This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the ever-evolving landscape of artificial intelligence, the art of promptengineering has emerged as a pivotal skill set for professionals and enthusiasts alike. Promptengineering, essentially, is the craft of designing inputs that guide these AI systems to produce the most accurate, relevant, and creative outputs.
GPT-4: PromptEngineering ChatGPT has transformed the chatbot landscape, offering human-like responses to user inputs and expanding its applications across domains – from software development and testing to business communication, and even the creation of poetry. Imagine you're trying to translate English to French.
How Hugging Face Facilitates NLP and LLM Projects Hugging Face has made working with LLMs simpler by offering: A range of pre-trained models to choose from. A great resource available through Hugging Face is the Open LLM Leaderboard. We choose a BERT model fine-tuned on the SQuAD dataset.
However, the industry is seeing enough potential to consider LLMs as a valuable option. The following are a few potential benefits: Improved accuracy and consistency LLMs can benefit from the high-quality translations stored in TMs, which can help improve the overall accuracy and consistency of the translations produced by the LLM.
LLMs, like GPT-4 and Llama 3, have shown promise in handling such tasks due to their advanced language comprehension. Current LLM-based methods for anomaly detection include promptengineering, which uses LLMs in zero/few-shot setups, and fine-tuning, which adapts models to specific datasets.
LLM-as-Judge has emerged as a powerful tool for evaluating and validating the outputs of generative models. LLMs (and, therefore, LLM judges) inherit biases from their training data. In this article, well explore how enterprises can leverage LLM-as-Judge effectively , overcome its limitations, and implement best practices.
Among the daily deluge of news about new advancements in Large Language Models (LLMs), you might be asking, “how do I train my own?” ” Today, an LLM tailored to your specific needs is becoming an increasingly vital asset, but their ‘Large’ scale comes with a price.
Generative AI Types: Text to Text, Text to Image Transformers & LLM The paper “ Attention Is All You Need ” by Google Brain marked a shift in the way we think about text modeling. Large Language Models (LLMs) like GPT-4, Bard, and LLaMA, are colossal constructs designed to decipher and generate human language, code, and more.
More recent methods based on pre-trained language models like BERT obtain much better context-aware embeddings. Existing methods predominantly use smaller BERT-style architectures as the backbone model. They are unable to take advantage of more advanced LLMs and related techniques. Adding it provided negligible improvements.
I don’t want to undersell how impactful LLMs are for this sort of use-case. You can give an LLM a group of comments and ask it to summarize the texts or identify key themes. One vision for how LLMs can be used is what I’ll term LLM maximalist. If you have some task, you try to ask the LLM to do it as directly as possible.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. No training examples are needed in LLM Development but it’s needed in Traditional Development.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Transformer Models and BERT Model This course introduces the Transformer architecture and the BERT model, covering components like the self-attention mechanism.
Tools like LangChain , combined with a large language model (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart , simplify the implementation process. These multi-level approaches are advantageous when dealing with text with tokens longer than the limit of an LLM, enabling an understanding of complex narratives.
The role of promptengineer has attracted massive interest ever since Business Insider released an article last spring titled “ AI ‘PromptEngineer Jobs: $375k Salary, No Tech Backgrund Required.” It turns out that the role of a PromptEngineer is not simply typing questions into a prompt window.
Large language models (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. From chatbots to search engines to creative writing aids, LLMs are powering cutting-edge applications across industries. Promptengineering is crucial to steering LLMs effectively.
LangChain is an open-source framework that allows developers to build LLM-based applications easily. It provides for easily connecting LLMs with external data sources to augment the capabilities of these models and achieve better results. It teaches how to build LLM-powered applications using LangChain using hands-on exercises.
Whether you’re a developer seeking to incorporate LLMs into your existing systems or a business owner looking to take advantage of the power of NLP, this post can serve as a quick jumpstart. Operational efficiency Uses promptengineering, reducing the need for extensive fine-tuning when new categories are introduced.
Here are 11 pillars for building expertise in GenAI: Basics of Python- Python serves as a prominent programming language for working with large language models (LLMs) due to its versatility, extensive libraries, and community support. Learning the basics of transformers which is the core of LLM is imperative for a professional.
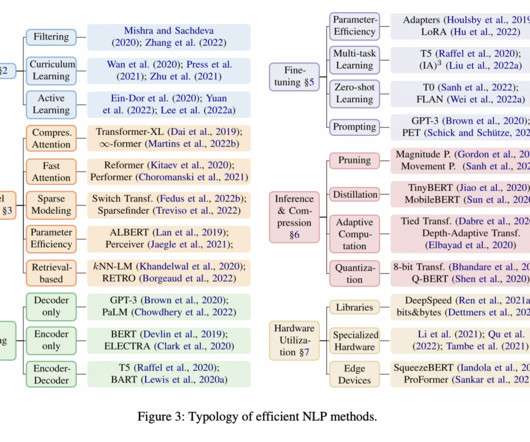
The 12 groups are as follows — Types of Models Common LLM Terms LLM Lifecycle Stages LLM Evaluations LLM Architecture Retrieval Augmented Generation (RAG) LLM Agents LMM Architecture Cost & Efficiency LLM Security Deployment & Inference A list of providers supporting LLMOps Like the generative AI space, this taxonomy is also evolving.
Large Language Models (LLMs) have revolutionized natural language processing in recent years. The pre-train and fine-tune paradigm, exemplified by models like ELMo and BERT, has evolved into prompt-based reasoning used by the GPT family. SMs play a crucial role in enhancing LLMs through data curation.
Although large language models (LLMs) had been developed prior to the launch of ChatGPT, the latter’s ease of accessibility and user-friendly interface took the adoption of LLM to a new level. It provides codes for working with various models, such as GPT-4, BERT, T5, etc., and explains how they work.
” BERT/BART/etc can be used in data-to-text, but may not be best approach Around 2020 LSTMs got replaced by fine-tuned transformer language models such as BERT and BART. This is a much better way to build data-to-text and other NLG systems, and I know of several production-quality NLG systems built using BART (etc).
TL;DR Hallucinations are an inherent feature of LLMs that becomes a bug in LLM-based applications. Effective mitigation strategies involve enhancing data quality, alignment, information retrieval methods, and promptengineering. What are LLM hallucinations? In 2022, when GPT-3.5
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. Deep learning techniques further enhanced this, enabling sophisticated image and speech recognition. Transformers and Advanced NLP Models : The introduction of transformer architectures revolutionized the NLP landscape.
We start off with a baseline foundation model from SageMaker JumpStart and evaluate it with TruLens , an open source library for evaluating and tracking large language model (LLM) apps. These functions can be implemented in several ways, including BERT-style models, appropriately promptedLLMs, and more.
Large Language Models In recent years, LLM development has seen a significant increase in size, as measured by the number of parameters. This trend started with models like the original GPT and ELMo, which had millions of parameters, and progressed to models like BERT and GPT-2, with hundreds of millions of parameters.
Large language model distillation isolates LLM performance on a specific task and mirrors its functionality in a smaller format. LLM distillation basics Multi-billion parameter language models pre-trained on millions of documents have changed the world. What is LLM distillation? How does LLM distillation work?
Large language model distillation isolates LLM performance on a specific task and mirrors its functionality in a smaller format. LLM distillation basics Multi-billion parameter language models pre-trained on millions of documents have changed the world. What is LLM distillation? How does LLM distillation work?
In Generative AI projects, there are five distinct stages in the lifecycle, centred around a Large Language Model 1️⃣ Pre-training : This involves building an LLM from scratch. The likes of BERT, GPT4, Llama 2, have undergone pre-training on a large corpus of data. The model generates a completion on the prompt.
Because no single large language model (LLM) is perfect for every task, we knew that building a personal AI assistant would require multiple LLMs optimized specifically for a variety of tasks. We performed content filtering and ranking using ColBERTv2 , a BERT-based retrieval model.
Combined with large language models (LLM) and Contrastive Language-Image Pre-Training (CLIP) trained with a large quantity of multimodality data, visual language models (VLMs) are particularly adept at tasks like image captioning, object detection and segmentation, and visual question answering.
It does a deep dive into two reinforcement learning algorithms used in training large language models (LLMs): Proximal Policy Optimization (PPO) Group Relative Policy Optimization (GRPO) LLM Training Overview The training of LLMs is divided into two phases: Pre-training: The model learns next token prediction using large-scale web data.
350x: Application Areas , Companies, Startups 3,000+: Prompts , PromptEngineering, & Prompt Lists 250+: Hardware, Frameworks , Approaches, Tools, & Data 300+: Achievements, Impacts on Society , AI Regulation, & Outlook 20x: What is Generative AI? In my view, this is one of the weirdest features of LLMs.
Users can easily constrain an LLM’s output with clever promptengineering. However, this approach comes with one big downside: the prompt must include at least one example for each potential output. Sends the prompt to the LLM. In-context learning. Over thousands of executions, those extra tokens can add up.
Users can easily constrain an LLM’s output with clever promptengineering. However, this approach comes with one big downside: the prompt must include at least one example for each potential output. Sends the prompt to the LLM. In-context learning. Over thousands of executions, those extra tokens can add up.
Users can easily constrain an LLM’s output with clever promptengineering. However, this approach comes with one big downside: the prompt must include at least one example for each potential output. Sends the prompt to the LLM. In-context learning. Over thousands of executions, those extra tokens can add up.
LLM Basics First and foremost, you need to understand the basics of generative AI and LLMs, such as key terminology, uses, potential issues, and primary frameworks. PromptEngineering Another buzzword you’ve likely heard of lately, promptengineering means designing inputs for LLMs once they’re developed.
In 2018, BERT-large made its debut with its 340 million parameters and innovative transformer architecture, setting the benchmark for performance on NLP tasks. AI21 Jurassic-2 Jumbo Instruct Jurassic-2 Jumbo Instruct is an LLM by AI21 Labs that can be applied to any language comprehension or generation task.
Introduction Large language models (LLMs) have emerged as a driving catalyst in natural language processing and comprehension evolution. LLM use cases range from chatbots and virtual assistants to content generation and translation services. Similarly, Google utilizes LLMOps for its next-generation LLM, PaLM 2.
At inference time, users provide “prompts” to the LLM—snippets of text that the model uses as a jumping-off point. First, the model converts each token in the prompt into its embedding. By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. The new tool caused a stir.
At inference time, users provide “prompts” to the LLM—snippets of text that the model uses as a jumping-off point. First, the model converts each token in the prompt into its embedding. By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. The new tool caused a stir.
This, coupled with the challenges of understanding AI concepts and complex algorithms, contributes to the learning curve associated with developing applications using LLMs. Nevertheless, the integration of LLMs with other tools to form LLM-powered applications could redefine our digital landscape.
Introduction to LLMsLLM in the sphere of AI Large language models (often abbreviated as LLMs) refer to a type of artificial intelligence (AI) model typically based on deep learning architectures known as transformers. It has become the backbone of many successful language models, like GPT-3, BERT, and their variants.
We must create new tools and best practices to manage the LLM application lifecycle to address these issues. " The LLMOps Steps LLMs, sophisticated artificial intelligence (AI) systems trained on enormous text and code datasets, have changed the game in various fields, from natural language processing to content generation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































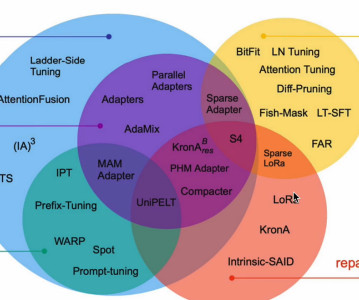
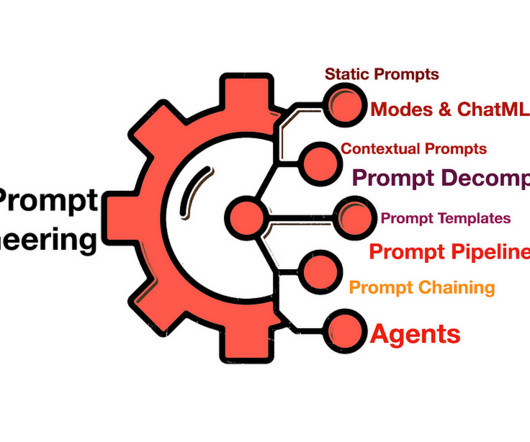









Let's personalize your content