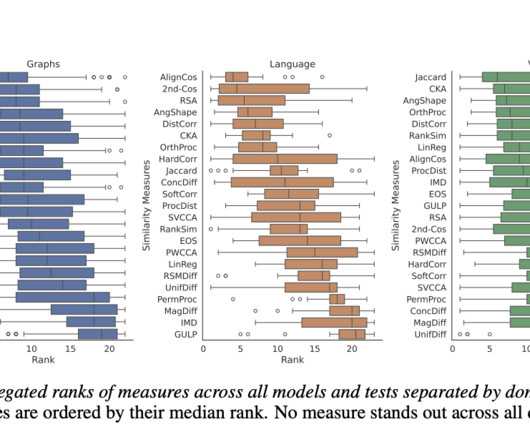
Representational similarity measures are essential tools in machinelearning, used to compare internal representations of neuralnetworks. The problem is compounded by the diversity of neuralnetwork architectures and their various tasks.
While they share foundational principles of machinelearning, their objectives, methodologies, and outcomes differ significantly. The authenticity of this approach lies in its ability to learn the fundamental data distribution and generate novel instances that are not mere replicas. Ian Goodfellow et al.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deep learning model designed explicitly for natural language processing tasks like answering questions, analyzing sentiment, and translation.
Photo by david clarke on Unsplash The most recent breakthroughs in language models have been the use of neuralnetwork architectures to represent text. Both BERT and GPT are based on the Transformer architecture. 2013 Word2Vec is a neuralnetwork model that uses n-grams by training on context windows of words.
Summary: Neuralnetworks are a key technique in MachineLearning, inspired by the human brain. They consist of interconnected nodes that learn complex patterns in data. This architecture allows neuralnetworks to learn complex patterns and relationships within data.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
I have written short summaries of 68 different research papers published in the areas of MachineLearning and Natural Language Processing. Gives a summary of different stages of this skill developing in humans, along with a review of this work in the deep learning field. University of Wisconsin-Madison.
Researchers at ETH Zurich have developed a new technique that can significantly boost the speed of neuralnetworks. They’ve demonstrated that altering the inference process can drastically cut down the computational requirements of these networks. In experiments conducted on BERT, a transformer …
We are going to explore these and other essential questions from the ground up , without assuming prior technical knowledge in AI and machinelearning. Artificial neuralnetworks consist of interconnected layers of nodes, or “neurons” which work together to process and learn from data.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. It helps data scientists, AI developers, and ML engineers enhance their skills through engaging learning experiences and practical exercises.
Over the past decade, data science has undergone a remarkable evolution, driven by rapid advancements in machinelearning, artificial intelligence, and big data technologies. By 2017, deep learning began to make waves, driven by breakthroughs in neuralnetworks and the release of frameworks like TensorFlow.
GraphStorm is a low-code enterprise graph machinelearning (GML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. GraphStorm provides different ways to fine-tune the BERT models, depending on the task types. Dataset Num. of nodes Num. of edges Num.
Machinelearning , a subset of AI, involves three components: algorithms, training data, and the resulting model. An algorithm, essentially a set of procedures, learns to identify patterns from a large set of examples (training data). The culmination of this training is a machine-learning model.
Introduction to Generative AI: This course provides an introductory overview of Generative AI, explaining what it is and how it differs from traditional machinelearning methods. Participants will learn about the applications of Generative AI and explore tools developed by Google to create their own AI-driven applications.
These adapters allow BERT to be fine-tuned for specific downstream tasks while retaining most of its pre-trained parameters. These adapters allow BERT to be fine-tuned for specific downstream tasks while retaining most of its pre-trained parameters. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup.
Large language models (LLMs) , such as GPT-4 , BERT , Llama , etc., Simple rule-based chatbots, for example, could only provide predefined answers and could not learn or adapt. With advancements in machinelearning, dynamic memory became possible.
Normalization Trade-off: GPT models preserve formatting & nuance (more token complexity); BERT aggressively cleans text simpler tokens, reduced nuance, ideal for structured tasks. GPT typically preserves contractions, BERT-based models may split. Tokens: Fundamental unit that neuralnetworks process. GPT-4 and GPT-3.5
Deep NeuralNetworks (DNNs) have proven to be exceptionally adept at processing highly complicated modalities like these, so it is unsurprising that they have revolutionized the way we approach audio data modeling. Traditional machinelearning feature-based pipeline vs. end-to-end deep learning approach ( source ).
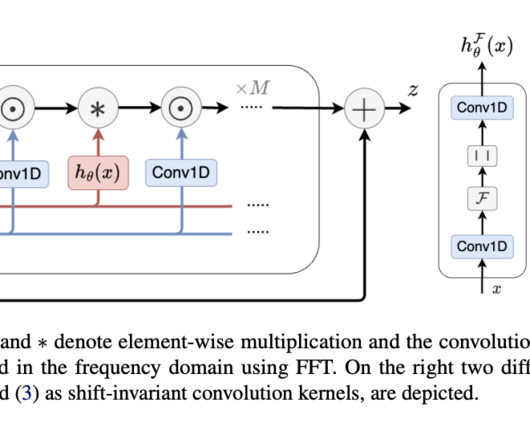
By leveraging a new data-dependent convolution layer, Orchid dynamically adjusts its kernel based on the input data using a conditioning neuralnetwork, allowing it to handle sequence lengths up to 131K efficiently. Compared to the BERT-base, the Orchid-BERT-base has 30% fewer parameters yet achieves a 1.0-point
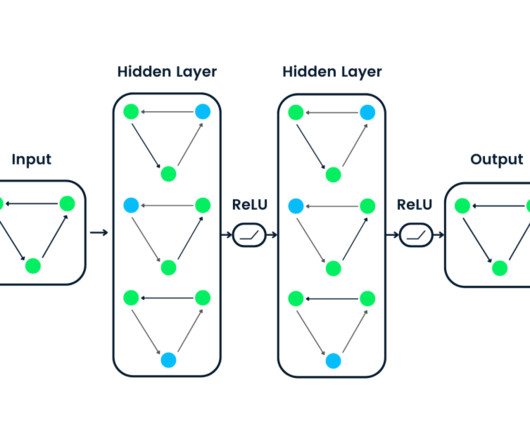
A Deep NeuralNetwork (DNN) is an artificial neuralnetwork that features multiple layers of interconnected nodes, also known as neurons. The deep aspect of DNNs comes from multiple hidden layers, which allow the network to learn and model complex patterns and relationships in data.
It’s the underlying engine that gives generative models the enhanced reasoning and deep learning capabilities that traditional machinelearning models lack. A foundation model is built on a neuralnetwork model architecture to process information much like the human brain does.
Introduction Deep Learning models transform how we approach complex problems, offering powerful tools to analyse and interpret vast amounts of data. These models mimic the human brain’s neuralnetworks, making them highly effective for image recognition, natural language processing, and predictive analytics.
Machinelearning models have heavily relied on labeled data for training, and traditionally speaking, training models on labeled data yields accurate results. To tackle the annotation issue, developers came up with the concept of SSL or Self Supervised Learning. They require a high amount of computational power.
In modern machinelearning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in Natural Language Processing, and Vision Transformers in computer vision tasks. So let’s get started. MambaOut: Is Mamba Really Needed for Vision?
BERT is a state-of-the-art algorithm designed by Google to process text data and convert it into vectors ([link]. What makes BERT special is, apart from its good results, the fact that it is trained over billions of records and that Hugging Face provides already a good battery of pre-trained models we can use for different ML tasks.
A significant breakthrough came with neuralnetworks and deep learning. Models like Google's NeuralMachine Translation (GNMT) and Transformer revolutionized language processing by enabling more nuanced, context-aware translations. IBM's Model 1 and Model 2 laid the groundwork for advanced systems.
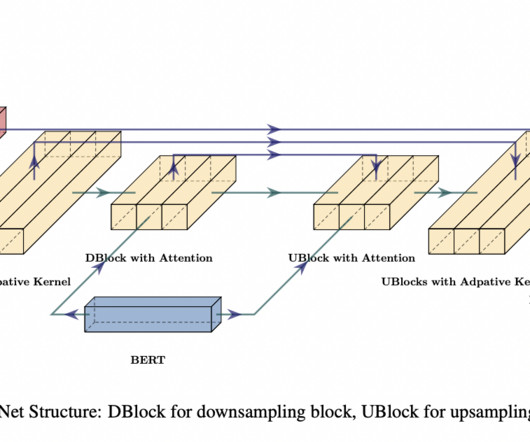
In machinelearning, a diffusion model is a generative model commonly used for image and audio generation tasks. This model consists of two primary modules: A pre-trained BERT model is employed to extract pertinent information from the input text, and A diffusion UNet model processes the output from BERT.
The Rise of AI Engineering andMLOps 20182019: Early discussions around MLOps and AI engineering were sparse, primarily focused on general machinelearning best practices. MLOps emerged as a necessary discipline to address the challenges of deploying and maintaining machinelearning models in production environments.
They said transformer models , large language models (LLMs), vision language models (VLMs) and other neuralnetworks still being built are part of an important new category they dubbed foundation models. Earlier neuralnetworks were narrowly tuned for specific tasks.
Deploying machinelearning models on edge devices poses significant challenges due to limited computational resources. These enhancements were consistent across models, ranging from transformer-based language models like BERT and GPT-NEOX to vision models like VGG. Check out the Paper.
Be sure to check out their talk, “ Getting Up to Speed on Real-Time MachineLearning ,” there! The benefits of real-time machinelearning are becoming increasingly apparent. Anomaly detection, including fraud detection and network intrusion monitoring, particularly exemplifies the challenges of real-time machinelearning.
By utilizing machinelearning algorithms , it produces new content, including images, text, and audio, that resembles existing data. Facebook's RoBERTa, built on the BERT architecture, utilizes deep learning algorithms to generate text based on given prompts.
SOTA (state-of-the-art) in machinelearning refers to the best performance achieved by a model or system on a given benchmark dataset or task at a specific point in time. The earlier models that were SOTA for NLP mainly fell under the traditional machinelearning algorithms. Citation: Article from IBM archives 2.
To support overarching pharmacovigilance activities, our pharmaceutical customers want to use the power of machinelearning (ML) to automate the adverse event detection from various data sources, such as social media feeds, phone calls, emails, and handwritten notes, and trigger appropriate actions.
Traditional machinelearning models, while effective in many scenarios, often struggle to process high-dimensional and unstructured data without extensive preprocessing and feature engineering. This gap has led to the evolution of deep learning models, designed to learn directly from raw data. What is Deep Learning?
Knowing how spaCy works means little if you don’t know how to apply core NLP skills like transformers, classification, linguistics, question answering, sentiment analysis, topic modeling, machine translation, speech recognition, named entity recognition, and others.
Parameter In the context of neuralnetworks, including LLMs, a parameter is a variable part of the model’s architecture learned from the training data. Parameters (like weights in neuralnetworks) are adjusted during training to reduce the difference between predicted and actual output.
The reranking model, often a neuralnetwork or a transformer-based architecture, is specifically trained to assess the relevance of a document to a given query. ColBERT: Efficient and Effective Late Interaction One of the standout models in the realm of reranking is ColBERT ( Contextualized Late Interaction over BERT ).
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































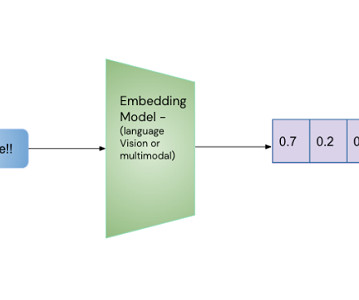





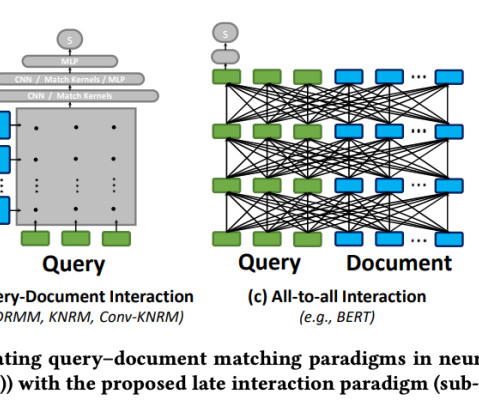







Let's personalize your content