This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
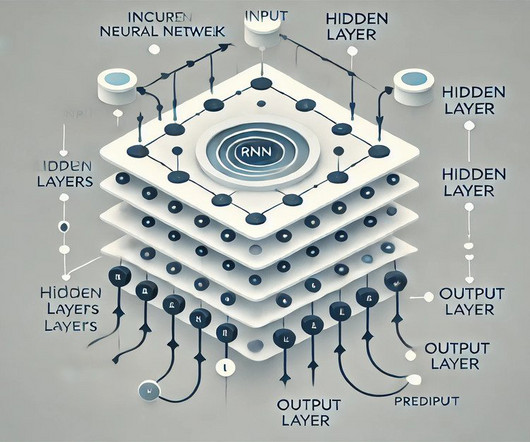
It results in sparse and high-dimensional vectors that do not capture any semantic or syntactic information about the words. Recurrent NeuralNetworks (RNNs) became the cornerstone for these applications due to their ability to handle sequential data by maintaining a form of memory. However, RNNs were not without limitations.
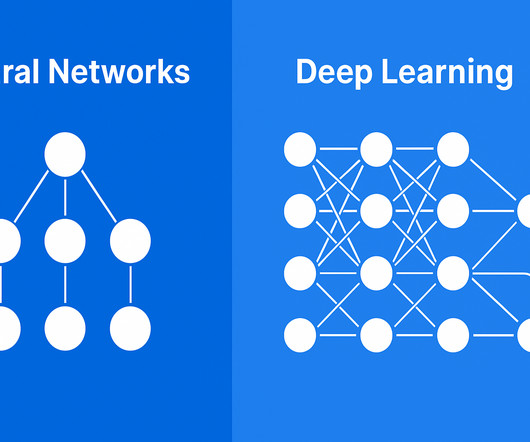
Summary: Deep Learning vs NeuralNetwork is a common comparison in the field of artificial intelligence, as the two terms are often used interchangeably. Introduction Deep Learning and NeuralNetworks are like a sports team and its star player. However, they differ in complexity and application.
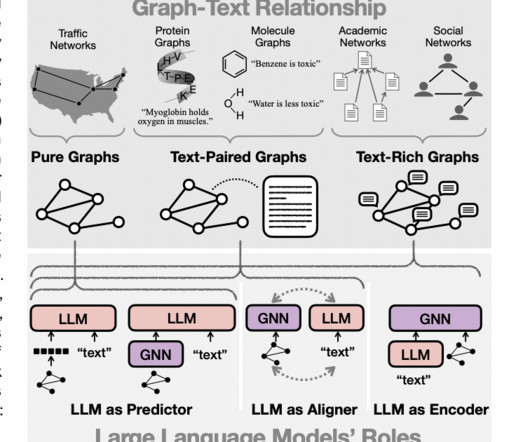
The ability to effectively represent and reason about these intricate relational structures is crucial for enabling advancements in fields like network science, cheminformatics, and recommender systems. Graph NeuralNetworks (GNNs) have emerged as a powerful deep learning framework for graph machine learning tasks.
These systems, typically deep learning models, are pre-trained on extensive labeled data, incorporating neuralnetworks for self-attention. This article introduces UltraFastBERT, a BERT-based framework matching the efficacy of leading BERT models but using just 0.3%
Central to this advancement in NLP is the development of artificial neuralnetworks, which draw inspiration from the biological neurons in the human brain. These networks emulate the way human neurons transmit electrical signals, processing information through interconnected nodes.
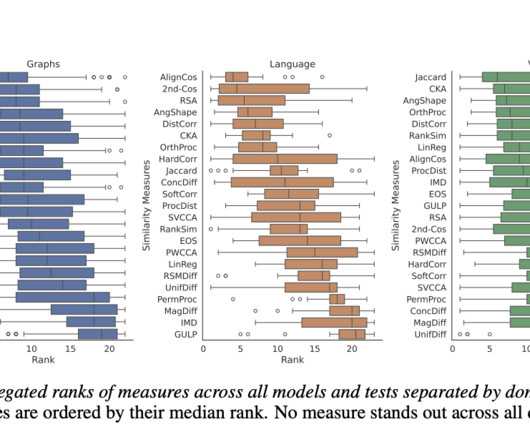
Representational similarity measures are essential tools in machine learning, used to compare internal representations of neuralnetworks. These measures help researchers understand learning dynamics, model behaviors, and performance by providing insights into how different neuralnetwork layers and architectures process information.
This method involves hand-keying information directly into the target system. But these solutions cannot guarantee 100% accurate results. Text Pattern Matching Text pattern matching is a method for identifying and extracting specific information from text using predefined rules or patterns.
Photo by david clarke on Unsplash The most recent breakthroughs in language models have been the use of neuralnetwork architectures to represent text. Both BERT and GPT are based on the Transformer architecture. 2013 Word2Vec is a neuralnetwork model that uses n-grams by training on context windows of words.
By leveraging advances in artificial intelligence (AI) and neuroscience, researchers are developing systems that can translate the complex signals produced by our brains into understandable information, such as text or images. These patterns are then decoded using deep neuralnetworks to reconstruct the perceived images.
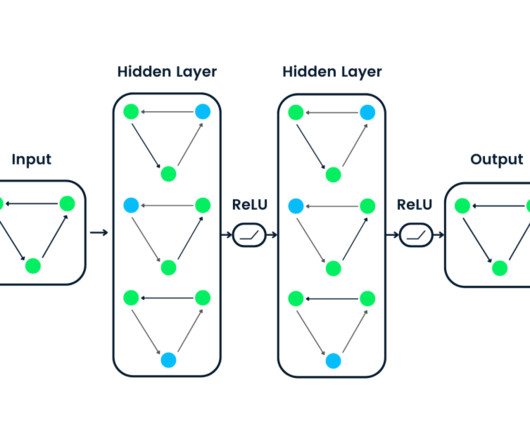
These architectures are based on artificial neuralnetworks , which are computational models loosely inspired by the structure and functioning of biological neuralnetworks, such as those in the human brain. A simple artificial neuralnetwork consisting of three layers.
It includes deciphering neuralnetwork layers , feature extraction methods, and decision-making pathways. These systems rely heavily on neuralnetworks to process vast amounts of information. During training, neuralnetworks learn patterns from extensive datasets.
NeuralNetwork: Moving from Machine Learning to Deep Learning & Beyond Neuralnetwork (NN) models are far more complicated than traditional Machine Learning models. Advances in neuralnetwork techniques have formed the basis for transitioning from machine learning to deep learning.
Large language models (LLMs) , such as GPT-4 , BERT , Llama , etc., Once an interaction ends, all prior information is lost, requiring users to start anew with each use. Once an interaction ends, all prior information is lost, requiring users to start anew with each use.
Project Structure Accelerating Convolutional NeuralNetworks Parsing Command Line Arguments and Running a Model Evaluating Convolutional NeuralNetworks Accelerating Vision Transformers Evaluating Vision Transformers Accelerating BERT Evaluating BERT Miscellaneous Summary Citation Information What’s New in PyTorch 2.0?
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
Audio signals can be represented as waveforms , possessing specific characteristics such as frequency, amplitude, and phase , whose different combinations can encode various types of information like pitch and loudness in sound. Map a prompt , a description of the desired audio qualities and its content, to a generated waveform output.
Prompt 1 : “Tell me about Convolutional NeuralNetworks.” ” Response 1 : “Convolutional NeuralNetworks (CNNs) are multi-layer perceptron networks that consist of fully connected layers and pooling layers. They are commonly used in image recognition tasks. .”
LLMs are deep neuralnetworks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP).
To prevent these scenarios, protection of data, user assets, and identity information has been a major focus of the blockchain security research community, as to ensure the development of the blockchain technology, it is essential to maintain its security.
Summary: Neuralnetworks are a key technique in Machine Learning, inspired by the human brain. Different types of neuralnetworks, such as feedforward, convolutional, and recurrent networks, are designed for specific tasks like image recognition, Natural Language Processing, and sequence modelling.
A Deep NeuralNetwork (DNN) is an artificial neuralnetwork that features multiple layers of interconnected nodes, also known as neurons. The deep aspect of DNNs comes from multiple hidden layers, which allow the network to learn and model complex patterns and relationships in data.
Summary: Recurrent NeuralNetworks (RNNs) are specialised neuralnetworks designed for processing sequential data by maintaining memory of previous inputs. Introduction Neuralnetworks have revolutionised data processing by mimicking the human brain’s ability to recognise patterns.
These models mimic the human brain’s neuralnetworks, making them highly effective for image recognition, natural language processing, and predictive analytics. Feedforward NeuralNetworks (FNNs) Feedforward NeuralNetworks (FNNs) are the simplest and most foundational architecture in Deep Learning.
Transformer Models and BERT Model : In this course, participants delve into the specifics of Transformer models and the Bidirectional Encoder Representations from Transformers (BERT) model. The course also includes information on using Google tools to develop LLM applications, providing practical insights into deploying these models.
In modern machine learning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in Natural Language Processing, and Vision Transformers in computer vision tasks.
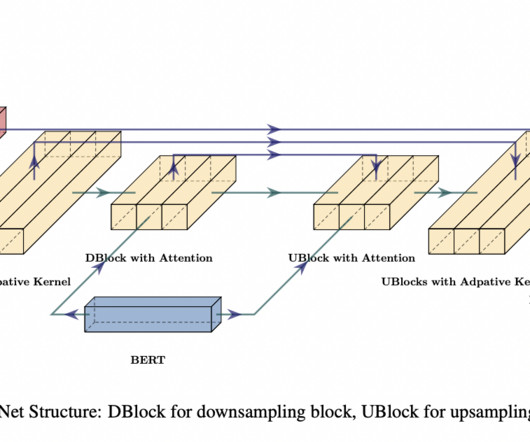
This model consists of two primary modules: A pre-trained BERT model is employed to extract pertinent information from the input text, and A diffusion UNet model processes the output from BERT. It is built upon a pre-trained BERT model. The E3 TTS employs an iterative refinement process to generate an audio waveform.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini.
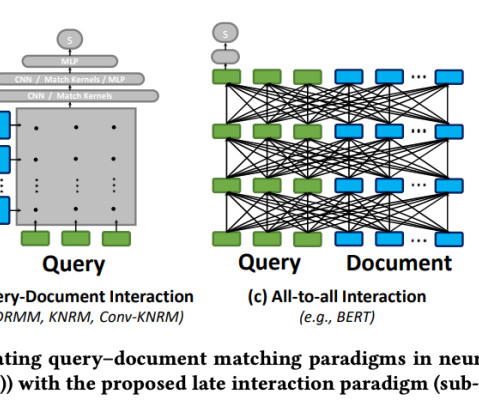
When it comes to natural language processing (NLP) and information retrieval, the ability to efficiently and accurately retrieve relevant information is paramount. Retrieval : The system queries a vector database or document collection to find information relevant to the user's query.
They said transformer models , large language models (LLMs), vision language models (VLMs) and other neuralnetworks still being built are part of an important new category they dubbed foundation models. Earlier neuralnetworks were narrowly tuned for specific tasks.
To tackle the issue of single modality, Meta AI released the data2vec, the first of a kind, self supervised high-performance algorithm to learn patterns information from three different modalities: image, text, and speech. Why Does the AI Industry Need the Data2Vec Algorithm?
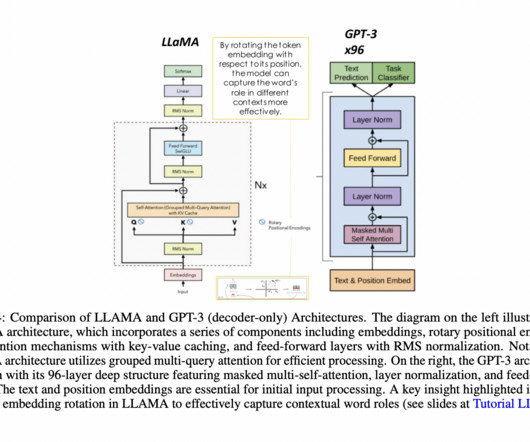
A foundation model is built on a neuralnetwork model architecture to process information much like the human brain does. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018.
AI models like neuralnetworks , used in applications like Natural Language Processing (NLP) and computer vision , are notorious for their high computational demands. Models like GPT and BERT involve millions to billions of parameters, leading to significant processing time and energy consumption during training and inference.
NeuralNetworks & Deep Learning : Neuralnetworks marked a turning point, mimicking human brain functions and evolving through experience. Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. BabyAGI Then, there's BabyAGI , a simplified yet powerful agent.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
Small Language Models, which are compact generative AI models, are distinguished by their small neuralnetwork size, number of parameters, and volume of training data. Accuracy: SLMs produce factually correct information and are less prone to display biases because of their smaller scale.
Activation functions for neuralnetworks are an essential part of deep learning since they decide the accuracy and efficiency of the training model used to create or split a large-scale neuralnetwork and the output of deep learning models. An artificial neuralnetwork contains a large number of linked individual neurons.
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. in 2017, marking a departure from the previous reliance on recurrent neuralnetworks (RNNs) and convolutional neuralnetworks (CNNs) for processing sequential data.
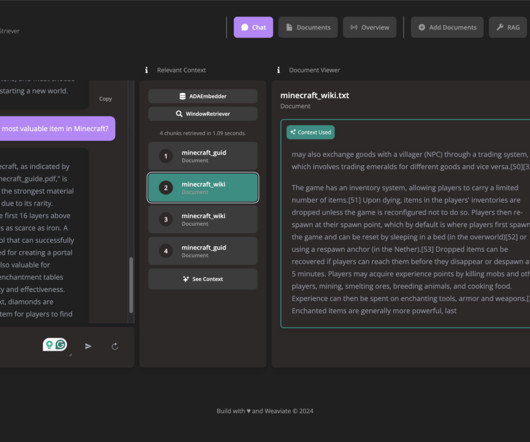
RAG has significantly improved the performance of virtual assistants, chatbots, and information retrieval systems by ensuring that generated responses are accurate and contextually appropriate. The synergy of retrieval and generation enhances the user experience by providing detailed and specific information. Image Source Verba 1.0
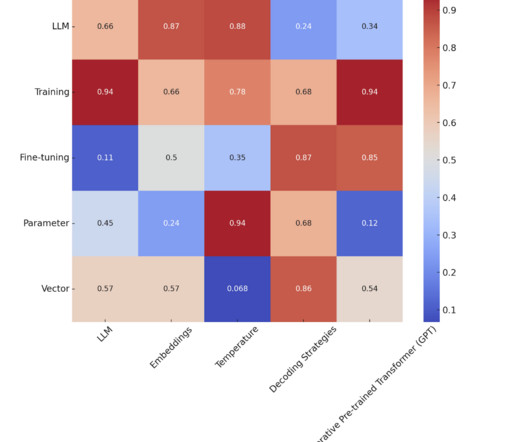
Parameter In the context of neuralnetworks, including LLMs, a parameter is a variable part of the model’s architecture learned from the training data. Parameters (like weights in neuralnetworks) are adjusted during training to reduce the difference between predicted and actual output.
However, these models face significant challenges, including temporal limitations of their knowledge base, difficulties with complex mathematical computations, and a tendency to produce inaccurate information or “hallucinations.” However, this is just one component within a broader, more complex framework.
A significant breakthrough came with neuralnetworks and deep learning. Models like Google's Neural Machine Translation (GNMT) and Transformer revolutionized language processing by enabling more nuanced, context-aware translations. IBM's Model 1 and Model 2 laid the groundwork for advanced systems.
Current datasets for search and recommendation tasks contain textual information or statistically dense features, severely limiting the development of effective multimodal search and recommendation (S&R) services. Vision-Language Models (VLM) achieve even better performance by incorporating visual information.
The well-known Large Language Models (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in Natural Language Processing (NLP) and Natural Language Generation (NLG). The team has shared information on benchmark datasets and open-source scripts to help in applying and assessing these methods.
Created Using Midjourney Next Week in The Sequence: Edge 451: Explores the ideas behind multi-teacher distillation including the MT-BERT paper. The system leverages a recurrent, transformer-based neuralnetwork architecture inspired by the successful use of Transformers in large language models (LLMs).
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content