This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon Introduction In 2018, a powerful Transformer-based machinelearning model, namely, BERT was developed by Jacob Devlin and his colleagues from Google for NLP applications.
Introduction Advances in machinelearning models that process language have been rapid in the last few years. A great example is the announcement that BERT models are now a significant force behind Google Search. This progress has left the research lab and is beginning to power some leading digital products.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Natural Language processing, a sub-field of machinelearning has gained. The post Amazon Product review Sentiment Analysis using BERT appeared first on Analytics Vidhya.
In this article, we will delve into how Legal-BERT [5], a transformer-based model tailored for legal texts, can be fine-tuned to classify contract provisions using the LEDGAR dataset [4] — a comprehensive benchmark dataset specifically designed for the legal field. Fine-tuning Legal-BERT for multi-class classification of legal provisions.
Introduction A highly effective method in machinelearning and natural language processing is topic modeling. A corpus of text is an example of a collection of documents. This technique involves finding abstract subjects that appear there.
ModernBERT is an advanced iteration of the original BERT model, meticulously crafted to elevate performance and efficiency in natural language processing (NLP) tasks.
Some people might use social media to spread false information. […] The post Building a Multi-Task Model for Fake and Hate Probability Prediction with BERT appeared first on Analytics Vidhya. However, it also has its darker side and that is the widespread of fake and hate content.
Machinelearning (ML) is a powerful technology that can solve complex problems and deliver customer value. This is why MachineLearning Operations (MLOps) has emerged as a paradigm to offer scalable and measurable values to Artificial Intelligence (AI) driven businesses.
The post Here are 7 Data Science Projects on GitHub to Showcase your MachineLearning Skills! Overview Working on Data Science projects is a great way to stand out from the competition Check out these 7 data science projects on. appeared first on Analytics Vidhya.
With these advancements, it’s natural to wonder: Are we approaching the end of traditional machinelearning (ML)? In this article, we’ll look at the state of the traditional machinelearning landscape concerning modern generative AI innovations. What is Traditional MachineLearning? What are its Limitations?
Generative AI is powered by advanced machinelearning techniques, particularly deep learning and neural networks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Roles like AI Engineer, MachineLearning Engineer, and Data Scientist are increasingly requiring expertise in Generative AI.
That’s a bit like what BERT does — except instead of people, it reads text. BERT, short for Bidirectional Encoder Representations from Transformers, is a powerful machinelearning model developed by Google. Let’s jump in and set up our sentiment analysis tool using BERT!
Introduction Large Language Model Operations (LLMOps) is an extension of MLOps, tailored specifically to the unique challenges of managing large-scale language models like GPT, PaLM, and BERT.
Overview This post is divided into five parts; they are: Why BERT Matters Understanding BERT's Input/Output Process Your First BERT Project Real-World Projects with BERT Named Entity Recognition System Why BERT Matters Imagine you're teaching someone a new language.
I have written short summaries of 68 different research papers published in the areas of MachineLearning and Natural Language Processing. Analysis shows that the final layers of ELECTRA and BERT capture subject-verb agreement errors best. They cover a wide range of different topics, authors and venues.
In this guide, we will explore how to fine-tune BERT, a model with 110 million parameters, specifically for the task of phishing URL detection. Machinelearning models, particularly those based on deep learning architectures like BERT, have shown great promise in identifying malicious URLs by analyzing their textual features.
They use real-time data and machinelearning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. This approach combines the efficiency of machinelearning with human judgment in the following way: The ML model processes and classifies transactions rapidly.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
Introduction Do you know, that you can automate machinelearning (ML) deployments and workflow? This can be done using MachineLearning Operations (MLOps), which are a set of rules and practices that simplify and automate ML deployments and workflows. Yes, you heard it right.
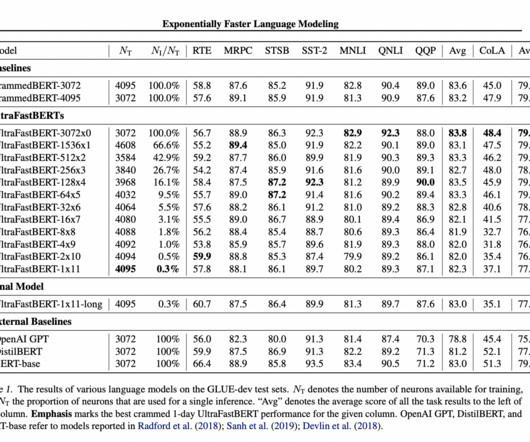
UltraFastBERT achieves comparable performance to BERT-base, using only 0.3% UltraFastBERT-1×11-long matches BERT-base performance with 0.3% In conclusion, UltraFastBERT is a modification of BERT that achieves efficient language modeling while using only a small fraction of its neurons during inference. of its neurons.
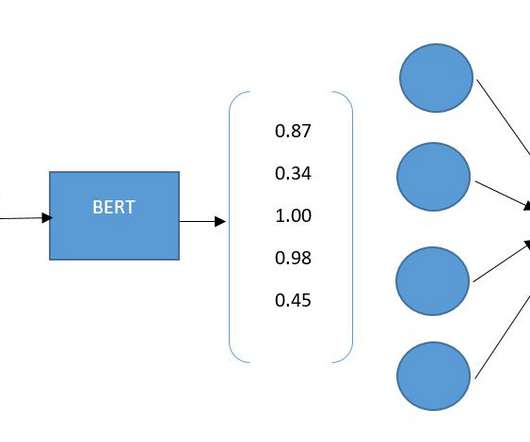
BERT is a language model which was released by Google in 2018. As such, it has been the powerhouse of numerous natural language processing (NLP) applications since its inception, and even in the age of large language models (LLMs), BERT-style encoder models are used in tasks like vector embeddings and retrieval augmented generation (RAG).
This is particularly useful for applications like machinelearning , where data points (such as images or text) can be represented as vectors in multi-dimensional spaces. Scalable for Large Datasets : As AI and machinelearning applications continue to grow, so does the amount of data they process.
A few years back, two groundbreaking models, BERT and GPT, emerged as game-changers. They revolutionized how machines understood and interacted with human language, making them more adept at tasks like reading, writing, and even conversing. Together, BERT and GPT set the stage, creating a new era in NLP. Their impact?
This post is in six parts; they are: The Complexity of NER Systems The Evolution of NER Technology BERT's Revolutionary Approach to NER Using DistilBERT with Hugging Face's Pipeline Using DistilBERT Explicitly with AutoModelForTokenClassification Best Practices for NER Implementation The challenge of Named Entity Recognition extends far beyond (..)
Both BERT and GPT are based on the Transformer architecture. Attention Mechanism Relation to Large Pre-Trained Language Models Large pre-trained language models, such as BERT and GPT, are built on transformer architectures and leverage attention mechanisms to learn contextual embeddings from vast amounts of text data.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deep learning model designed explicitly for natural language processing tasks like answering questions, analyzing sentiment, and translation.
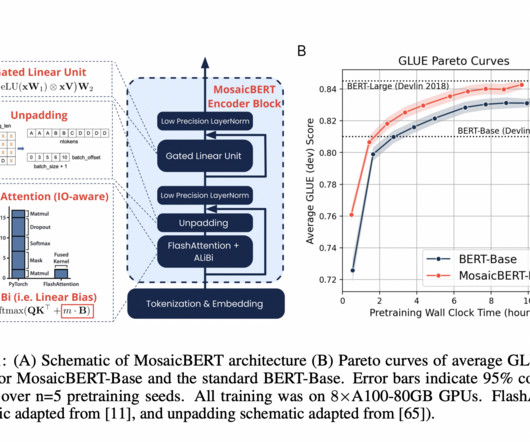
Machinelearning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. Training experiment: Training BERT Large from scratch Training, as opposed to inference, is a finite process that is repeated much less frequently.
Introduction Large Language Models (LLMs) are foundational machinelearning models that use deep learning algorithms to process and understand natural language. These models are trained on massive amounts of text data to learn patterns and entity relationships in the language.
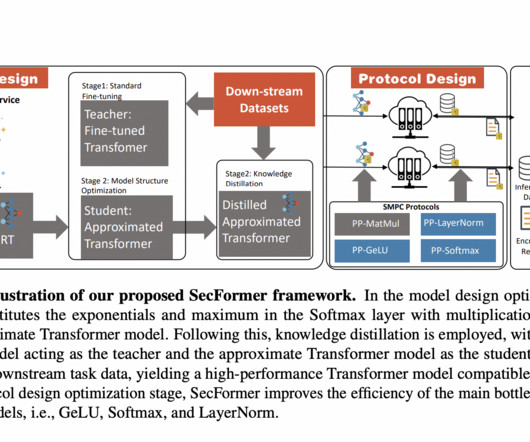
For instance, BERT BASE takes 71 seconds per sample via SMPC, compared to less than 1 second for plain-text inference ( shown in Figure 3 ). The post This AI Paper Unveils SecFormer: An Advanced MachineLearning Optimization Framework Balancing Privacy and Efficiency in Large Language Models appeared first on MarkTechPost.
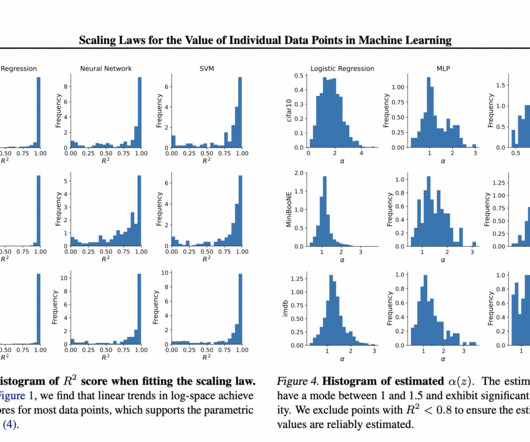
Machinelearning models for vision and language, have shown significant improvements recently, thanks to bigger model sizes and a huge amount of high-quality training data. Pre-trained embeddings like frozen ResNet-50 and BERT, are used to speed up training and prevent underfitting for CIFAR-10 and IMDB, respectively.
In our ever-evolving world, the significance of sequential decision-making (SDM) in machinelearning cannot be overstated. Much like how foundation models in language, such as BERT and GPT, have transformed natural language processing by leveraging vast textual data, pretrained foundation models hold similar promise for SDM.
Though Google was the one that first brought up the topic of Transformers through the BERT Model to […] The post PaLM AI | Google’s Home-Grown Generative AI appeared first on Analytics Vidhya.
We’ll delve deep into its workings and explore its most celebrated offspring: BERT, GPT, and T5. From writing coherent essays to understanding intricate nuances in diverse languages, they’re reshaping our interaction with machines. This is the kind of contextual understanding that BERT brings to the table.
While they share foundational principles of machinelearning, their objectives, methodologies, and outcomes differ significantly. Notably, BERT (Bidirectional Encoder Representations from Transformers), introduced by Devlin et al. This article will describe Generative AI and Predictive AI, drawing upon prominent academic papers.
Data science for mental health Data Analysis Techniques in MULTIWD We have used machinelearning and data science techniques to explore the wellness dimensions in rich and unstructured crude text. Using BERT and MentalBERT, we could capture these subtleties effectively by contextualizing each word based on the surrounding text.
Photo by Abiyyu Zahy on Unsplash If youre diving into AI and want to understand the secret sauce behind modern language models like ChatGPT or BERT, you need to get familiar with Transformers and their game-changing attention mechanism. Upgrade to access all of Medium.
Traditional methods for feedback analysis have relied heavily on machinelearning models and natural language processing techniques. Evaluations on datasets like GoogleStoreApp and ForumPost show that GPT-4 with few-shot learning achieves an impressive 85.7% Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup.
These adapters allow BERT to be fine-tuned for specific downstream tasks while retaining most of its pre-trained parameters. These adapters allow BERT to be fine-tuned for specific downstream tasks while retaining most of its pre-trained parameters. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup.
Transformers is an architecture of machinelearning models that uses the attention mechanism to process data. Many models are based on this architecture, like GPT, BERT, T5, and Llama. A lot of these models are similar to each other.
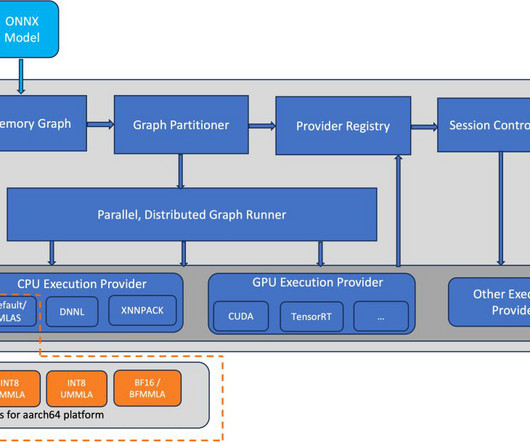
ONNX is an open source machinelearning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. You can see that for the BERT, RoBERTa, and GPT2 models, the throughput improvement is up to 65%. for the same fp32 model inference. for the same model inference.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. It helps data scientists, AI developers, and ML engineers enhance their skills through engaging learning experiences and practical exercises.
Graph Neural Networks (GNNs) have emerged as a powerful deep learning framework for graph machinelearning tasks. The tremendous success of LLMs has catalyzed explorations into leveraging their power for graph machinelearning tasks.
Machinelearning , a subset of AI, involves three components: algorithms, training data, and the resulting model. An algorithm, essentially a set of procedures, learns to identify patterns from a large set of examples (training data). The culmination of this training is a machine-learning model.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content