This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These intelligent systems can understand user queries, provide relevant information, and assist with various tasks. One crucial component that aids in this process is slot […] The post Enhancing Conversational AI with BERT: The Power of Slot Filling appeared first on Analytics Vidhya.
In this article, we will delve into how Legal-BERT [5], a transformer-based model tailored for legal texts, can be fine-tuned to classify contract provisions using the LEDGAR dataset [4] — a comprehensive benchmark dataset specifically designed for the legal field. Fine-tuning Legal-BERT for multi-class classification of legal provisions.
Some people might use social media to spread false information. […] The post Building a Multi-Task Model for Fake and Hate Probability Prediction with BERT appeared first on Analytics Vidhya. However, it also has its darker side and that is the widespread of fake and hate content.
It results in sparse and high-dimensional vectors that do not capture any semantic or syntactic information about the words. They struggled with long-term dependencies due to the vanishing gradient problem, where information gets lost over long sequences, making it challenging to learn correlations between distant events.
It is used to detect the entities in text for further use in the downstream tasks as some text/words are more informative and essential for a given context than others. […]. The post Fine-tune BERT Model for Named Entity Recognition in Google Colab appeared first on Analytics Vidhya.
However, despite these abilities, how LLMs store and retrieve information differs significantly from human memory. Short-term memory, on the other hand, holds information briefly, allowing us to manage small details for immediate use. How LLMs Process and Store Information?
Dear readers, In this blog, we will build a Flask web app that can input any long piece of information such as a blog or news article and summarize it into just five lines! SBERT(Sentence-BERT) has […]. This article was published as a part of the Data Science Blogathon.
Through extensive analysis, the researchers found that mid-depth layers in autoregressive transformers undergo significant information compression that ultimately helps them better capture and distill relevant features. This is because these layers strike an optimal balance between preserving task-relevant information and discarding noise.
This article introduces UltraFastBERT, a BERT-based framework matching the efficacy of leading BERT models but using just 0.3% of the available neurons while delivering results comparable to BERT models with a similar size and training process, especially on the downstream tasks.
BERT is a language model which was released by Google in 2018. As such, it has been the powerhouse of numerous natural language processing (NLP) applications since its inception, and even in the age of large language models (LLMs), BERT-style encoder models are used in tasks like vector embeddings and retrieval augmented generation (RAG).
In this guide, we will explore how to fine-tune BERT, a model with 110 million parameters, specifically for the task of phishing URL detection. Phishing is a form of cybercrime where attackers impersonate legitimate entities to deceive individuals into revealing sensitive information, such as usernames, passwords, or credit card details.
A few years back, two groundbreaking models, BERT and GPT, emerged as game-changers. While BERT and GPT laid a strong foundation and opened doors to possibilities, researchers and technologists are now building upon that, pushing boundaries and exploring uncharted territories. Then there’s GPT, the Generative Pre-trained Transformer.
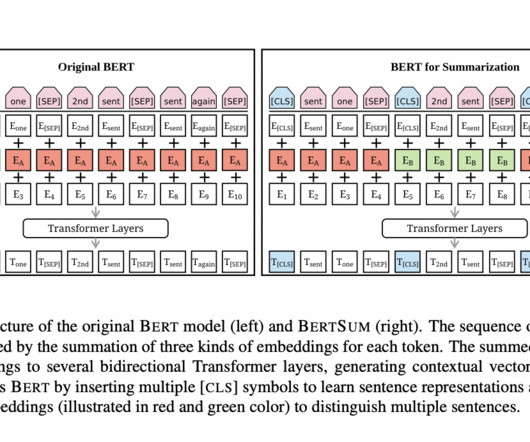
Models like GPT, BERT, and PaLM are getting popular for all the good reasons. The well-known model BERT, which stands for Bidirectional Encoder Representations from Transformers, has a number of amazing applications. Recent research investigates the potential of BERT for text summarization.
Both BERT and GPT are based on the Transformer architecture. They process inputs sequentially, maintaining a hidden state that captures information about previous inputs, making them suitable for tasks like time series prediction and natural language processing. These were followed by the breakthrough of the Attention Mechanism.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
It can find information based on meaning and remember things for a long time. BERT and its Variants : BERT (Bidirectional Encoder Representations from Transformers) by Google, is another significant model that has seen various updates and iterations like RoBERTa, and DistillBERT. Conclusion The AI world is changing fast.
In recent years, Natural Language Processing (NLP) has undergone a pivotal shift with the emergence of Large Language Models (LLMs) like OpenAI's GPT-3 and Google’s BERT. Web browsing agents have traditionally been used for information retrieval through keyword searches. It helps the agent be aware of its digital environment.
Encoder models like BERT and RoBERTa have long been cornerstones of natural language processing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. While newer models like GTE and CDE improved fine-tuning strategies for tasks like retrieval, they rely on outdated backbone architectures inherited from BERT.
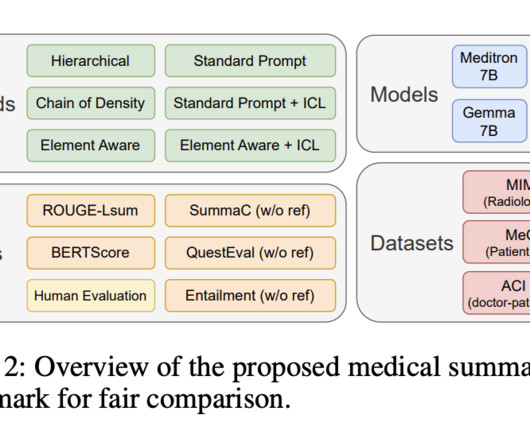
Medical abstractive summarization faces challenges in balancing faithfulness and informativeness, often compromising one for the other. They introduce uMedSum, a modular hybrid framework designed to enhance faithfulness and informativeness by sequentially removing confabulations and adding missing information.
Active learning helps optimize this process by selecting the most informative unlabeled samples for annotation, reducing the labeling effort. Active learning enables a model to request labels for the most informative unlabeled samples, reducing annotation costs.
Every Website, Every App, Every Piece of Content Youre Already Consuming AI-Generated Information, and You Dont Even Know It. And what does it mean for the way we consume and trust online information? Author(s): Mukundan Sankar Originally published on Towards AI. This member-only story is on us. Upgrade to access all of Medium.
Going anonymous for self-expression has bundled these forums with information that is quite useful for mental health studies. After a detailed evaluation of traditional classifiers and transformer-based models like BERT and GPT-3, MentalBERT and BERT became the best-performing models, achieving a fantastic F1 score of over 76%.
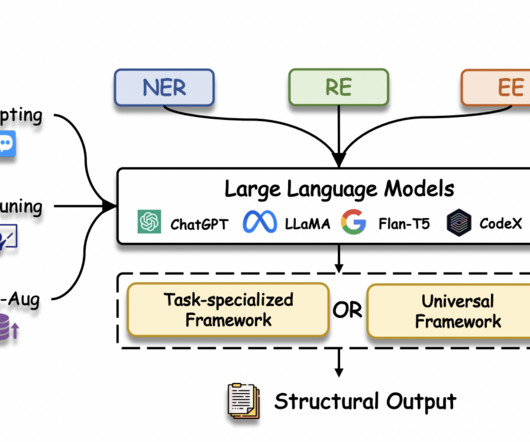
One of the most important areas of NLP is information extraction (IE), which takes unstructured text and turns it into structured knowledge. So, instead of extracting structural information from plain text, generative IE approaches that use LLMs to create structural information has recently become very popular.
These networks emulate the way human neurons transmit electrical signals, processing information through interconnected nodes. Their approach began with an existing artificial neuron model, S-Bert, known for its language comprehension capabilities.
This method involves hand-keying information directly into the target system. But these solutions cannot guarantee 100% accurate results. Text Pattern Matching Text pattern matching is a method for identifying and extracting specific information from text using predefined rules or patterns.
Generative models are prone to “hallucination”, meaning they can produce incorrect or misleading information if they lack the correct context or are fed noisy data. This is valuable in the context of RAG because it ensures that the generative model has access to high-quality, contextually appropriate information.
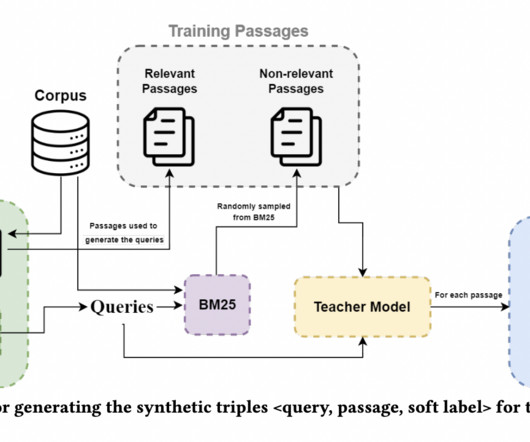
The practical deployment of multi-billion parameter neural rankers in real-world systems poses a significant challenge in information retrieval (IR). Pseudo-labels from advanced cross-encoder models like BERT are one of the methods for generating synthetic data for domain adaptation of dense passage retrievers.
Audio signals can be represented as waveforms , possessing specific characteristics such as frequency, amplitude, and phase , whose different combinations can encode various types of information like pitch and loudness in sound. Map a prompt , a description of the desired audio qualities and its content, to a generated waveform output.
When it comes to natural language processing (NLP) and information retrieval, the ability to efficiently and accurately retrieve relevant information is paramount. Retrieval : The system queries a vector database or document collection to find information relevant to the user's query.
Mutual Information Maximization : Maximizing the mutual information between local node representations and a target representation like the global graph embedding. Beyond better text encoders, LLMs can be used to generate augmented information from the original text attributes in a semi-supervised manner.
LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). Likewise, Hugging Face is an AI company that provides an NLP platform, including a library and a hub of pre-trained LLMs, such as BERT, GPT-3, and T5. However, LLMs are also very different from other models.
By leveraging advances in artificial intelligence (AI) and neuroscience, researchers are developing systems that can translate the complex signals produced by our brains into understandable information, such as text or images. This process effectively translates brainwaves into a personalized dictionary.
An analysis of the MT-BERT multi-teacher distillation method. A simple example of this approach might involve several teacher models, each specializing in a specific type of knowledge, such as feature-based or response-based information. Created Using Midjourney In this issue: An introduction to multi-teacher distillation. Read more
Large language models (LLMs) , such as GPT-4 , BERT , Llama , etc., Once an interaction ends, all prior information is lost, requiring users to start anew with each use. Once an interaction ends, all prior information is lost, requiring users to start anew with each use. Scalability is one of the most pressing issues.
For example, organizations can use generative AI to: Quickly turn mountains of unstructured text into specific and usable document summaries, paving the way for more informed decision-making. While advanced models can handle diverse data types, some excel at specific tasks, like text generation, information summary or image creation.
This model consists of two primary modules: A pre-trained BERT model is employed to extract pertinent information from the input text, and A diffusion UNet model processes the output from BERT. It is built upon a pre-trained BERT model. The E3 TTS employs an iterative refinement process to generate an audio waveform.
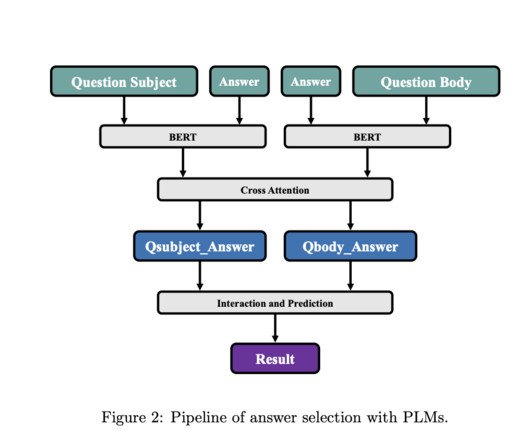
Answers, and StackOverflow, serve as interactive hubs for information exchange. Despite their popularity, the varying quality of responses poses a challenge for users who must navigate through numerous answers to find relevant information efficiently. Community Question Answering (CQA) platforms, exemplified by Quora, Yahoo!
While large language models (LLMs) like GPT-3 and Llama are impressive in their capabilities, they often need more information and more access to domain-specific data. Retrieval-augmented generation (RAG) solves these challenges by combining LLMs with information retrieval.
Discover the concept of attention mechanism – a powerful approach that enables language models to concentrate on particular input sequence segments in order to understand contextual information. Covers the different NLP tasks for which a BERT model is used. Learn how it operates and its uses. What will AI enthusiasts learn?
To prevent these scenarios, protection of data, user assets, and identity information has been a major focus of the blockchain security research community, as to ensure the development of the blockchain technology, it is essential to maintain its security.
For encoder-only architectures like BERT, the model learns to predict missing words in a sentence. A higher value allows to capture more information (better performance), but increases memory usage. This stage involves defining the model architecture, selecting the tokenizer and processing the data using the tokenizers vocabulary.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini.
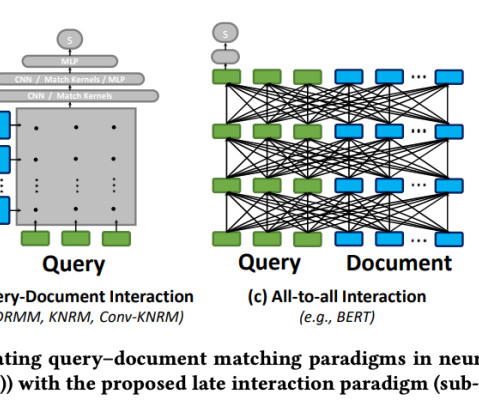
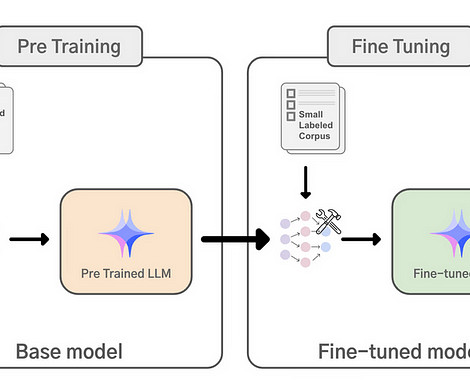
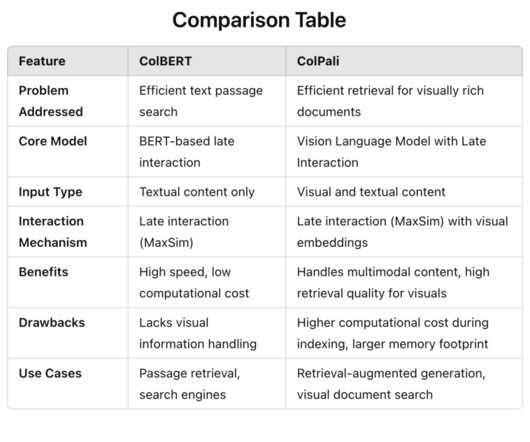
ColBERT seeks to enhance the effectiveness of passage search by leveraging deep pre-trained language models like BERT while maintaining a lower computational cost through late interaction techniques. Key Elements Key elements of ColBERT include the use of BERT for context encoding and a novel late interaction architecture.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content