This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In recent years, Natural Language Processing (NLP) has undergone a pivotal shift with the emergence of Large Language Models (LLMs) like OpenAI's GPT-3 and Google’s BERT. Using their extensive training data, LLM-based agents deeply understand language patterns, information, and contextual nuances.
LLMs are deep neural networks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). However, LLMs are also very different from other models.
🔎 Decoding LLM Pipeline Step 1: Input Processing & Tokenization 🔹 From Raw Text to Model-Ready Input In my previous post, I laid out the 8-step LLM pipeline, decoding how large language models (LLMs) process language behind the scenes. GPT typically preserves contractions, BERT-based models may split.
With the advent of generative models (LLMs), the importance of effective retrieval has only grown. This comprehensive documentation serves as the foundational knowledge base for code generation by providing the LLM with the necessary context to understand and generate SimTalk code.
As we wrap up October, we’ve compiled a bunch of diverse resources for you — from the latest developments in generative AI to tips for fine-tuning your LLM workflows, from building your own NotebookLM clone to instruction tuning. We have long supported RAG as one of the most practical ways to make LLMs more reliable and customizable.
Speculative decoding applies the principle of speculative execution to LLM inference. The process involves two main components: A smaller, faster "draft" model The larger target LLM The draft model generates multiple tokens in parallel, which are then verified by the target model.
LLM watermarking, which integrates imperceptible yet detectable signals within model outputs to identify text generated by LLMs, is vital for preventing the misuse of large language models. Conversely, the Christ Family alters the sampling process during LLM text generation, embedding a watermark by changing how tokens are selected.
I don’t want to undersell how impactful LLMs are for this sort of use-case. You can give an LLM a group of comments and ask it to summarize the texts or identify key themes. One vision for how LLMs can be used is what I’ll term LLM maximalist. If you have some task, you try to ask the LLM to do it as directly as possible.
The quintessential examples for this distinction are: The BERT model, which stands for Bidirectional Encoder Representations from Transformers. The Race for the Largest Language Model In recent years, the development of LLMs has been characterized by a dramatic increase in size, as measured by the number of parameters. Et voilà !
You know, that thing OpenAI used to make GPT3.5 As an early adopter of the BERT models in 2017, I hadn’t exactly been convinced computers could interpret human language with similar granularity and contextuality as people do. Author(s): Tim Cvetko Originally published on Towards AI. into ChatGPT? Forget Human Labelers!
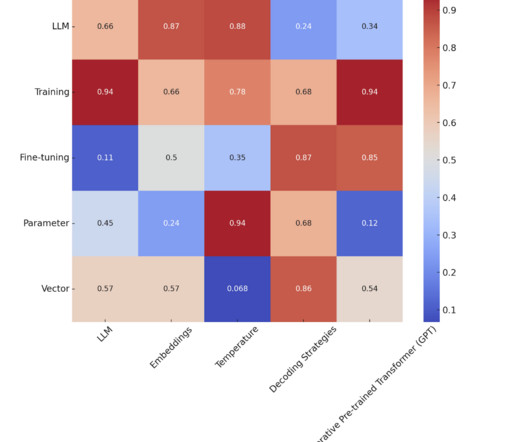
Heatmap representing the relative importance of terms in the context of LLMs Source: marktechpost.com 1. LLM (Large Language Model) Large Language Models (LLMs) are advanced AI systems trained on extensive text datasets to understand and generate human-like text. These models typically involve an encoder and a decoder.
GPT 3 and similar Large Language Models (LLM) , such as BERT , famous for its bidirectional context understanding, T-5 with its text-to-text approach, and XLNet , which combines autoregressive and autoencoding models, have all played pivotal roles in transforming the Natural Language Processing (NLP) paradigm.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. No training examples are needed in LLM Development but it’s needed in Traditional Development.
However, the meteoric rise of large language models (LLMs) like GPT-3 poses a new challenge for the tech titan. Lacking an equally buzzworthy in-house LLM, AWS risks losing ground to rivals rushing their own models to market. And AWS isn’t sitting idle on the LLM front, either.
OpenAI has been instrumental in developing revolutionary tools like the OpenAI Gym, designed for training reinforcement algorithms, and GPT-n models. One such model that has garnered considerable attention is OpenAI's ChatGPT , a shining exemplar in the realm of Large Language Models.
Soon to be followed by large general language models like BERT (Bidirectional Encoder Representations from Transformers). In hindsight, these companies might have been too early in their evolution, as they missed the boat by being early on what groundbreaking advances OpenAI brought to the world.
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. link] The process can be categorized into three agents: Execution Agent : The heart of the system, this agent leverages OpenAI’s API for task processing. Below is a demonstration of the BabyAGI using this link.
It’s a well-established principle: any LLM, whether open-source or proprietary, isn’t dependable without a RAG. with: New OpenAI Whisper, Embeddings and Completions! Anticipate swifter inferences, seamless optimizations, and quantization for exporting LLM models. BERT, XLNet, RoBERTa) under the same model setting.
Below, we'll give you the basic know-how you need to understand LLMs, how they work, and the best models in 2023. A large language model (often abbreviated as LLM) is a machine-learning model designed to understand, generate, and interact with human language. GPT-4 GPT-4 is OpenAI's latest (and largest) model.
The well-known large language models such as GPT, DALLE, and BERT perform extraordinary tasks and ease lives. It integrates with the Hugging Face’s Transformers, OpenAI API, and Langchain. Their recent impact has helped contribute to a wide range of industries like healthcare, finance, education, entertainment, etc.
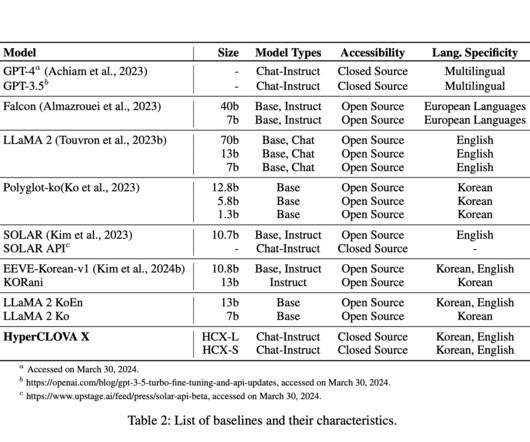
In contrast, closed source LLMs treat model architecture and weights as proprietary assets. Commercial entities like Anthropic, DeepMind, and OpenAI develop them internally. This customizability allows open source LLMs to better serve specialized domains like biomedical research, code generation, and education.
Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for natural language processing (NLP) tasks. One of the more popular and useful of the transformer architectures, Bidirectional Encoder Representations from Transformers (BERT), is a language representation model that was introduced in 2018.
Applications & Impact Meta's Llama is compared to other prominent LLMs, such as BERT and GPT-3. Privacy Control: Llama's adaptability and flexibility make it potentially disruptive to the current leaders in LLM, such as OpenAI and Google.
Large Language Models (LLMs) have successfully proven to be the best innovation in the field of Artificial Intelligence. From BERT, PaLM, and GPT to LLaMa DALL-E, these models have shown incredible performance in understanding and generating language for the purpose of imitating humans. Check out the Paper.
As the course progresses, “Language Models and Transformer-based Generative Models” take center stage, shedding light on different language models, the Transformer architecture, and advanced models like GPT and BERT. Expert Creators : Developed by renowned professionals from OpenAI and DeepLearning.AI.
From education and finance to healthcare and media, LLMs are contributing to almost every domain. Famous LLMs like GPT, BERT, PaLM, and LLaMa are revolutionizing the AI industry by imitating humans. Vespa – Vespa.ai
TL;DR Hallucinations are an inherent feature of LLMs that becomes a bug in LLM-based applications. This “making up” event is what we call a hallucination, a term popularized by Andrej Karpathy in 2015 in the context of RNNs and extensively used nowadays for large language models (LLMs). What are LLM hallucinations?
Instead of navigating complex menus or waiting on hold, they can engage in a conversation with a chatbot powered by an LLM. The LLM analyzes the customer’s query, processes the natural language input, and generates a contextual response in real-time.
With the release of the latest chatbot developed by OpenAI called ChatGPT, the field of AI has taken over the world as ChatGPT, due to its GPT’s transformer architecture, is always in the headlines. The LLM consumes the text data during training and tries to anticipate the following word or series of words depending on the context.
With its distinctive linguistic structure and deep cultural context, Korean has often posed a challenge for conventional English-based LLMs, prompting a shift toward more inclusive and culturally aware AI research and development. Codex further explores the integration of code generation within LLMs.
Applications of LLMs The chart below summarises the present state of the Large Language Model (LLM) landscape in terms of features, products, and supporting software. Types of LLM Large language models It is not uncommon for large language models to be trained using petabytes or more of text data, making them tens of terabytes in size.
The study demonstrated the effectiveness of this new method by applying it to several well-known models, including variations of Google’s BERT and OpenAI’s GPT series. This advancement is crucial as LLMs are increasingly used in various applications, from automated writing aids to sophisticated conversational agents.
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. Let’s delve into the role of transformers in NLP and elucidate the process of training LLMs using this innovative architecture.
Created Using Midjourney Next Week in The Sequence: Edge 451: Explores the ideas behind multi-teacher distillation including the MT-BERT paper. It also covers the Portkey framework for LLM guardrailing. Judge Arena Hugging Face released JudgeArena, a platform for benchmarking LLM-as-a-Judge models —> Read more.
Since its release on November 30, 2022 by OpenAI , the ChatGPT public demo has taken the world by storm. An Associate Professor at Maryland has estimated that OpenAI spends $3 million per month to run ChatGPT. and is trained in a manner similar to OpenAI’s earlier InstructGPT, but on conversations.
You could use LLM models like ChatGPT to create horoscopes (which it does quite successfully), or for something more practical (like work). This part is usually done using an LLM like OpenAI. Of course, an LLM. instead of just fragmented pieces. Image by DALL-E 3 So, why do we need RAG?
Large language model distillation isolates LLM performance on a specific task and mirrors its functionality in a smaller format. LLM distillation basics Multi-billion parameter language models pre-trained on millions of documents have changed the world. What is LLM distillation? How does LLM distillation work?
Large language model distillation isolates LLM performance on a specific task and mirrors its functionality in a smaller format. LLM distillation basics Multi-billion parameter language models pre-trained on millions of documents have changed the world. What is LLM distillation? How does LLM distillation work?
It’s a well-established principle: any LLM, whether open-source or proprietary, isn’t dependable without a RAG. with: New OpenAI Whisper, Embeddings and Completions! Anticipate swifter inferences, seamless optimizations, and quantization for exporting LLM models. BERT, XLNet, RoBERTa) under the same model setting.
These models are contributing to some remarkable economic and societal transformations, the best example of which is the well-known ChatGPT developed by OpenAI, which has had millions of users ever since its release, with the number increasing exponentially, if not the same. Other LLMs, like PaLM, Chinchilla, BERT, etc.,
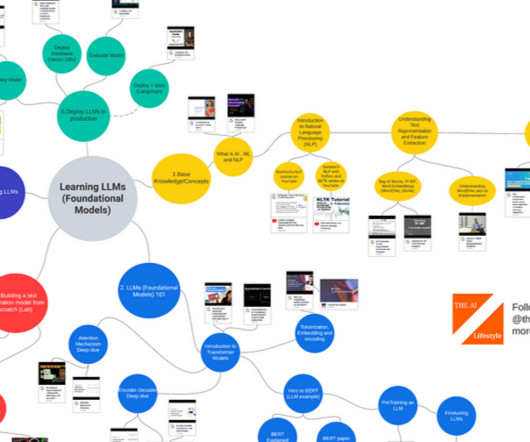
Learning Large Language Models The LLM (Foundational Models) space has seen tremendous and rapid growth. I used this foolproof method of consuming the right information and ended up publishing books , artworks , Podcasts and even an LLM powered consumer facing app ranked #40 on the app store. YouTube BERT Research — Ep.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
It does a deep dive into two reinforcement learning algorithms used in training large language models (LLMs): Proximal Policy Optimization (PPO) Group Relative Policy Optimization (GRPO) LLM Training Overview The training of LLMs is divided into two phases: Pre-training: The model learns next token prediction using large-scale web data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content