This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Natural Language Processing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. It results in sparse and high-dimensional vectors that do not capture any semantic or syntactic information about the words. in 2017.
One of the most promising areas within AI in healthcare is Natural Language Processing (NLP), which has the potential to revolutionize patient care by facilitating more efficient and accurate data analysis and communication.
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
Introduction Named Entity Recognition is a major task in Natural Language Processing (NLP) field. It is used to detect the entities in text for further use in the downstream tasks as some text/words are more informative and essential for a given context than others. […].
Dear readers, In this blog, we will build a Flask web app that can input any long piece of information such as a blog or news article and summarize it into just five lines! Text summarization is an NLP(Natural Language Processing) task. SBERT(Sentence-BERT) has […].
At the leading edge of Natural Language Processing (NLP) , models like GPT-4 are trained on vast datasets. However, despite these abilities, how LLMs store and retrieve information differs significantly from human memory. How LLMs Process and Store Information? They understand and generate language with high accuracy.
Bridging the Gap with Natural Language Processing Natural Language Processing (NLP) stands at the forefront of bridging the gap between human language and AI comprehension. NLP enables machines to understand, interpret, and respond to human language in a meaningful way.
Unlocking the Future of Language: The Next Wave of NLP Innovations Photo by Joshua Hoehne on Unsplash The world of technology is ever-evolving, and one area that has seen significant advancements is Natural Language Processing (NLP). A few years back, two groundbreaking models, BERT and GPT, emerged as game-changers.
It can find information based on meaning and remember things for a long time. Take, for instance, word embeddings in natural language processing (NLP). BERT's bidirectional training, which reads text in both directions, is particularly adept at understanding the context surrounding a word.
Photo by Amr Taha™ on Unsplash In the realm of artificial intelligence, the emergence of transformer models has revolutionized natural language processing (NLP). In this guide, we will explore how to fine-tune BERT, a model with 110 million parameters, specifically for the task of phishing URL detection.
Both BERT and GPT are based on the Transformer architecture. Word embedding is a technique in natural language processing (NLP) where words are represented as vectors in a continuous vector space. This facilitates various NLP tasks by providing meaningful word embeddings. This piece compares and contrasts between the two models.
In recent years, Natural Language Processing (NLP) has undergone a pivotal shift with the emergence of Large Language Models (LLMs) like OpenAI's GPT-3 and Google’s BERT. These models, characterized by their large number of parameters and training on extensive text corpora, signify an innovative advancement in NLP capabilities.
BERT is a language model which was released by Google in 2018. As such, it has been the powerhouse of numerous natural language processing (NLP) applications since its inception, and even in the age of large language models (LLMs), BERT-style encoder models are used in tasks like vector embeddings and retrieval augmented generation (RAG).
Language model pretraining has significantly advanced the field of Natural Language Processing (NLP) and Natural Language Understanding (NLU). Models like GPT, BERT, and PaLM are getting popular for all the good reasons. Models like GPT, BERT, and PaLM are getting popular for all the good reasons.
Prompts are changed by introducing spelling errors, replacing synonyms, concatenating irrelevant information or translating from a different language. link] The paper proposes query rewriting as the solution to the problem of LLMs being overly affected by irrelevant information in the prompts. Character-level attacks rank second.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. This method involves hand-keying information directly into the target system. These LLMs can perform various NLP operations, including data extraction.
How Retrieval-Augmented Generation (RAG) Can Boost NLP Projects with Real-Time Data for Smarter AI Models This member-only story is on us. With models like GPT-3 and BERT, it feels like we’re able to do things that were once just sci-fi dreams, like answering complex questions and generating all kinds of content automatically.
Encoder models like BERT and RoBERTa have long been cornerstones of natural language processing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. For example, GTEs contrastive learning boosts retrieval performance but cannot compensate for BERTs obsolete embeddings.
Going anonymous for self-expression has bundled these forums with information that is quite useful for mental health studies. After a detailed evaluation of traditional classifiers and transformer-based models like BERT and GPT-3, MentalBERT and BERT became the best-performing models, achieving a fantastic F1 score of over 76%.
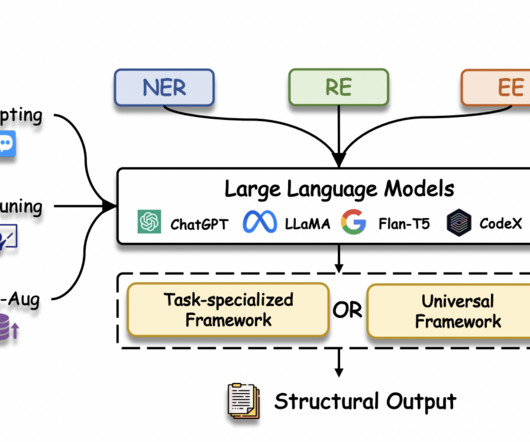
One of the most important areas of NLP is information extraction (IE), which takes unstructured text and turns it into structured knowledge. At the same time, Llama and other large language models have emerged and are revolutionizing NLP with their exceptional text understanding, generation, and generalization capabilities.
LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). Likewise, Hugging Face is an AI company that provides an NLP platform, including a library and a hub of pre-trained LLMs, such as BERT, GPT-3, and T5. However, LLMs are also very different from other models.
We’ll delve deep into its workings and explore its most celebrated offspring: BERT, GPT, and T5. The Magic Behind Transformers In our daily lives, we’re constantly bombarded with information. It doesn’t just process information; it understands context, relationships, and nuances, bridging gaps and illuminating connections.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
Converting this financial data into GHG emissions inventory requires information on the GHG emissions impact of the product or service purchased. In recent years, remarkable strides have been achieved in crafting extensive foundation language models for natural language processing (NLP).
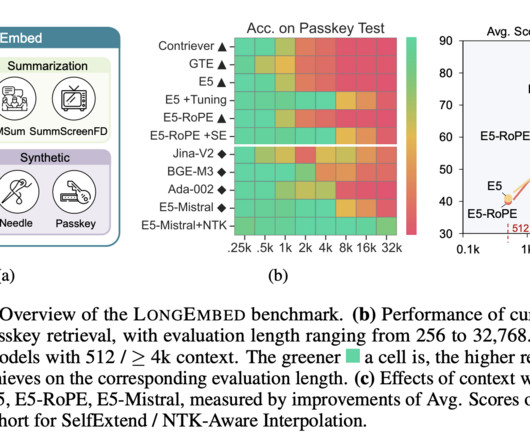
Embedding models are fundamental tools in natural language processing (NLP), providing the backbone for applications like information retrieval and retrieval-augmented generation. Existing research in NLP embedding models has progressively focused on extending context capabilities.
Photo by Kunal Shinde on Unsplash NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.09.20 What is the state of NLP? Deep learning and semantic parsing, do we still care about information extraction? For an overview of some tasks, see NLP Progress or our XTREME benchmark.
Natural Language Processing (NLP) is integral to artificial intelligence, enabling seamless communication between humans and computers. Traditional NLP methods like CNN, RNN, and LSTM have evolved with transformer architecture and large language models (LLMs) like GPT and BERT families, providing significant advancements in the field.
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. Let’s delve into the role of transformers in NLP and elucidate the process of training LLMs using this innovative architecture. appeared first on MarkTechPost.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
Attention Mechanism Image Source Course difficulty: Intermediate-level Completion time: ~ 45 minutes Prerequisites: Knowledge of ML, DL, Natural Language Processing (NLP) , Computer Vision (CV), and Python programming. Covers the different NLP tasks for which a BERT model is used. What will AI enthusiasts learn?
To prevent these scenarios, protection of data, user assets, and identity information has been a major focus of the blockchain security research community, as to ensure the development of the blockchain technology, it is essential to maintain its security.
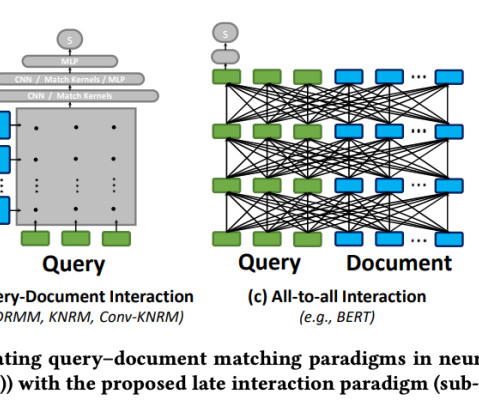
When it comes to natural language processing (NLP) and information retrieval, the ability to efficiently and accurately retrieve relevant information is paramount. Retrieval : The system queries a vector database or document collection to find information relevant to the user's query.
In my previous articles about transformers and GPTs, we have done a systematic analysis of the timeline and development of NLP. Prerequisite Before we dive into understanding BERT, we need to understand in order to create the model, the authors have used or referenced several concepts and improvements from several other preceding works.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (Natural Language Processing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
It’s also an area that stands to benefit most from automated or semi-automated machine learning (ML) and natural language processing (NLP) techniques. Semi) automated data extraction for SLRs through NLP Researchers can deploy a variety of ML and NLP techniques to help mitigate these challenges. This study by Bui et al.
AI Capabilities : Enables image recognition, NLP, and predictive analytics. The choice of architecture is crucial because it dictates how the model processes information and learns representations from the data. Information flows in only one direction from the input layer, through one or more hidden layers, to the output layer.
Additionally, the models themselves are created from limited architectures: “Almost all state-of-the-art NLP models are now adapted from one of a few foundation models, such as BERT, RoBERTa, BART, T5, etc. Typical questions include: What is your model’s use case? What are the risks for disparate impact?
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini.
To tackle the issue of single modality, Meta AI released the data2vec, the first of a kind, self supervised high-performance algorithm to learn patterns information from three different modalities: image, text, and speech. Why Does the AI Industry Need the Data2Vec Algorithm?
They are now capable of natural language processing ( NLP ), grasping context and exhibiting elements of creativity. For example, organizations can use generative AI to: Quickly turn mountains of unstructured text into specific and usable document summaries, paving the way for more informed decision-making.
A foundation model is built on a neural network model architecture to process information much like the human brain does. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. An open-source model, Google created BERT in 2018. All watsonx.ai
By enhancing their efficiency and safety, we pave the way for innovative applications such as information extraction. By prompting a model to elucidate its thought process, it induces a more thorough, methodical generation of ideas, which tends to align closely with accurate information.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Impact V.2
In today’s information-rich digital landscape, navigating extensive web content can be overwhelming. Whether you’re researching for a project, studying complex material, or trying to extract specific information from lengthy articles, the process can be time-consuming and inefficient. Windows NT 10.0; Windows NT 10.0;
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content