This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction NaturalLanguageprocessing, a sub-field of machinelearning has gained. The post Amazon Product review Sentiment Analysis using BERT appeared first on Analytics Vidhya.
ModernBERT is an advanced iteration of the original BERT model, meticulously crafted to elevate performance and efficiency in naturallanguageprocessing (NLP) tasks.
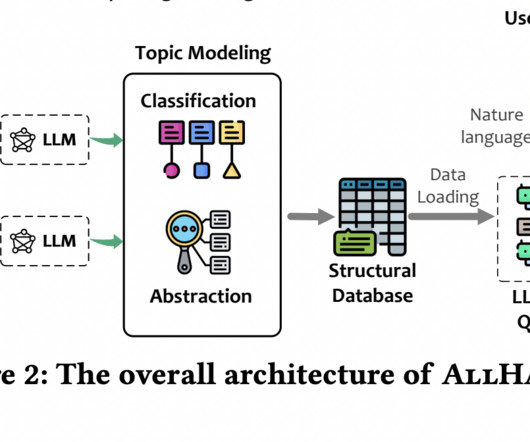
Introduction A highly effective method in machinelearning and naturallanguageprocessing is topic modeling. A corpus of text is an example of a collection of documents. This technique involves finding abstract subjects that appear there.
The Challenge Legal texts are uniquely challenging for naturallanguageprocessing (NLP) due to their specialized vocabulary, intricate syntax, and the critical importance of context. Terms that appear similar in general language can have vastly different meanings in legal contexts.
Machinelearning (ML) is a powerful technology that can solve complex problems and deliver customer value. This is why MachineLearning Operations (MLOps) has emerged as a paradigm to offer scalable and measurable values to Artificial Intelligence (AI) driven businesses.
Unlocking the Future of Language: The Next Wave of NLP Innovations Photo by Joshua Hoehne on Unsplash The world of technology is ever-evolving, and one area that has seen significant advancements is NaturalLanguageProcessing (NLP). A few years back, two groundbreaking models, BERT and GPT, emerged as game-changers.
With these advancements, it’s natural to wonder: Are we approaching the end of traditional machinelearning (ML)? In this article, we’ll look at the state of the traditional machinelearning landscape concerning modern generative AI innovations. What is Traditional MachineLearning?
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deep learning model designed explicitly for naturallanguageprocessing tasks like answering questions, analyzing sentiment, and translation.
Introduction Welcome into the world of Transformers, the deep learning model that has transformed NaturalLanguageProcessing (NLP) since its debut in 2017. These linguistic marvels, armed with self-attention mechanisms, revolutionize how machines understand language, from translating texts to analyzing sentiments.
Photo by Amr Taha™ on Unsplash In the realm of artificial intelligence, the emergence of transformer models has revolutionized naturallanguageprocessing (NLP). In this guide, we will explore how to fine-tune BERT, a model with 110 million parameters, specifically for the task of phishing URL detection.
They use real-time data and machinelearning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. This approach combines the efficiency of machinelearning with human judgment in the following way: The ML model processes and classifies transactions rapidly.
This is particularly useful for applications like machinelearning , where data points (such as images or text) can be represented as vectors in multi-dimensional spaces. Scalable for Large Datasets : As AI and machinelearning applications continue to grow, so does the amount of data they process.
I have written short summaries of 68 different research papers published in the areas of MachineLearning and NaturalLanguageProcessing. link] Investigating how much pre-trained language models capture syntactic information and how well are they able to detect syntactic errors out-of-the-box.
Source: totaljobs.com Introduction Transformers have become a powerful tool for different naturallanguageprocessing tasks. This article was published as a part of the Data Science Blogathon. The impressive performance of the transformer is mainly attributed to its self-attention mechanism.
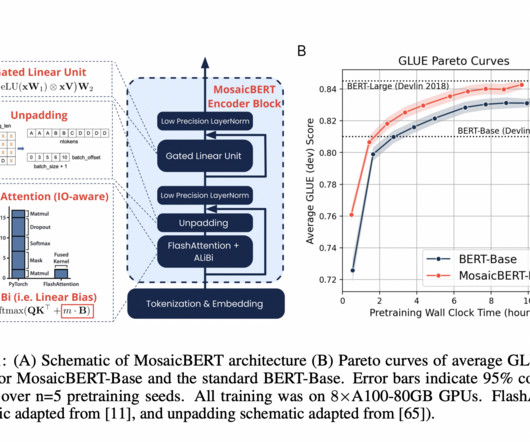
BERT is a language model which was released by Google in 2018. However, in the past half a decade, many significant advancements have been made with other types of architectures and training configurations that have yet to be incorporated into BERT. BERT-Base reached an average GLUE score of 83.2% hours compared to 23.35
Both BERT and GPT are based on the Transformer architecture. Word embedding is a technique in naturallanguageprocessing (NLP) where words are represented as vectors in a continuous vector space. It was the Attention Mechanism breakthrough that gave birth to Large Pre-Trained Models and Transformers.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
In our ever-evolving world, the significance of sequential decision-making (SDM) in machinelearning cannot be overstated. Much like how foundation models in language, such as BERT and GPT, have transformed naturallanguageprocessing by leveraging vast textual data, pretrained foundation models hold similar promise for SDM.
Introduction To Generative AI Image Source Course difficulty: Beginner-level Completion time: ~ 45 minutes Prerequisites: No What will AI enthusiasts learn? What is Generative Artificial Intelligence, how it works, what its applications are, and how it differs from standard machinelearning (ML) techniques.
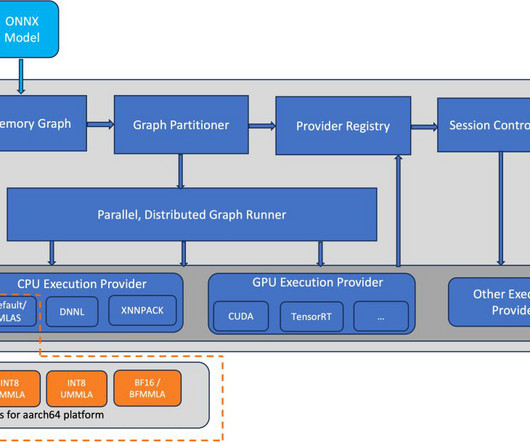
ONNX is an open source machinelearning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. You can see that for the BERT, RoBERTa, and GPT2 models, the throughput improvement is up to 65%. for the same fp32 model inference. for the same model inference.
Machinelearning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. Training experiment: Training BERT Large from scratch Training, as opposed to inference, is a finite process that is repeated much less frequently.
However, sifting through thousands of text-based reviews across multiple platforms and languages can be overwhelming and time-consuming, often leaving valuable insights buried beneath the sheer volume of data. Traditional methods for feedback analysis have relied heavily on machinelearning models and naturallanguageprocessing techniques.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. It helps data scientists, AI developers, and ML engineers enhance their skills through engaging learning experiences and practical exercises.
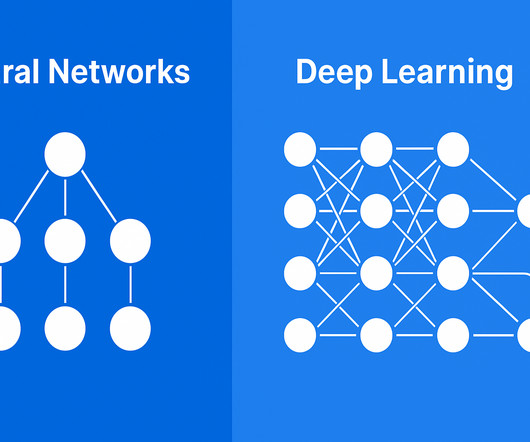
Neural Networks are foundational structures, while Deep Learning involves complex, layered networks like CNNs and RNNs, enabling advanced AI capabilities such as image recognition and naturallanguageprocessing. Introduction Deep Learning and Neural Networks are like a sports team and its star player.
Introduction to Generative AI: This course provides an introductory overview of Generative AI, explaining what it is and how it differs from traditional machinelearning methods. Participants will learn about the applications of Generative AI and explore tools developed by Google to create their own AI-driven applications.
These adapters allow BERT to be fine-tuned for specific downstream tasks while retaining most of its pre-trained parameters. These adapters allow BERT to be fine-tuned for specific downstream tasks while retaining most of its pre-trained parameters. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup.
Machinelearning models have heavily relied on labeled data for training, and traditionally speaking, training models on labeled data yields accurate results. To tackle the annotation issue, developers came up with the concept of SSL or Self Supervised Learning. They require a high amount of computational power.
Keras is a widely used machinelearning tool known for its high-level abstractions and ease of use, enabling rapid experimentation. Table 1 compares the average time per training or inference step for models like SAM, Gemma, BERT, and Mistral across different versions and frameworks of Keras.
It’s the underlying engine that gives generative models the enhanced reasoning and deep learning capabilities that traditional machinelearning models lack. A foundation model is built on a neural network model architecture to process information much like the human brain does.
In 2018 when BERT was introduced by Google, I cannot emphasize how much it changed the game within the NLP community. This ability to understand long-range dependencies helps transformers better understand the context of words and achieve superior performance in naturallanguageprocessing tasks.
Once a set of word vectors has been learned, they can be used in various naturallanguageprocessing (NLP) tasks such as text classification, language translation, and question answering. This allows BERT to learn a deeper sense of the context in which words appear.
In recent years, remarkable strides have been achieved in crafting extensive foundation language models for naturallanguageprocessing (NLP). These innovations have showcased strong performance in comparison to conventional machinelearning (ML) models, particularly in scenarios where labelled data is in short supply.
Figure 1: adversarial examples in computer vision (left) and naturallanguageprocessing tasks (right). Machinelearning models today perform reasonably well on perception tasks (image and speech recognition). So knowledge in language models is not the most accurate and reliable. Using the AllenNLP demo.
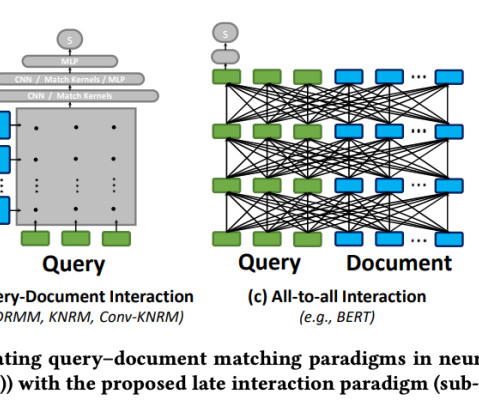
When it comes to naturallanguageprocessing (NLP) and information retrieval, the ability to efficiently and accurately retrieve relevant information is paramount. ColBERT: Efficient and Effective Late Interaction One of the standout models in the realm of reranking is ColBERT ( Contextualized Late Interaction over BERT ).
However, the computational complexity associated with these mechanisms scales quadratically with sequence length, which becomes a significant bottleneck when managing long-context tasks such as genomics and naturallanguageprocessing. Compared to the BERT-base, the Orchid-BERT-base has 30% fewer parameters yet achieves a 1.0-point
Through the use of these libraries, data scientists can easily create precise sentiment models using pre-trained models and sophisticated machinelearning frameworks. spaCy A well-known open-source naturallanguageprocessing package, spaCy is praised for its robustness and speed while processing massive amounts of text.
We are going to explore these and other essential questions from the ground up , without assuming prior technical knowledge in AI and machinelearning. The core process is a general technique known as self-supervised learning , a learning paradigm that leverages the inherent structure of the data itself to generate labels for training.
Naturallanguageprocessing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. BERT even accounts for the context of words, allowing for more accurate results related to respective queries and tasks.
Applications for naturallanguageprocessing (NLP) have exploded in the past decade. With the proliferation of AI assistants and organizations infusing their businesses with more interactive human-machine experiences, understanding how NLP techniques can be used to manipulate, analyze, and generate text-based data is essential.
Summary: Neural networks are a key technique in MachineLearning, inspired by the human brain. They consist of interconnected nodes that learn complex patterns in data. Reinforcement Learning: An agent learns to make decisions by receiving rewards or penalties based on its actions within an environment.
NLP, or NaturalLanguageProcessing, is a field of AI focusing on human-computer interaction using language. NLP aims to make computers understand, interpret, and generate human language. Recent NLP research has focused on improving few-shot learning (FSL) methods in response to data insufficiency challenges.
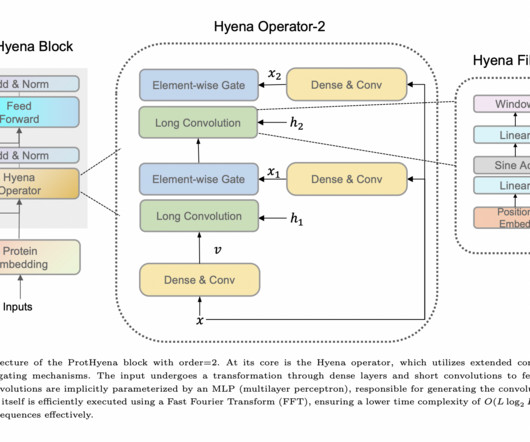
Understanding proteins is crucial for human biology and health, requiring advanced machine-learning models for protein representation. Self-supervised pre-training, inspired by naturallanguageprocessing, has significantly improved protein sequence representation.
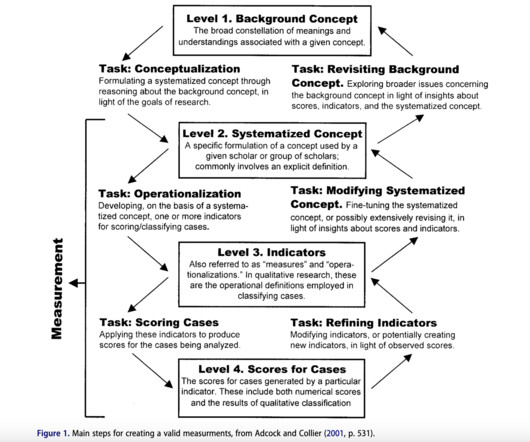
This study by researchers from Communication Science, Vrije Universiteit Amsterdam and Department of Politics, IR and Philosophy, Royal Holloway University of London addresses the critical issue of measurement validity in supervised machinelearning for social science tasks , particularly focusing on how biases in fine-tuning data impact validity.
Famous LLMs like GPT, BERT, PaLM, and LLaMa are revolutionizing the AI industry by imitating humans. The well-known chatbot called ChatGPT, based on GPT architecture and developed by OpenAI, imitates humans by generating accurate and creative content, answering questions, summarizing massive textual paragraphs, and language translation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content