This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The ability to effectively represent and reason about these intricate relational structures is crucial for enabling advancements in fields like network science, cheminformatics, and recommender systems. Graph NeuralNetworks (GNNs) have emerged as a powerful deep learning framework for graph machine learning tasks.
The ever-growing presence of artificial intelligence also made itself known in the computing world, by introducing an LLM-powered Internet search tool, finding ways around AIs voracious data appetite in scientific applications, and shifting from coding copilots to fully autonomous coderssomething thats still a work in progress. Perplexity.ai
Large language models (LLMs) , such as GPT-4 , BERT , Llama , etc., Technologies such as Recurrent NeuralNetworks (RNNs) and transformers introduced the ability to process sequences of data and paved the way for more adaptive AI. Artificial intelligence (AI) fundamentally transforms how we live, work, and communicate.
🔎 Decoding LLM Pipeline Step 1: Input Processing & Tokenization 🔹 From Raw Text to Model-Ready Input In my previous post, I laid out the 8-step LLM pipeline, decoding how large language models (LLMs) process language behind the scenes. GPT typically preserves contractions, BERT-based models may split.
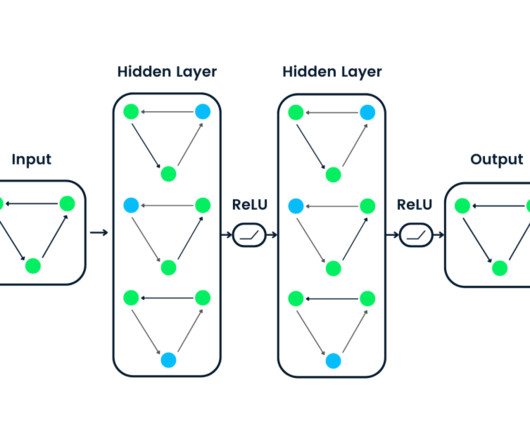
These architectures are based on artificial neuralnetworks , which are computational models loosely inspired by the structure and functioning of biological neuralnetworks, such as those in the human brain. A simple artificial neuralnetwork consisting of three layers.
Unlike sequential models, LLMs optimize resource distribution, resulting in accelerated data extraction tasks. Source: A pipeline on Generative AI This figure of a generative AI pipeline illustrates the applicability of models such as BERT, GPT, and OPT in data extraction.
But more than MLOps is needed for a new type of ML model called Large Language Models (LLMs). LLMs are deep neuralnetworks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code.
LLM-as-Judge has emerged as a powerful tool for evaluating and validating the outputs of generative models. LLMs (and, therefore, LLM judges) inherit biases from their training data. In this article, well explore how enterprises can leverage LLM-as-Judge effectively , overcome its limitations, and implement best practices.
In this article, we delve into 25 essential terms to enhance your technical vocabulary and provide insights into the mechanisms that make LLMs so transformative. Heatmap representing the relative importance of terms in the context of LLMs Source: marktechpost.com 1.
Prompt 1 : “Tell me about Convolutional NeuralNetworks.” ” Response 1 : “Convolutional NeuralNetworks (CNNs) are multi-layer perceptron networks that consist of fully connected layers and pooling layers. They are commonly used in image recognition tasks. .”
The Scale and Complexity of LLMs The scale of these models adds to their complexity. Each parameter interacts in intricate ways within the neuralnetwork, contributing to emergent capabilities that aren’t predictable by examining individual components alone. Impact of the LLM Black Box Problem 1.
GPT 3 and similar Large Language Models (LLM) , such as BERT , famous for its bidirectional context understanding, T-5 with its text-to-text approach, and XLNet , which combines autoregressive and autoencoding models, have all played pivotal roles in transforming the Natural Language Processing (NLP) paradigm.
As the demand for large language models (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. NVIDIA's TensorRT-LLM steps in to address this challenge by providing a set of powerful tools and optimizations specifically designed for LLM inference.
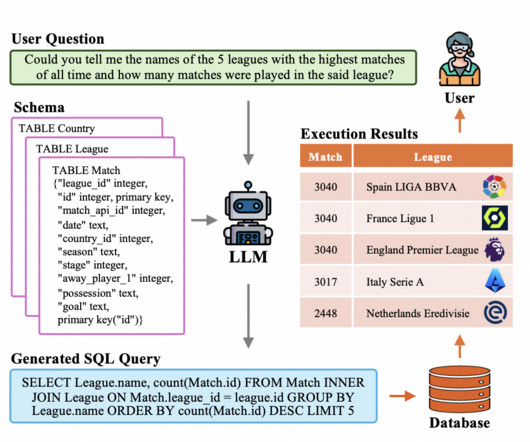
Traditional text-to-SQL systems using deep neuralnetworks and human engineering have succeeded. The LLMs have demonstrated the ability to execute a solid vanilla implementation thanks to the improved semantic parsing capabilities made possible by the larger training corpus. Join our Telegram Channel and LinkedIn Gr oup.
Furthermore, empirically enumerating all the possible designs for training LLMs over 100B parameters is computationally unaffordable which makes it even more critical to come up with a pre-training method for large scale LLM frameworks. With that being said, let’s have a look at GLM-130B’s architecture.
Transformer Models and BERT Model : In this course, participants delve into the specifics of Transformer models and the Bidirectional Encoder Representations from Transformers (BERT) model. Introduction to Large Language Models: This module explores Large Language Models (LLMs) and their applications.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. No training examples are needed in LLM Development but it’s needed in Traditional Development.
Deep NeuralNetworks (DNNs) have proven to be exceptionally adept at processing highly complicated modalities like these, so it is unsurprising that they have revolutionized the way we approach audio data modeling. At its core, it's an end-to-end neuralnetwork-based approach. The EnCodec architecture ( source ).
Large Language Models (LLMs) like ChatGPT, Google’s Bert, Gemini, Claude Models, and others have emerged as central figures, redefining our interaction with digital interfaces. LLM is an AI system designed to understand, generate, and work with human language on a large scale. What are Large Language Models?
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. It covers how to develop NLP projects using neuralnetworks with Vertex AI and TensorFlow. It includes lessons on vector search and text embeddings, practical demos, and a hands-on lab.
A foundation model is built on a neuralnetwork model architecture to process information much like the human brain does. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. An open-source model, Google created BERT in 2018.
” These limitations have spurred researchers to explore innovative solutions that can enhance LLM performance without the need for extensive retraining. Transformer architecture has emerged as a major leap in natural language processing, significantly outperforming earlier recurrent neuralnetworks.
NeuralNetworks & Deep Learning : Neuralnetworks marked a turning point, mimicking human brain functions and evolving through experience. Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication.
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. Let’s delve into the role of transformers in NLP and elucidate the process of training LLMs using this innovative architecture.
RAG is a technique that extends the knowledge and capabilities of large language models (LLMs) by providing them with access to external information sources, such as databases or document collections.
Below, we'll give you the basic know-how you need to understand LLMs, how they work, and the best models in 2023. A large language model (often abbreviated as LLM) is a machine-learning model designed to understand, generate, and interact with human language. LLMs are built upon deep learning, a subset of machine learning.
Large Language Models (LLMs) are a type of neuralnetwork model trained on vast amounts of text data. Some popular examples of LLMs include GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), and XLNet. Why Kubernetes for LLM Deployment?
Created Using Midjourney Next Week in The Sequence: Edge 451: Explores the ideas behind multi-teacher distillation including the MT-BERT paper. It also covers the Portkey framework for LLM guardrailing. Judge Arena Hugging Face released JudgeArena, a platform for benchmarking LLM-as-a-Judge models —> Read more.
NeuralNetworks and Transformers What determines a language model's effectiveness? The performance of LMs in various tasks is significantly influenced by the size of their architectures, which are based on artificial neuralnetworks. A simple artificial neuralnetwork with three layers.
Models such as GPT, BERT , and more recently Llama , Mistral are capable of understanding and generating human-like text with unprecedented fluency and coherence. NVIDIA TensorRT , a high-performance deep learning inference optimizer and runtime, plays a vital role in accelerating LLM inference on CUDA-enabled GPUs.
Transformers, BERT, and GPT The transformer architecture is a neuralnetwork architecture that is used for natural language processing (NLP) tasks. BERT is trained on sequences where some of the words in a sentence are masked, and it has to fill in those words taking into account both the words before and after the masked words.
Large language models (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. From chatbots to search engines to creative writing aids, LLMs are powering cutting-edge applications across industries. LLMs utilize embeddings to understand word context.
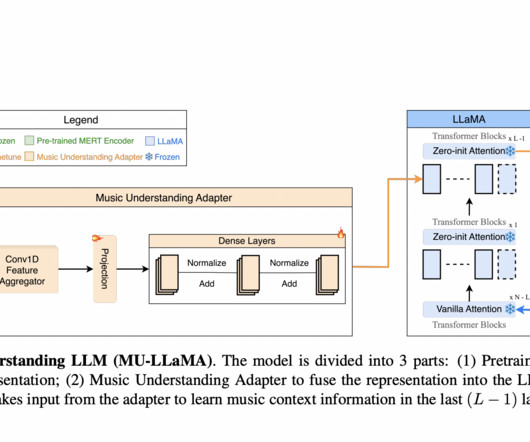
After that, these embeddings are processed by a thick neuralnetwork with three sub-blocks and a 1D convolutional layer. link] BLEU, METEOR, ROUGE-L, and BERT-Score are the main text generation measures used to assess MU-LLaMA’s performance.
Many frameworks employ a generic neuralnetwork for a wide range of image restoration tasks, but these networks are each trained separately. These deep learning image restoration models propose to use neuralnetworks based on Transformers and Convolutional NeuralNetworks.
The journey continues with “NLP and Deep Learning,” diving into the essentials of Natural Language Processing , deep learning's role in NLP, and foundational concepts of neuralnetworks. It addresses how input prompts function within language models like ChatGPT.
Traditional neuralnetwork models like RNNs and LSTMs and more modern transformer-based models like BERT for NER require costly fine-tuning on labeled data for every custom entity type. Amazon Bedrock – Calls an LLM to identify entities of interest from the given context.
Unigrams, N-grams, exponential, and neuralnetworks are valid forms for the Language Model. Applications of LLMs The chart below summarises the present state of the Large Language Model (LLM) landscape in terms of features, products, and supporting software. It is pre-trained using a generalized autoregressive model.
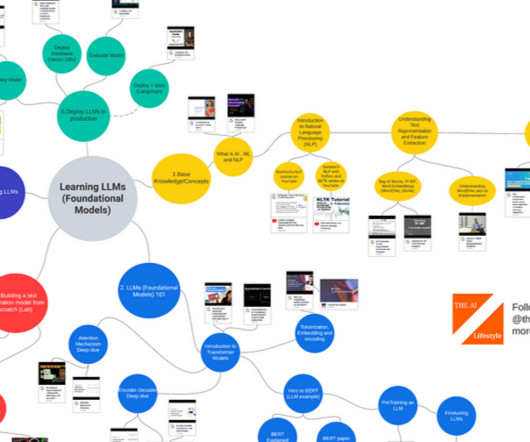
Learning Large Language Models The LLM (Foundational Models) space has seen tremendous and rapid growth. I used this foolproof method of consuming the right information and ended up publishing books , artworks , Podcasts and even an LLM powered consumer facing app ranked #40 on the app store. Transformer NeuralNetworks — EXPLAINED!
The underlying architecture of LLMs typically involves a deep neuralnetwork with multiple layers. Based on the discovered patterns and connections found in the training data, this network analyses the input text and produces predictions. Selecting the appropriate model architecture is essential for training an LLM.
link] The paper investigates LLM robustness to prompt perturbations, measuring how much task performance drops for different models with different attacks. link] The paper proposes query rewriting as the solution to the problem of LLMs being overly affected by irrelevant information in the prompts. ArXiv 2023. Oliveira, Lei Li.
At their core, LLMs are built upon deep neuralnetworks, enabling them to process vast amounts of text and learn complex patterns. Instead of navigating complex menus or waiting on hold, they can engage in a conversation with a chatbot powered by an LLM.
Large language model distillation isolates LLM performance on a specific task and mirrors its functionality in a smaller format. LLM distillation basics Multi-billion parameter language models pre-trained on millions of documents have changed the world. What is LLM distillation? How does LLM distillation work?
Large language model distillation isolates LLM performance on a specific task and mirrors its functionality in a smaller format. LLM distillation basics Multi-billion parameter language models pre-trained on millions of documents have changed the world. What is LLM distillation? How does LLM distillation work?
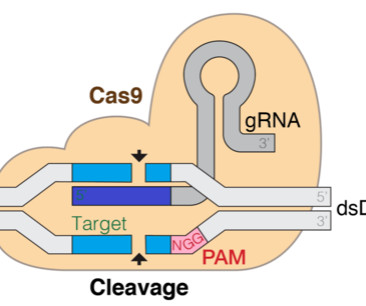
In this post, we adopt a pre-trained genomic LLMs for gRNA efficiency prediction. The idea is to treat a computer designed gRNA as a sentence, and fine-tune the LLM to perform sentence-level regression tasks analogous to sentiment analysis. The backbone is a BERT architecture made up of 12 encoding layers.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content