This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the advent of generative models (LLMs), the importance of effective retrieval has only grown. This comprehensive documentation serves as the foundational knowledge base for code generation by providing the LLM with the necessary context to understand and generate SimTalk code.
🔎 Decoding LLM Pipeline Step 1: Input Processing & Tokenization 🔹 From Raw Text to Model-Ready Input In my previous post, I laid out the 8-step LLM pipeline, decoding how large language models (LLMs) process language behind the scenes. GPT typically preserves contractions, BERT-based models may split.
However, the industry is seeing enough potential to consider LLMs as a valuable option. The following are a few potential benefits: Improved accuracy and consistency LLMs can benefit from the high-quality translations stored in TMs, which can help improve the overall accuracy and consistency of the translations produced by the LLM.
In the age of data-driven artificial intelligence, LLMs like GPT-3 and BERT require vast amounts of well-structured data from diverse sources to improve performance across various applications. It not only collects data from websites but also processes and cleans it into LLM-friendly formats like JSON, cleaned HTML, and Markdown.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Participants learn to build metadata for documents containing text and images, retrieve relevant text chunks, and print citations using Multimodal RAG with Gemini.
Some popular examples of LLMs include GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), and XLNet. LLMs have achieved remarkable performance in various NLP tasks, such as text generation, language translation, and question answering. Why Kubernetes for LLM Deployment?
In this post, we use a Hugging Face BERT-Large model pre-training workload as a simple example to explain how to useTrn1 UltraClusters. Launch your training job We use the Hugging Face BERT-Large Pretraining Tutorial as an example to run on this cluster. Each compute node has Neuron tools installed, such as neuron-top.
And Miso had already built an early LLM-based search engine using the open-source BERT model that delved into research papers—it could take a query in natural language and find a snippet of text in a document that answered that question with surprising reliability and smoothness.
Large language models (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. From chatbots to search engines to creative writing aids, LLMs are powering cutting-edge applications across industries. LLMs utilize embeddings to understand word context.
link] The paper investigates LLM robustness to prompt perturbations, measuring how much task performance drops for different models with different attacks. link] The paper proposes query rewriting as the solution to the problem of LLMs being overly affected by irrelevant information in the prompts. ArXiv 2023. Oliveira, Lei Li.
Whether you’re a developer seeking to incorporate LLMs into your existing systems or a business owner looking to take advantage of the power of NLP, this post can serve as a quick jumpstart. The raw data is processed by an LLM using a preconfigured user prompt. The LLM generates output based on the user prompt.
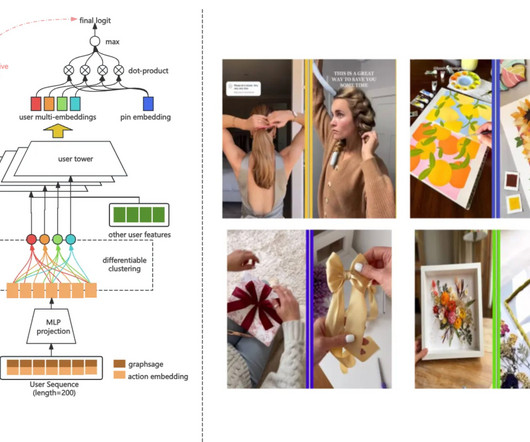
device type, location), while the Pin tower encodes visual features(CNN-extracted embeddings), textual metadata(BERT embeddings), and statistical features(e.g., Fundamentally, the AI co-scientist system represents an improved implementation of multi-agent LLM network built upon the Gemini 2.0 historical engagement rates).
The following is a high-level overview of how it works conceptually: Separate encoders – These models have separate encoders for each modality—a text encoder for text (for example, BERT or RoBERTa), image encoder for images (for example, CNN for images), and audio encoders for audio (for example, models like Wav2Vec).
Amazon SageMaker Clarify now provides AWS customers with foundation model (FM) evaluations, a set of capabilities designed to evaluate and compare model quality and responsibility metrics for any LLM, in minutes. FMEval helps in measuring evaluation dimensions such as accuracy, robustness, bias, toxicity, and factual knowledge for any LLM.
Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. LLMs’ generative abilities make them popular for text synthesis, summarization, machine translation, and more.
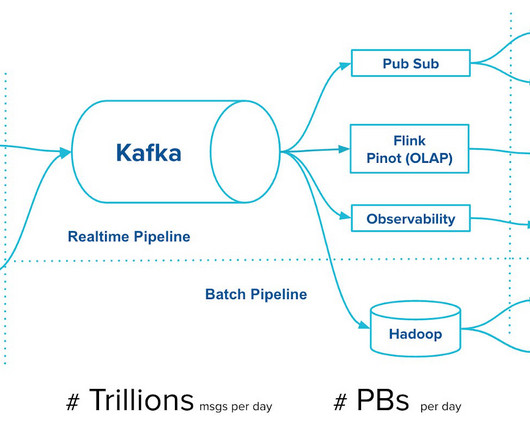
RemoteLogMetadataManager: An interface for managing the lifecycle of metadata about remote log segments with strongly consistent semantics. The RemoteLogManager determines the targeted remote segment based on the desired offset and leader epoch by querying the metadata store using the RemoteLogMetadataManager.
In November 2022, ChatGPT was released, a large language model (LLM) that used the transformer architecture, and is widely credited with starting the current generative AI boom. The following table shows the metadata of three of the largest accelerated compute instances. 32xlarge 0 16 0 128 512 512 4 x 1.9
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Really quickly, LLMs can do many things. Hope you can all hear me well.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Really quickly, LLMs can do many things. Hope you can all hear me well.
This, coupled with the challenges of understanding AI concepts and complex algorithms, contributes to the learning curve associated with developing applications using LLMs. Nevertheless, the integration of LLMs with other tools to form LLM-powered applications could redefine our digital landscape. Two key LLM models are GPT-3.5
Large models like GPT-3 (175B parameters) or BERT-Large (340M parameters) can be reduced by 75% or more. Running BERT models on smartphones for on-device natural language processing requires much less energy due to resource constrained in smartphones than server deployments. The experience is designed to be similar to grep.
For example, input images for an object detection use case might need to be resized or cropped before being served to a computer vision model, or tokenization of text inputs before being used in an LLM. Then we use a pre-trained BERT (uncased) model from the Hugging Face Model Hub to extract token embeddings. nvidia/pytorch:22.10-py3
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content