This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A New Era of Language Intelligence At its essence, ChatGPT belongs to a class of AI systems called LargeLanguageModels , which can perform an outstanding variety of cognitive tasks involving natural language. From LanguageModels to LargeLanguageModels How good can a languagemodel become?
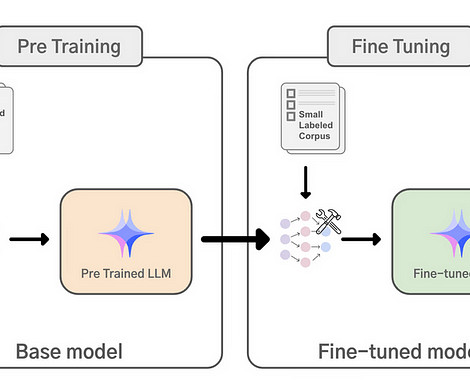
Fine-tuning largelanguagemodels (LLMs) has become an easier task today thanks to the availability of low-code/no-code tools that allow you to simply upload your data, select a base model and obtain a fine-tuned model. However, it is important to understand the fundamentals before diving into these tools.
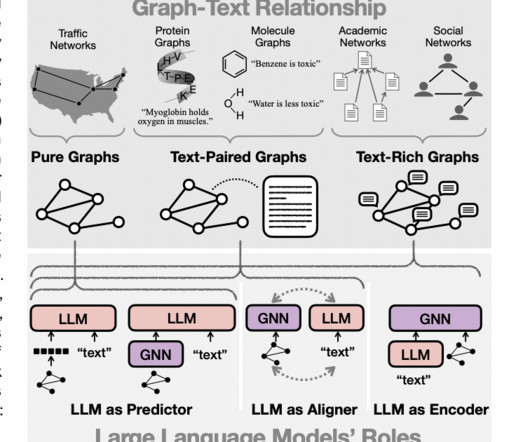
In parallel, LargeLanguageModels (LLMs) like GPT-4, and LLaMA have taken the world by storm with their incredible natural language understanding and generation capabilities. In this article, we will delve into the latest research at the intersection of graph machine learning and largelanguagemodels.
Machines are demonstrating remarkable capabilities as Artificial Intelligence (AI) advances, particularly with LargeLanguageModels (LLMs). At the leading edge of Natural Language Processing (NLP) , models like GPT-4 are trained on vast datasets. They understand and generate language with high accuracy.
The intermediate layers of largelanguagemodels (LLMs) contain surprisingly rich representations that often outperform the final layer on downstream tasks, according to new research from CDS Research Scientist Ravid Shwartz-Ziv , CDS Professor Yann LeCun , and their collaborators.
They serve as a core building block in many natural language processing (NLP) applications today, including information retrieval, question answering, semantic search and more. More recent methods based on pre-trained languagemodels like BERT obtain much better context-aware embeddings. Clustering 46.1 Average 64.2
However, among all the modern-day AI innovations, one breakthrough has the potential to make the most impact: largelanguagemodels (LLMs). Largelanguagemodels can be an intimidating topic to explore, especially if you don't have the right foundational understanding. What Is a LargeLanguageModel?
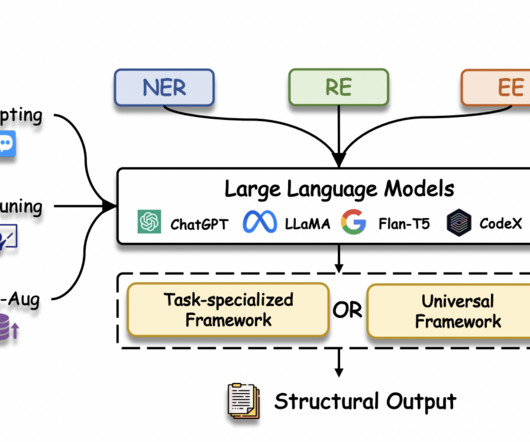
One of the most important areas of NLP is information extraction (IE), which takes unstructured text and turns it into structured knowledge. At the same time, Llama and other largelanguagemodels have emerged and are revolutionizing NLP with their exceptional text understanding, generation, and generalization capabilities.
Are you curious about the intricate world of largelanguagemodels (LLMs) and the technical jargon that surrounds them? LLM (LargeLanguageModel) LargeLanguageModels (LLMs) are advanced AI systems trained on extensive text datasets to understand and generate human-like text.
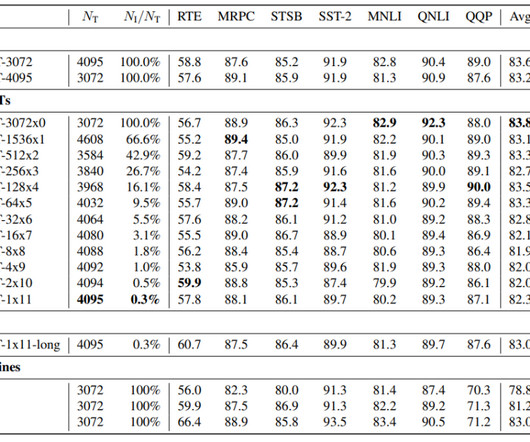
Mostly, largelanguagemodels' feedforward layers hold the most parameters. Studies show that these models use only a fraction of available neurons for output computation during inference. This article introduces UltraFastBERT, a BERT-based framework matching the efficacy of leading BERTmodels but using just 0.3%
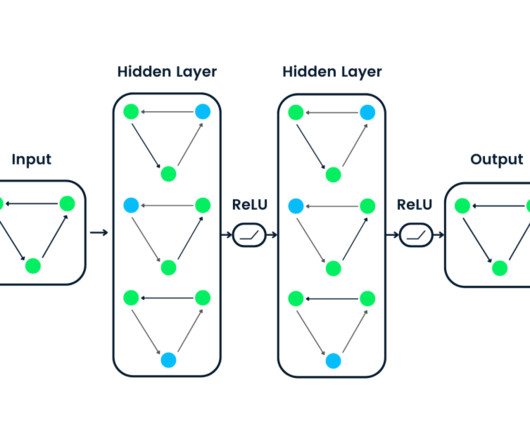
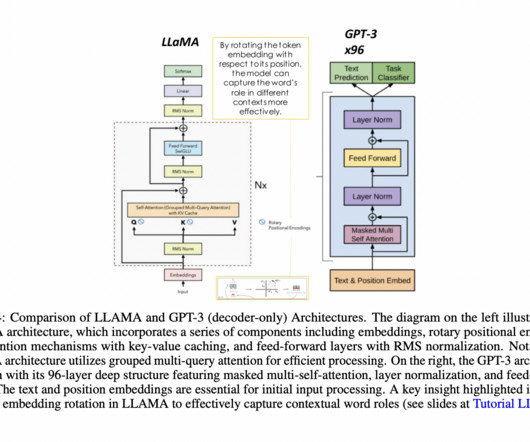
LargeLanguageModels (LLMs) have revolutionized natural language processing, demonstrating remarkable capabilities in various applications. The architecture processes tokenized input through embedding layers, applies multi-headed self-attention, and incorporates positional encoding to retain sequence order information.
LargeLanguageModels have shown immense growth and advancements in recent times. The field of Artificial Intelligence is booming with every new release of these models. Famous LLMs like GPT, BERT, PaLM, and LLaMa are revolutionizing the AI industry by imitating humans.
The well-known LargeLanguageModels (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in Natural Language Processing (NLP) and Natural Language Generation (NLG). If you like our work, you will love our newsletter.
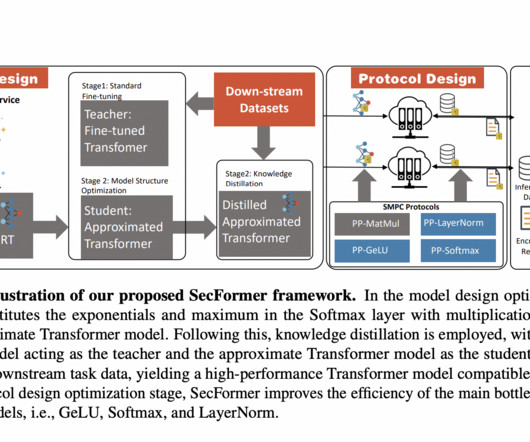
The increasing reliance on cloud-hosted largelanguagemodels for inference services has raised privacy concerns, especially when handling sensitive data. Secure Multi-Party Computing (SMPC) has emerged as a solution for preserving the privacy of both inference data and model parameters. Check out the Paper.
Largelanguagemodels (LLMs) built on transformers, including ChatGPT and GPT-4, have demonstrated amazing natural language processing abilities. The creation of transformer-based NLP models has sparked advancements in designing and using transformer-based models in computer vision and other modalities.
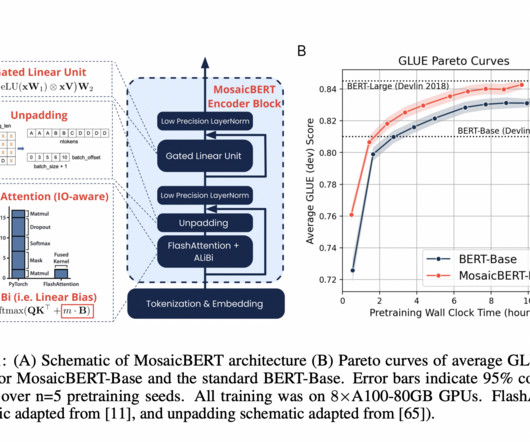
BERT is a languagemodel which was released by Google in 2018. It is based on the transformer architecture and is known for its significant improvement over previous state-of-the-art models. BERT-Base reached an average GLUE score of 83.2% hours taken by BERT-Large. hours compared to 23.35
Computer programs called largelanguagemodels provide software with novel options for analyzing and creating text. It is not uncommon for largelanguagemodels to be trained using petabytes or more of text data, making them tens of terabytes in size.
ChatGPT is part of a group of AI systems called LargeLanguageModels (LLMs) , which excel in various cognitive tasks involving natural language. In the context of languagemodels, an increase in number of parameters translates to an increase in an LM’s storage capacity.
This method involves hand-keying information directly into the target system. But these solutions cannot guarantee 100% accurate results. Text Pattern Matching Text pattern matching is a method for identifying and extracting specific information from text using predefined rules or patterns.
But more than MLOps is needed for a new type of ML model called LargeLanguageModels (LLMs). LLMs are deep neural networks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code.
As the demand for largelanguagemodels (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. Let’s break down the key components: Model Definition TensorRT-LLM allows you to define LLMs using a simple Python API.
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. The introduction of the transformer architecture has provided a new paradigm for building models that understand and generate human language with unprecedented accuracy and fluency.
In this solution, we fine-tune a variety of models on Hugging Face that were pre-trained on medical data and use the BioBERT model, which was pre-trained on the Pubmed dataset and performs the best out of those tried. We implemented the solution using the AWS Cloud Development Kit (AWS CDK).
In recent years, Natural Language Processing (NLP) has undergone a pivotal shift with the emergence of LargeLanguageModels (LLMs) like OpenAI's GPT-3 and Google’s BERT. Beyond traditional search engines, these models represent a new era of intelligent Web browsing agents that go beyond simple keyword searches.
Photo by david clarke on Unsplash The most recent breakthroughs in languagemodels have been the use of neural network architectures to represent text. There is very little contention that largelanguagemodels have evolved very rapidly since 2018. Both BERT and GPT are based on the Transformer architecture.
Recent innovations include the integration and deployment of LargeLanguageModels (LLMs), which have revolutionized various industries by unlocking new possibilities. More recently, LLM-based intelligent agents have shown remarkable capabilities, achieving human-like performance on a broad range of tasks.
Encoder models like BERT and RoBERTa have long been cornerstones of natural language processing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. Recent fine-tuning advancements masked these issues but failed to modernize the core models. faster than ModernBERT, despite larger size.
It can find information based on meaning and remember things for a long time. These models are trained on diverse datasets, enabling them to create embeddings that capture a wide array of linguistic nuances. Semantic Information Retrieval : Traditional search methods rely on exact keyword matches.
Name entity recognition (NER) is the process of extracting information of interest, called entities , from structured or unstructured text. Manually identifying all mentions of specific types of information in documents is extremely time-consuming and labor-intensive. For this post, we used Amazon SageMaker notebooks with ml.t3.medium
It has been able to successfully improve the performance of various NLP tasks, such as sentiment analysis, question answering, natural language inference, named entity recognition, and textual similarity. Models like GPT, BERT, and PaLM are getting popular for all the good reasons.
In order to bring down training time from weeks to days, or days to hours, and distribute a largemodel’s training job, we can use an EC2 Trn1 UltraCluster, which consists of densely packed, co-located racks of Trn1 compute instances all interconnected by non-blocking petabyte scale networking. run_dp_bert_large_hf_pretrain_bf16_s128.sh"
The prowess of LargeLanguageModels (LLMs) such as GPT and BERT has been a game-changer, propelling advancements in machine understanding and generation of human-like text. These models have mastered the intricacies of language, enabling them to tackle tasks with remarkable accuracy.
Over the past few years, LargeLanguageModels (LLMs) have garnered attention from AI developers worldwide due to breakthroughs in Natural Language Processing (NLP). These models have set new benchmarks in text generation and comprehension.
LargeLanguageModels (LLMs) have proven to be really effective in the fields of Natural Language Processing (NLP) and Natural Language Understanding (NLU). Famous LLMs like GPT, BERT, PaLM, etc., Being trained on massive amounts of datasets, these LLMs capture a vast amount of knowledge.
On the other hand, the area of law demands thorough investigation and the creation of a unique legal model due to its intrinsic relevance and need for accuracy. Legal practitioners rely on accurate and current information to make wise judgments, understand the law, and offer legal advice.
Counselling session by a therapist In our work on medical diagnosis, we have focused on identifying conditions such as depression and anxiety for suicide risk detection using largelanguagemodels (LLMs). Going anonymous for self-expression has bundled these forums with information that is quite useful for mental health studies.
When it comes to natural language processing (NLP) and information retrieval, the ability to efficiently and accurately retrieve relevant information is paramount. Retrieval : The system queries a vector database or document collection to find information relevant to the user's query.
GPT 4, the latest version of languagemodels released by OpenAI, is multimodal in nature, i.e., it takes in input in the form of text and images, unlike the previous versions.
The excellent technological advancements, particularly in the areas of LargeLanguageModels (LLMs), LangChain, and Vector Databases, are responsible for this remarkable development. LargeLanguageModels The development of LargeLanguageModels (LLMs) represents a huge step forward for Artificial Intelligence.
With various foundational ideas from largelanguagemodels and text-to-image generation being adapted and incorporated into the audio modality , the latest AI-powered audio-generative systems are reaching a new unprecedented level of quality. This trend has recently begun to shift.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERTmodel to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERTmodel on a target task using a domain-specific dataset.
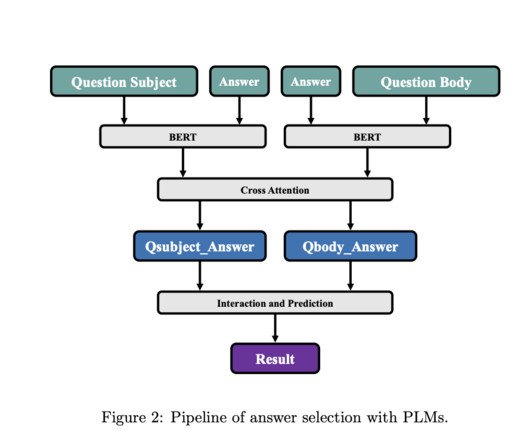
Answers, and StackOverflow, serve as interactive hubs for information exchange. Despite their popularity, the varying quality of responses poses a challenge for users who must navigate through numerous answers to find relevant information efficiently. The QAN model comprises three layers. Answers dataset.
Traditional NLP methods like CNN, RNN, and LSTM have evolved with transformer architecture and largelanguagemodels (LLMs) like GPT and BERT families, providing significant advancements in the field. RALMs’ languagemodels are categorized into autoencoder, autoregressive, and encoder-decoder models.
The spotlight is also on DALL-E, an AI model that crafts images from textual inputs. One such model that has garnered considerable attention is OpenAI's ChatGPT , a shining exemplar in the realm of LargeLanguageModels. These include few-shot learning, ReAct, chain-of-thought, RAG, and more.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















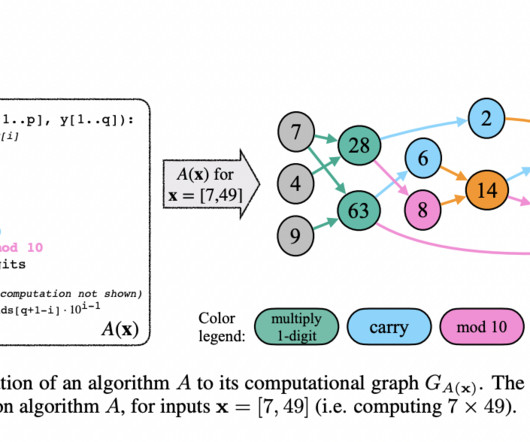











Let's personalize your content