This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction LargeLanguageModels (LLMs) are foundational machine learning models that use deep learning algorithms to process and understand natural language. These models are trained on massive amounts of text data to learn patterns and entity relationships in the language.
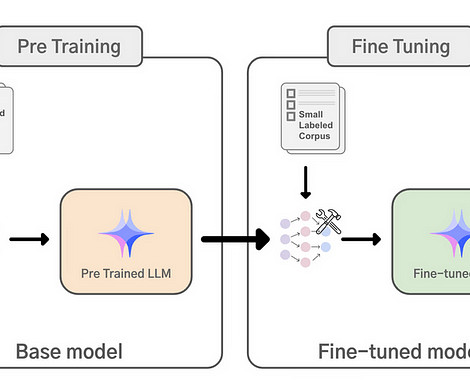
Fine-tuning largelanguagemodels (LLMs) has become an easier task today thanks to the availability of low-code/no-code tools that allow you to simply upload your data, select a base model and obtain a fine-tuned model. However, it is important to understand the fundamentals before diving into these tools.
A New Era of Language Intelligence At its essence, ChatGPT belongs to a class of AI systems called LargeLanguageModels , which can perform an outstanding variety of cognitive tasks involving natural language. From LanguageModels to LargeLanguageModels How good can a languagemodel become?
Largelanguagemodels (LLMs) have demonstrated promising capabilities in machine translation (MT) tasks. Depending on the use case, they are able to compete with neural translation models such as Amazon Translate. However, the industry is seeing enough potential to consider LLMs as a valuable option.
However, traditional deep learning methods often struggle to interpret the semantic details in log data, typically in natural language. LLMs, like GPT-4 and Llama 3, have shown promise in handling such tasks due to their advanced language comprehension. Don’t Forget to join our 55k+ ML SubReddit.
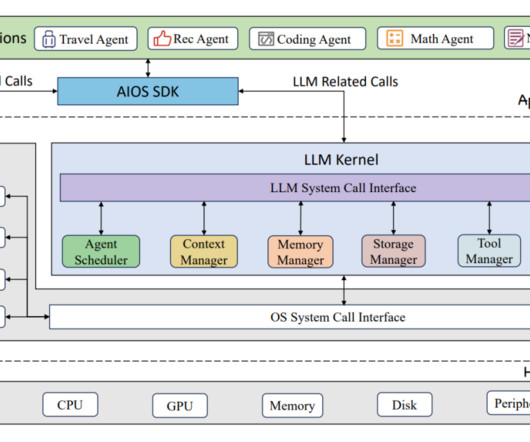
Introduction LargeLanguageModel Operations (LLMOps) is an extension of MLOps, tailored specifically to the unique challenges of managing large-scale languagemodels like GPT, PaLM, and BERT.
Introduction Largelanguagemodels (LLMs) are increasingly becoming powerful tools for understanding and generating human language. LLMs have even shown promise in more specialized domains, like healthcare, finance, and law. Google has been […] The post How to Use Gemma LLM?
These are deep learning models used in NLP. This discovery fueled the development of largelanguagemodels like ChatGPT. Largelanguagemodels or LLMs are AI systems that use transformers to understand and create human-like text. We choose a BERTmodel fine-tuned on the SQuAD dataset.
Google has been a frontrunner in AI research, contributing significantly to the open-source community with transformative technologies like TensorFlow, BERT, T5, JAX, AlphaFold, and AlphaCode. What is Gemma LLM?
In parallel, LargeLanguageModels (LLMs) like GPT-4, and LLaMA have taken the world by storm with their incredible natural language understanding and generation capabilities. In this article, we will delve into the latest research at the intersection of graph machine learning and largelanguagemodels.
Machines are demonstrating remarkable capabilities as Artificial Intelligence (AI) advances, particularly with LargeLanguageModels (LLMs). This raises an important question: Do LLMs remember the same way humans do? How LLMs Process and Store Information? LLMs, on the other hand, are static after training.
For AI and largelanguagemodel (LLM) engineers , design patterns help build robust, scalable, and maintainable systems that handle complex workflows efficiently. This article dives into design patterns in Python, focusing on their relevance in AI and LLM -based systems. BERT, GPT, or T5) based on the task.
In the ever-evolving domain of Artificial Intelligence (AI), where models like GPT-3 have been dominant for a long time, a silent but groundbreaking shift is taking place. Small LanguageModels (SLM) are emerging and challenging the prevailing narrative of their larger counterparts.
Recent innovations include the integration and deployment of LargeLanguageModels (LLMs), which have revolutionized various industries by unlocking new possibilities. More recently, LLM-based intelligent agents have shown remarkable capabilities, achieving human-like performance on a broad range of tasks.
Are you curious about the intricate world of largelanguagemodels (LLMs) and the technical jargon that surrounds them? In this article, we delve into 25 essential terms to enhance your technical vocabulary and provide insights into the mechanisms that make LLMs so transformative.
Introduction The evolution of open largelanguagemodels (LLMs) has significantly impacted the AI research community, particularly in developing chatbots and similar applications. In developing Zephyr-7B, researchers tackled the challenge of aligning a small open LLM entirely through distillation.
In recent years, Natural Language Processing (NLP) has undergone a pivotal shift with the emergence of LargeLanguageModels (LLMs) like OpenAI's GPT-3 and Google’s BERT. Using their extensive training data, LLM-based agents deeply understand language patterns, information, and contextual nuances.
They serve as a core building block in many natural language processing (NLP) applications today, including information retrieval, question answering, semantic search and more. vector embedding Recent advances in largelanguagemodels (LLMs) like GPT-3 have shown impressive capabilities in few-shot learning and natural language generation.
LargeLanguageModels (LLMs) are capable of understanding and generating human-like text, making them invaluable for a wide range of applications, such as chatbots, content generation, and language translation. LargeLanguageModels (LLMs) are a type of neural network model trained on vast amounts of text data.
As the demand for largelanguagemodels (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. NVIDIA's TensorRT-LLM steps in to address this challenge by providing a set of powerful tools and optimizations specifically designed for LLM inference.
RAG is what is necessary for the LargeLanguageModels (LLMs) to provide or generate accurate and factual answers. Introduction Retrieval Augmented-Generation (RAG) has taken the world by Storm ever since its inception.
However, among all the modern-day AI innovations, one breakthrough has the potential to make the most impact: largelanguagemodels (LLMs). Largelanguagemodels can be an intimidating topic to explore, especially if you don't have the right foundational understanding. Want to dive deeper?
In this world of complex terminologies, someone who wants to explain LargeLanguageModels (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. A transformer architecture is typically implemented as a Largelanguagemodel.
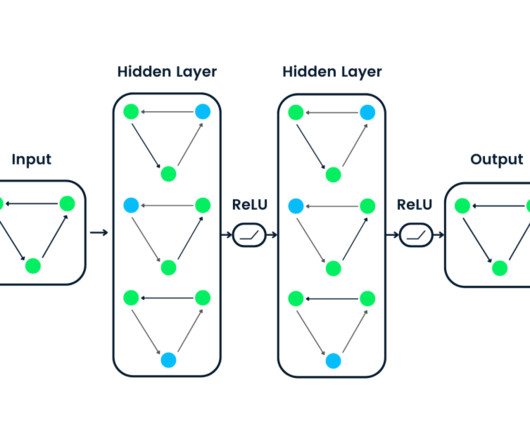
But more than MLOps is needed for a new type of ML model called LargeLanguageModels (LLMs). LLMs are deep neural networks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code.
LargeLanguageModels (LLMs) have revolutionized natural language processing, demonstrating remarkable capabilities in various applications. ” These limitations have spurred researchers to explore innovative solutions that can enhance LLM performance without the need for extensive retraining.
Over the past few years, LargeLanguageModels (LLMs) have garnered attention from AI developers worldwide due to breakthroughs in Natural Language Processing (NLP). These models have set new benchmarks in text generation and comprehension.
LargeLanguageModels have shown remarkable performance in a massive range of tasks. From producing unique and creative content and questioning answers to translating languages and summarizing textual paragraphs, LLMs have been successful in imitating humans.
Largelanguagemodels (LLMs) , such as GPT-4 , BERT , Llama , etc., The post Agent Memory in AI: How Persistent Memory Could Redefine LLM Applications appeared first on Unite.AI. Artificial intelligence (AI) fundamentally transforms how we live, work, and communicate.
LargeLanguageModels have shown immense growth and advancements in recent times. The field of Artificial Intelligence is booming with every new release of these models. From education and finance to healthcare and media, LLMs are contributing to almost every domain.
The intermediate layers of largelanguagemodels (LLMs) contain surprisingly rich representations that often outperform the final layer on downstream tasks, according to new research from CDS Research Scientist Ravid Shwartz-Ziv , CDS Professor Yann LeCun , and their collaborators.
In order to bring down training time from weeks to days, or days to hours, and distribute a largemodel’s training job, we can use an EC2 Trn1 UltraCluster, which consists of densely packed, co-located racks of Trn1 compute instances all interconnected by non-blocking petabyte scale networking. run_dp_bert_large_hf_pretrain_bf16_s128.sh"
Largelanguagemodels (LLMs) built on transformers, including ChatGPT and GPT-4, have demonstrated amazing natural language processing abilities. The creation of transformer-based NLP models has sparked advancements in designing and using transformer-based models in computer vision and other modalities.
As we wrap up October, we’ve compiled a bunch of diverse resources for you — from the latest developments in generative AI to tips for fine-tuning your LLM workflows, from building your own NotebookLM clone to instruction tuning. We have long supported RAG as one of the most practical ways to make LLMs more reliable and customizable.
ChatGPT is part of a group of AI systems called LargeLanguageModels (LLMs) , which excel in various cognitive tasks involving natural language. LargeLanguageModels In recent years, LLM development has seen a significant increase in size, as measured by the number of parameters.
Computer programs called largelanguagemodels provide software with novel options for analyzing and creating text. It is not uncommon for largelanguagemodels to be trained using petabytes or more of text data, making them tens of terabytes in size.
🔎 Decoding LLM Pipeline Step 1: Input Processing & Tokenization 🔹 From Raw Text to Model-Ready Input In my previous post, I laid out the 8-step LLM pipeline, decoding how largelanguagemodels (LLMs) process language behind the scenes. GPT-4 and GPT-3.5
Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for natural language processing (NLP) tasks. BERT is trained on sequences where some of the words in a sentence are masked, and it has to fill in those words taking into account both the words before and after the masked words.
Largelanguagemodels (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. From chatbots to search engines to creative writing aids, LLMs are powering cutting-edge applications across industries. LLMs utilize embeddings to understand word context.
LargeLanguageModels have taken the Artificial Intelligence community by storm. The well-known largelanguagemodels such as GPT, DALLE, and BERT perform extraordinary tasks and ease lives.
Most people who have experience working with largelanguagemodels such as Google’s Bard or OpenAI’s ChatGPT have worked with an LLM that is general, and not industry-specific. But as time has gone on, many industries have realized the power of these models. So what does it do?
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. The introduction of the transformer architecture has provided a new paradigm for building models that understand and generate human language with unprecedented accuracy and fluency.
LLM watermarking, which integrates imperceptible yet detectable signals within model outputs to identify text generated by LLMs, is vital for preventing the misuse of largelanguagemodels. These watermarking techniques are mainly divided into two categories: the KGW Family and the Christ Family.
Traditional neural network models like RNNs and LSTMs and more modern transformer-based models like BERT for NER require costly fine-tuning on labeled data for every custom entity type. Amazon Bedrock – Calls an LLM to identify entities of interest from the given context.
Encoder models like BERT and RoBERTa have long been cornerstones of natural language processing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. Recent fine-tuning advancements masked these issues but failed to modernize the core models. faster than ModernBERT, despite larger size.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content