This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Named Entity Recognition is a major task in NaturalLanguageProcessing (NLP) field. It is used to detect the entities in text for further use in the downstream tasks as some text/words are more informative and essential for a given context than others. […].
The Challenge Legal texts are uniquely challenging for naturallanguageprocessing (NLP) due to their specialized vocabulary, intricate syntax, and the critical importance of context. Terms that appear similar in general language can have vastly different meanings in legal contexts.
NaturalLanguageProcessing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. It results in sparse and high-dimensional vectors that do not capture any semantic or syntactic information about the words.
One of the most promising areas within AI in healthcare is NaturalLanguageProcessing (NLP), which has the potential to revolutionize patient care by facilitating more efficient and accurate data analysis and communication.
Unlocking the Future of Language: The Next Wave of NLP Innovations Photo by Joshua Hoehne on Unsplash The world of technology is ever-evolving, and one area that has seen significant advancements is NaturalLanguageProcessing (NLP). A few years back, two groundbreaking models, BERT and GPT, emerged as game-changers.
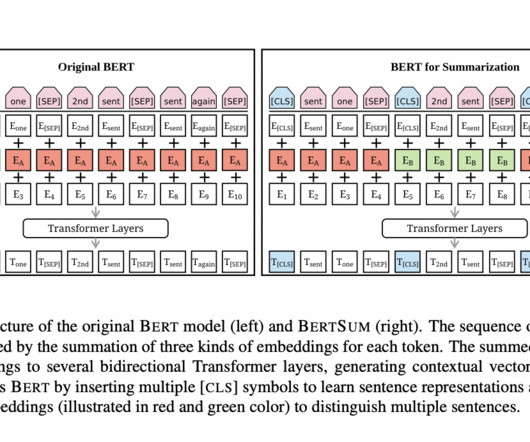
Dear readers, In this blog, we will build a Flask web app that can input any long piece of information such as a blog or news article and summarize it into just five lines! Text summarization is an NLP(NaturalLanguageProcessing) task. SBERT(Sentence-BERT) has […].
NaturalLanguageProcessing (NLP) is integral to artificial intelligence, enabling seamless communication between humans and computers. Researchers from East China University of Science and Technology and Peking University have surveyed the integrated retrieval-augmented approaches to language models.
At the leading edge of NaturalLanguageProcessing (NLP) , models like GPT-4 are trained on vast datasets. They understand and generate language with high accuracy. However, despite these abilities, how LLMs store and retrieve information differs significantly from human memory.
Knowledge-intensive NaturalLanguageProcessing (NLP) involves tasks requiring deep understanding and manipulation of extensive factual information. Consequently, there is a need for new architectures that can incorporate external information dynamically and flexibly.
Bridging the Gap with NaturalLanguageProcessingNaturalLanguageProcessing (NLP) stands at the forefront of bridging the gap between human language and AI comprehension. NLP enables machines to understand, interpret, and respond to human language in a meaningful way.
Photo by Amr Taha™ on Unsplash In the realm of artificial intelligence, the emergence of transformer models has revolutionized naturallanguageprocessing (NLP). In this guide, we will explore how to fine-tune BERT, a model with 110 million parameters, specifically for the task of phishing URL detection.
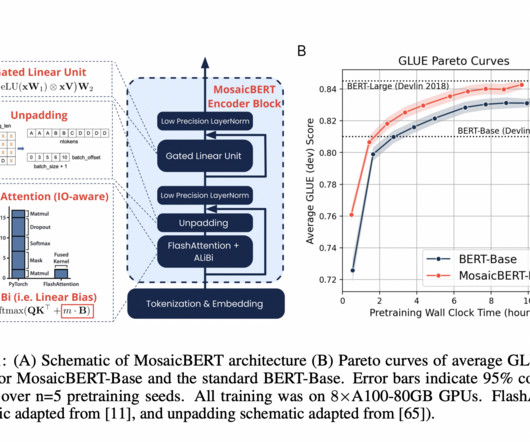
BERT is a language model which was released by Google in 2018. However, in the past half a decade, many significant advancements have been made with other types of architectures and training configurations that have yet to be incorporated into BERT. BERT-Base reached an average GLUE score of 83.2% hours compared to 23.35
Both BERT and GPT are based on the Transformer architecture. Word embedding is a technique in naturallanguageprocessing (NLP) where words are represented as vectors in a continuous vector space. It was the Attention Mechanism breakthrough that gave birth to Large Pre-Trained Models and Transformers.
In recent years, NaturalLanguageProcessing (NLP) has undergone a pivotal shift with the emergence of Large Language Models (LLMs) like OpenAI's GPT-3 and Google’s BERT. Web browsing agents have traditionally been used for information retrieval through keyword searches.
It can find information based on meaning and remember things for a long time. Take, for instance, word embeddings in naturallanguageprocessing (NLP). BERT's bidirectional training, which reads text in both directions, is particularly adept at understanding the context surrounding a word.
Encoder models like BERT and RoBERTa have long been cornerstones of naturallanguageprocessing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. For example, GTEs contrastive learning boosts retrieval performance but cannot compensate for BERTs obsolete embeddings.
Language model pretraining has significantly advanced the field of NaturalLanguageProcessing (NLP) and NaturalLanguage Understanding (NLU). Models like GPT, BERT, and PaLM are getting popular for all the good reasons. Models like GPT, BERT, and PaLM are getting popular for all the good reasons.
This advancement has spurred the commercial use of generative AI in naturallanguageprocessing (NLP) and computer vision, enabling automated and intelligent data extraction. This method involves hand-keying information directly into the target system. It is often easier to adopt due to its lower initial costs.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
LLMs are deep neural networks that can generate naturallanguage texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in NaturalLanguageProcessing (NLP).
Attention Mechanism Image Source Course difficulty: Intermediate-level Completion time: ~ 45 minutes Prerequisites: Knowledge of ML, DL, NaturalLanguageProcessing (NLP) , Computer Vision (CV), and Python programming. Covers the different NLP tasks for which a BERT model is used. What will AI enthusiasts learn?
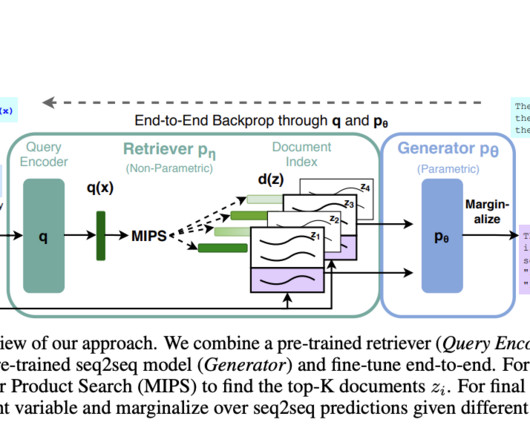
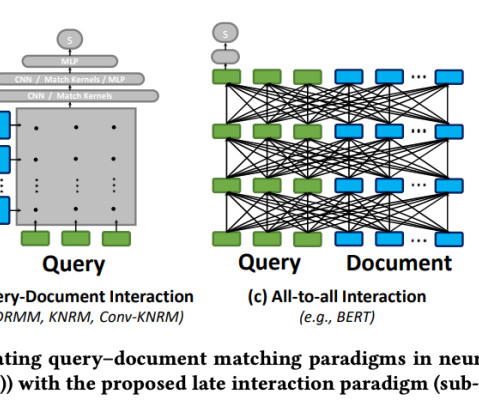
When it comes to naturallanguageprocessing (NLP) and information retrieval, the ability to efficiently and accurately retrieve relevant information is paramount. Retrieval : The system queries a vector database or document collection to find information relevant to the user's query.
To tackle the issue of single modality, Meta AI released the data2vec, the first of a kind, self supervised high-performance algorithm to learn patterns information from three different modalities: image, text, and speech. Why Does the AI Industry Need the Data2Vec Algorithm?
They are now capable of naturallanguageprocessing ( NLP ), grasping context and exhibiting elements of creativity. For example, organizations can use generative AI to: Quickly turn mountains of unstructured text into specific and usable document summaries, paving the way for more informed decision-making.
Transformer Models and BERT Model : In this course, participants delve into the specifics of Transformer models and the Bidirectional Encoder Representations from Transformers (BERT) model. This course is ideal for those interested in the latest in naturallanguageprocessing technologies.
The core process is a general technique known as self-supervised learning , a learning paradigm that leverages the inherent structure of the data itself to generate labels for training. This concept is not exclusive to naturallanguageprocessing, and has also been employed in other domains.
Figure 1: adversarial examples in computer vision (left) and naturallanguageprocessing tasks (right). Temporal commonsense: naturallanguage rarely communicates explicit temporal information. So knowledge in language models is not the most accurate and reliable. Using the AllenNLP demo.
Once a set of word vectors has been learned, they can be used in various naturallanguageprocessing (NLP) tasks such as text classification, language translation, and question answering. This allows BERT to learn a deeper sense of the context in which words appear. or ChatGPT (2022) ChatGPT is also known as GPT-3.5
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini.
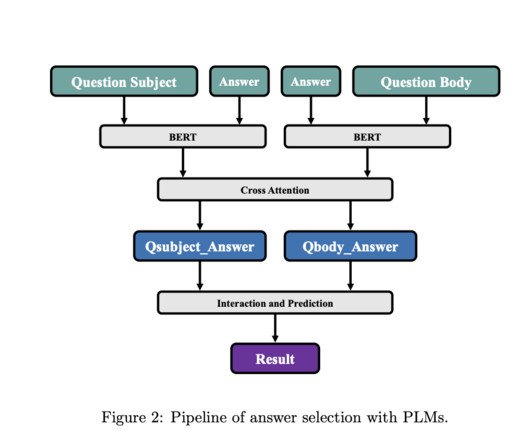
Answers, and StackOverflow, serve as interactive hubs for information exchange. Despite their popularity, the varying quality of responses poses a challenge for users who must navigate through numerous answers to find relevant information efficiently. Community Question Answering (CQA) platforms, exemplified by Quora, Yahoo!
It converts raw streams of transactions into contextualized, structured information by combining data from multiple sources, including naturallanguage models, search engines, internal databases, external APIs, and existing transaction data from across our network. Could you share the genesis story behind Ntropy?
To prevent these scenarios, protection of data, user assets, and identity information has been a major focus of the blockchain security research community, as to ensure the development of the blockchain technology, it is essential to maintain its security.
Image illustrating how Retrieval-Augmented Generation (RAG) can boost NLP projects with real-time data for smarter AI models generated using ChatGPT by the Author We’ve seen some pretty amazing advancements in NaturalLanguageProcessing (NLP) recently. That’s a big deal in today’s fast-moving world.
Converting this financial data into GHG emissions inventory requires information on the GHG emissions impact of the product or service purchased. In recent years, remarkable strides have been achieved in crafting extensive foundation language models for naturallanguageprocessing (NLP).
Pixabay: by Activedia Image captioning combines naturallanguageprocessing and computer vision to generate image textual descriptions automatically. Image captioning integrates computer vision, which interprets visual information, and NLP, which produces human language.
A foundation model is built on a neural network model architecture to processinformation much like the human brain does. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. An open-source model, Google created BERT in 2018.
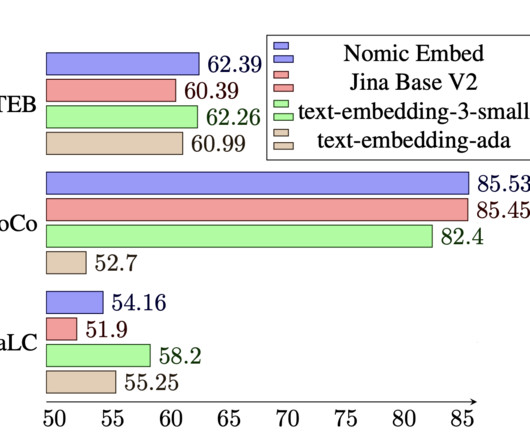
They have introduced a groundbreaking open-source German/English embedding model, deepset-mxbai-embed-de-large-v1 , to enhance multilingual capabilities in naturallanguageprocessing (NLP). This allows for the truncation of later dimensions, enhancing efficiency.
In the evolving landscape of naturallanguageprocessing (NLP), the ability to grasp and process extensive textual contexts is paramount. 2023), have significantly propelled the capabilities of language models, particularly through the development of text embeddings. 2021), Izacard et al. 2022), and Ram et al.
Large Language Models (LLMs), like GPT, PaLM, LLaMA, etc., Their ability to utilize the strength of NaturalLanguageProcessing, Generation, and Understanding by generating content, answering questions, summarizing text, and so on have made LLMs the talk of the town in the last few months.
However, as technology advanced, so did the complexity and capabilities of AI music generators, paving the way for deep learning and NaturalLanguageProcessing (NLP) to play pivotal roles in this tech. Initially, the attempts were simple and intuitive, with basic algorithms creating monotonous tunes.
The simplest NN – Multi-layer perceptron (MLP) consists of several neurons connected together to understand information and perform tasks, similar to how a human brain functions. For instance, neural networks used for naturallanguageprocessing tasks (like text summarization, question answering, and translation) are known as transformers.
TextBlob A popular Python sentiment analysis toolkit, TextBlob is praised for its ease of use and adaptability while managing naturallanguageprocessing (NLP) workloads. spaCy A well-known open-source naturallanguageprocessing package, spaCy is praised for its robustness and speed while processing massive amounts of text.
Naturallanguageprocessing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., rely on Language Models as their foundation. Unigrams, N-grams, exponential, and neural networks are valid forms for the Language Model.
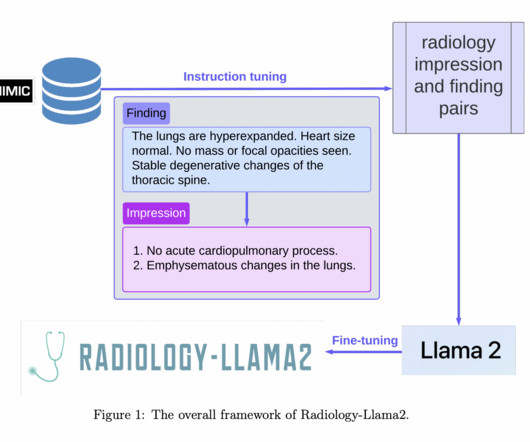
Large language models (LLMs) built on transformers, including ChatGPT and GPT-4, have demonstrated amazing naturallanguageprocessing abilities. State-of-the-Art Performance: On the MIMIC-CXR and OpenI datasets, outperform all other language models to generate clinical impressions, setting a new standard.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content