This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Largelanguagemodels (LLMs) have demonstrated promising capabilities in machine translation (MT) tasks. Depending on the use case, they are able to compete with neural translation models such as Amazon Translate. When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata.
LargeLanguageModels (LLMs) are capable of understanding and generating human-like text, making them invaluable for a wide range of applications, such as chatbots, content generation, and language translation. LargeLanguageModels (LLMs) are a type of neural network model trained on vast amounts of text data.
Largelanguagemodels (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. What are LargeLanguageModels and Why are They Important? Techniques like Word2Vec and BERT create embedding models which can be reused.
In order to bring down training time from weeks to days, or days to hours, and distribute a largemodel’s training job, we can use an EC2 Trn1 UltraCluster, which consists of densely packed, co-located racks of Trn1 compute instances all interconnected by non-blocking petabyte scale networking. run_dp_bert_large_hf_pretrain_bf16_s128.sh"
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERTmodel to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERTmodel on a target task using a domain-specific dataset.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Its AI courses provide valuable knowledge and hands-on experience, helping learners build and optimize AI models, understand advanced AI concepts, and apply AI solutions to real-world problems.
🔎 Decoding LLM Pipeline Step 1: Input Processing & Tokenization 🔹 From Raw Text to Model-Ready Input In my previous post, I laid out the 8-step LLM pipeline, decoding how largelanguagemodels (LLMs) process language behind the scenes. Now, lets zoom in starting with Step 1: Input Processing.
The metrics are case insensitive and the values are in the range of 0 (no match) to 1 (perfect match); (2) METEOR score (similar to ROUGE, but including stemming and synonym matching via synonym lists, e.g. “rain” → “drizzle”); (3) BERTScore (a second ML model from the BERT family to compute sentence embeddings and compare their cosine similarity.
In the age of data-driven artificial intelligence, LLMs like GPT-3 and BERT require vast amounts of well-structured data from diverse sources to improve performance across various applications. While these tools are capable of collecting web data, they often do not format the output in a way that LLMs can easily process.
Languagemodels are statistical methods predicting the succession of tokens in sequences, using natural text. Largelanguagemodels (LLMs) are neural network-based languagemodels with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical.
It is probably good to also to mention that I wrote all of these summaries myself and they are not generated by any languagemodels. Are Emergent Abilities of LargeLanguageModels a Mirage? Do LargeLanguageModels Latently Perform Multi-Hop Reasoning? Here we go. NeurIPS 2023. ArXiv 2024.
With AI and LargeLanguageModels (LLMs) taking over the world (hopefully not like Skynet 🤖), we need smarter ways to store and retrieve high-dimensional data. Traditional search relies on discrete tokens like keywords, tags, or metadata to retrieve exact matches. Traditional databases? They tap out.
The following is a high-level overview of how it works conceptually: Separate encoders – These models have separate encoders for each modality—a text encoder for text (for example, BERT or RoBERTa), image encoder for images (for example, CNN for images), and audio encoders for audio (for example, models like Wav2Vec).
Genomic languagemodels are a new and exciting field in the application of largelanguagemodels to challenges in genomics. In this blog post and open source project , we show you how you can pre-train a genomics languagemodel, HyenaDNA , using your genomic data in the AWS Cloud.
With this announcement, you can now easily run large-scale containerized training jobs within Amazon EKS while taking full advantage of the price-performance, scalability, and ease of use offered by Trn1 instances. His interests include largelanguagemodels, deep reinforcement learning, IoT, and genomics.
Largelanguagemodels (LLMs) have transformed the way we engage with and process natural language. These powerful models can understand, generate, and analyze text, unlocking a wide range of possibilities across various domains and industries.
In this era of largelanguagemodels (LLMs), monolithic foundation models, and increasingly enormous datasets, distributed training is a must, as both data and model weights very rarely fit on a single machine. You may also like Can GPT-3 or BERT Ever Understand Language?—The
This post demonstrates the performance and ease of running large-scale, high-performance distributed ML model training and deployment using PyTorch 2.0 These are basically big models based on deep learning techniques that are trained with hundreds of billions of parameters. torch.compile + bf16 + fused AdamW. with up to 3.5
Today we’re going to be talking essentially about how responsible generative-AI-model adoption can happen at the enterprise level, and what are some of the promises and compromises we face. The foundation of largelanguagemodels started quite some time ago. What are the promises? Billions of parameters.
Today we’re going to be talking essentially about how responsible generative-AI-model adoption can happen at the enterprise level, and what are some of the promises and compromises we face. The foundation of largelanguagemodels started quite some time ago. What are the promises? Billions of parameters.
RemoteLogMetadataManager: An interface for managing the lifecycle of metadata about remote log segments with strongly consistent semantics. The RemoteLogManager determines the targeted remote segment based on the desired offset and leader epoch by querying the metadata store using the RemoteLogMetadataManager.
Media Analytics, where we analyze all the broadcast content, as well as live content, that we’re distributing to extract additional metadata from this data and make it available to other systems to create new interactive experiences, or for further insights into how customers are using our streaming services.
Media Analytics, where we analyze all the broadcast content, as well as live content, that we’re distributing to extract additional metadata from this data and make it available to other systems to create new interactive experiences, or for further insights into how customers are using our streaming services.
In order to train transformer models on internet-scale data, huge quantities of PBAs were needed. In November 2022, ChatGPT was released, a largelanguagemodel (LLM) that used the transformer architecture, and is widely credited with starting the current generative AI boom. 32xlarge 0 16 0 128 512 512 4 x 1.9
Largelanguagemodels such as ChatGPT process and generate text sequences by first splitting the text into smaller units called tokens. Over a hundred years ago, telegraphy, a revolutionary technology of its time (“the internet of its era”), faced language inequities similar to those we see in today’s largelanguagemodels.
Models that allow interaction via natural language have become ubiquitious. Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. When is BERT Multilingual? Lucassen, T.,
An important aspect of LargeLanguageModels (LLMs) is the number of parameters these models use for learning. The more parameters a model has, the better it can comprehend the relationship between words and phrases.
Largemodels like GPT-3 (175B parameters) or BERT-Large (340M parameters) can be reduced by 75% or more. Quantized models require less memory bandwidth, leading to faster inference. It also enables running sophisticated models on resource-constrained devices.
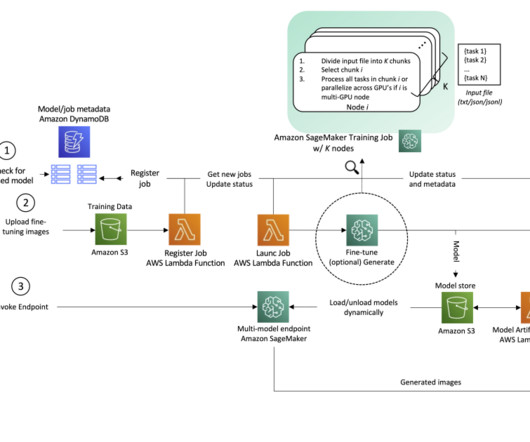
The AI landscape is being reshaped by the rise of generative models capable of synthesizing high-quality data, such as text, images, music, and videos. A single user might have more than one personalized model. At a minimum, we recommend having two tables: One to store the mapping between users and models.
Recent scientific breakthroughs in deep learning (DL), largelanguagemodels (LLMs), and generative AI is allowing customers to use advanced state-of-the-art solutions with almost human-like performance. The second ensemble transforms raw natural language sentences into embeddings and consists of three models.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













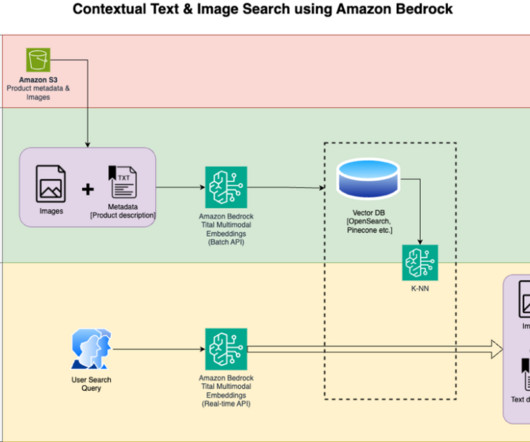




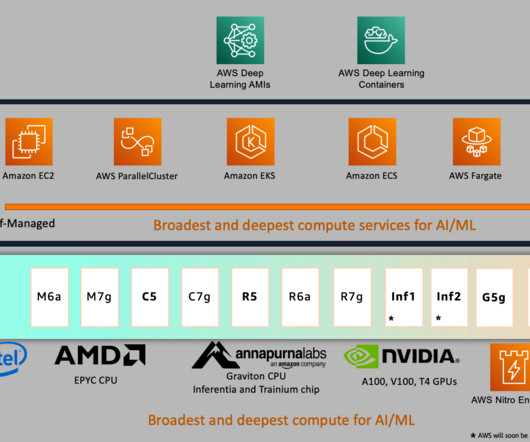


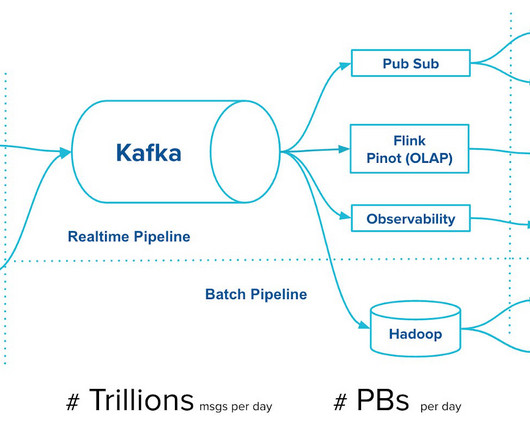
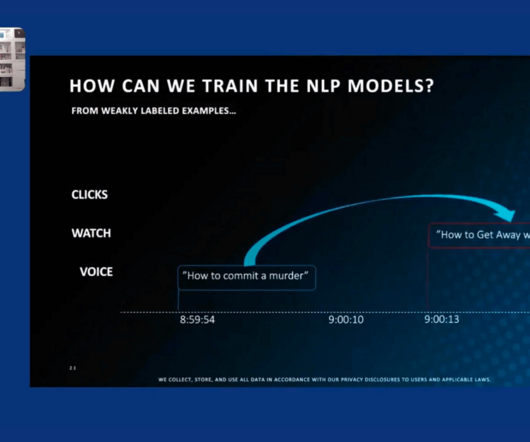
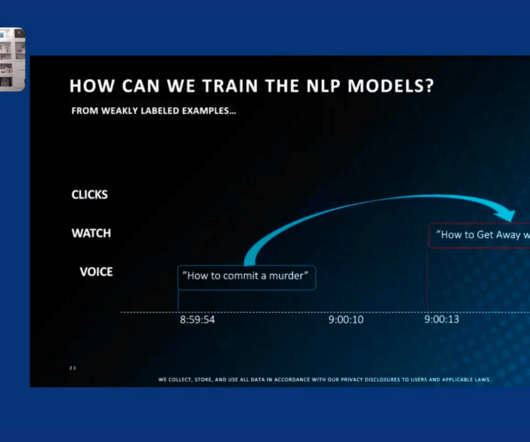












Let's personalize your content