This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In the realm of artificial intelligence, a transformative force has emerged, capturing the imaginations of researchers, developers, and enthusiasts alike: largelanguagemodels.
A New Era of Language Intelligence At its essence, ChatGPT belongs to a class of AI systems called LargeLanguageModels , which can perform an outstanding variety of cognitive tasks involving natural language. From LanguageModels to LargeLanguageModels How good can a languagemodel become?
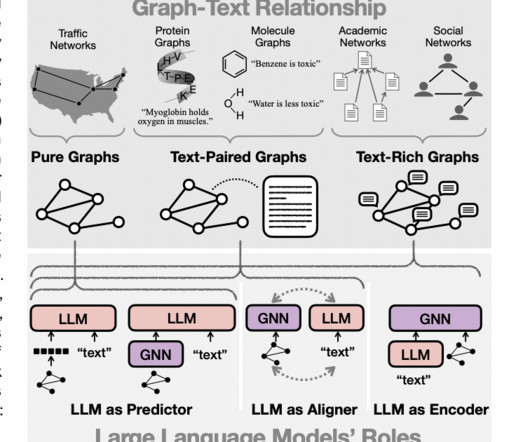
The ability to effectively represent and reason about these intricate relational structures is crucial for enabling advancements in fields like network science, cheminformatics, and recommender systems. Graph NeuralNetworks (GNNs) have emerged as a powerful deep learning framework for graph machine learning tasks.
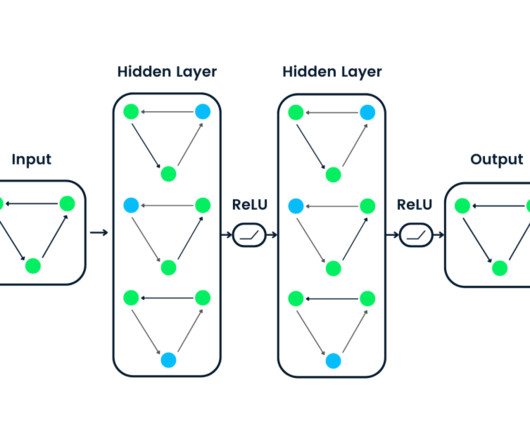
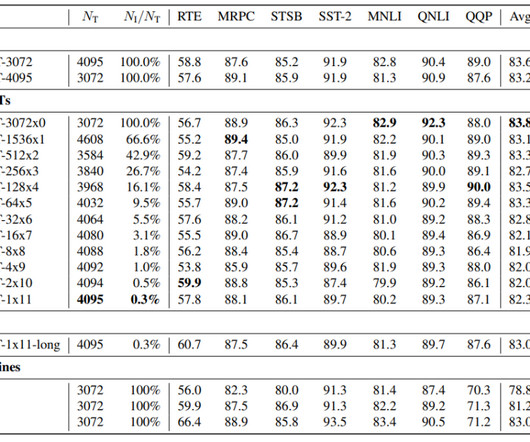
These systems, typically deep learning models, are pre-trained on extensive labeled data, incorporating neuralnetworks for self-attention. Mostly, largelanguagemodels' feedforward layers hold the most parameters. of neurons during inference, specifically 12 out of 4095 in each layer. Let’s begin.
In the ever-evolving domain of Artificial Intelligence (AI), where models like GPT-3 have been dominant for a long time, a silent but groundbreaking shift is taking place. Small LanguageModels (SLM) are emerging and challenging the prevailing narrative of their larger counterparts.
The models were then evaluated based on whether their assessments resonated with human choices. When the models were pitted against each other, the ones based on transformer neuralnetworks exhibited superior performance compared to the simpler recurrent neuralnetworkmodels and statistical models.
Are you curious about the intricate world of largelanguagemodels (LLMs) and the technical jargon that surrounds them? LLM (LargeLanguageModel) LargeLanguageModels (LLMs) are advanced AI systems trained on extensive text datasets to understand and generate human-like text.
However, among all the modern-day AI innovations, one breakthrough has the potential to make the most impact: largelanguagemodels (LLMs). Largelanguagemodels can be an intimidating topic to explore, especially if you don't have the right foundational understanding. What Is a LargeLanguageModel?
LargeLanguageModels (LLMs) are capable of understanding and generating human-like text, making them invaluable for a wide range of applications, such as chatbots, content generation, and language translation. LargeLanguageModels (LLMs) are a type of neuralnetworkmodel trained on vast amounts of text data.
Unlocking Unstructured Data with LLMs Leveraging largelanguagemodels (LLMs) for unstructured data extraction is a compelling solution with distinct advantages that address critical challenges. Context-Aware Data Extraction LLMs possess strong contextual understanding, honed through extensive training on large datasets.
LargeLanguageModels (LLMs) have revolutionized natural language processing, demonstrating remarkable capabilities in various applications. Transformer architecture has emerged as a major leap in natural language processing, significantly outperforming earlier recurrent neuralnetworks.
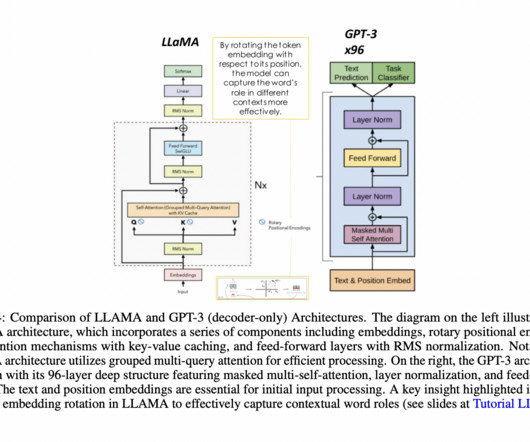
The well-known LargeLanguageModels (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in Natural Language Processing (NLP) and Natural Language Generation (NLG). LLMs are becoming increasingly popular for graph-based applications.
ChatGPT is part of a group of AI systems called LargeLanguageModels (LLMs) , which excel in various cognitive tasks involving natural language. A languagemodel can be fine-tuned on medical documents for specialized tasks in the medical field. A simple artificial neuralnetwork with three layers.
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. The introduction of the transformer architecture has provided a new paradigm for building models that understand and generate human language with unprecedented accuracy and fluency.
In this world of complex terminologies, someone who wants to explain LargeLanguageModels (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. A transformer architecture is typically implemented as a Largelanguagemodel.
But more than MLOps is needed for a new type of ML model called LargeLanguageModels (LLMs). LLMs are deep neuralnetworks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code.
Photo by david clarke on Unsplash The most recent breakthroughs in languagemodels have been the use of neuralnetwork architectures to represent text. There is very little contention that largelanguagemodels have evolved very rapidly since 2018. The story starts with word embedding.
Transformers, BERT, and GPT The transformer architecture is a neuralnetwork architecture that is used for natural language processing (NLP) tasks. BERT can be fine-tuned for a variety of NLP tasks, including question answering, natural language inference, and sentiment analysis.
Computer programs called largelanguagemodels provide software with novel options for analyzing and creating text. It is not uncommon for largelanguagemodels to be trained using petabytes or more of text data, making them tens of terabytes in size.
Adaptability to Unseen Data: These models may not adapt well to real-world data that wasn’t part of their training data. NeuralNetwork: Moving from Machine Learning to Deep Learning & Beyond Neuralnetwork (NN) models are far more complicated than traditional Machine Learning models.
As the demand for largelanguagemodels (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. Let’s break down the key components: Model Definition TensorRT-LLM allows you to define LLMs using a simple Python API.
The Technologies Behind Generative Models Generative models owe their existence to deep neuralnetworks, sophisticated structures designed to mimic the human brain's functionality. By capturing and processing multifaceted variations in data, these networks serve as the backbone of numerous generative models.
Largelanguagemodels (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. What are LargeLanguageModels and Why are They Important? Techniques like Word2Vec and BERT create embedding models which can be reused.
It includes deciphering neuralnetwork layers , feature extraction methods, and decision-making pathways. The Inner Dialogue: How AI Systems Think AI systems, such as chatbots and virtual assistants, simulate a thought process that involves complex modeling and learning mechanisms.
The spotlight is also on DALL-E, an AI model that crafts images from textual inputs. One such model that has garnered considerable attention is OpenAI's ChatGPT , a shining exemplar in the realm of LargeLanguageModels. Prompt 1 : “Tell me about Convolutional NeuralNetworks.”
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERTmodel to improve model performance and reduce inference times. The task assigned to the BERT PLM can be a text-based task such as sentiment analysis, text classification, or Q&A.
With more access to vast amounts of reports, books, articles, journals, and research papers than ever before, swiftly identifying desired information in large bodies of text is becoming invaluable. This makes adopting and scaling these approaches burdensome for many applications.
Transformer Models and BERTModel : In this course, participants delve into the specifics of Transformer models and the Bidirectional Encoder Representations from Transformers (BERT) model. This course is ideal for those interested in the latest in natural language processing technologies.
🔎 Decoding LLM Pipeline Step 1: Input Processing & Tokenization 🔹 From Raw Text to Model-Ready Input In my previous post, I laid out the 8-step LLM pipeline, decoding how largelanguagemodels (LLMs) process language behind the scenes. Tokens: Fundamental unit that neuralnetworks process.
With various foundational ideas from largelanguagemodels and text-to-image generation being adapted and incorporated into the audio modality , the latest AI-powered audio-generative systems are reaching a new unprecedented level of quality. At its core, it's an end-to-end neuralnetwork-based approach.
Largelanguagemodels (LLMs) , such as GPT-4 , BERT , Llama , etc., Technologies such as Recurrent NeuralNetworks (RNNs) and transformers introduced the ability to process sequences of data and paved the way for more adaptive AI. With advancements in machine learning, dynamic memory became possible.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Its AI courses provide valuable knowledge and hands-on experience, helping learners build and optimize AI models, understand advanced AI concepts, and apply AI solutions to real-world problems.
The excellent technological advancements, particularly in the areas of LargeLanguageModels (LLMs), LangChain, and Vector Databases, are responsible for this remarkable development. LargeLanguageModels The development of LargeLanguageModels (LLMs) represents a huge step forward for Artificial Intelligence.
Training largelanguagemodels (LLMs) with billions of parameters can be challenging. In addition to designing the model architecture, researchers need to set up state-of-the-art training techniques for distributed training like mixed precision support, gradient accumulation, and checkpointing. billion parameters).
In a 2021 paper, researchers reported that foundation models are finding a wide array of uses. They said transformer models , largelanguagemodels (LLMs), vision languagemodels (VLMs) and other neuralnetworks still being built are part of an important new category they dubbed foundation models.
By 2017, deep learning began to make waves, driven by breakthroughs in neuralnetworks and the release of frameworks like TensorFlow. Sessions on convolutional neuralnetworks (CNNs) and recurrent neuralnetworks (RNNs) started gaining popularity, marking the beginning of data sciences shift toward AI-driven methods.
LargeLanguageModels (LLMs) like ChatGPT, Google’s Bert, Gemini, Claude Models, and others have emerged as central figures, redefining our interaction with digital interfaces. What are LargeLanguageModels?
Prompt engineering is the art and science of crafting inputs (or “prompts”) to effectively guide and interact with generative AI models, particularly largelanguagemodels (LLMs) like ChatGPT. It begins by emphasizing the importance of understanding how these models respond to natural language prompts.
The advancements in largelanguagemodels have significantly accelerated the development of natural language processing , or NLP. More recent frameworks like LLaMA and BLIP leverage tailored instruction data to devise efficient strategies that demonstrate the potent capabilities of the model.
LargeLanguageModels (LLMs), like GPT, PaLM, LLaMA, etc., Their ability to utilize the strength of Natural Language Processing, Generation, and Understanding by generating content, answering questions, summarizing text, and so on have made LLMs the talk of the town in the last few months.
What are LargeLanguageModels (LLMs)? In generative AI, human language is perceived as a difficult data type. If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a LargeLanguageModel (LLM).
NeuralNetworks & Deep Learning : Neuralnetworks marked a turning point, mimicking human brain functions and evolving through experience. Transformers and Advanced NLP Models : The introduction of transformer architectures revolutionized the NLP landscape.
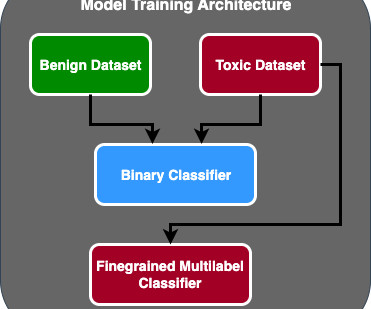
Part 2 will delve into the productionized solution, explaining the design decisions, data flow, and illustration of the model training and deployment architecture. The solution was to find and fine-tune an LLM to classify toxic language. Thus the basis of the transformer model was born.
LLMs are one of the most exciting advancements in natural language processing (NLP). This technique is commonly used in neuralnetwork-based models such as BERT, where it helps to handle out-of-vocabulary words. Stacking can help to combine the strengths of different models and improve their performance.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content