This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Natural Language Processing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. The introduction of word embeddings, most notably Word2Vec, was a pivotal moment in NLP. One-hot encoding is a prime example of this limitation.
A Complete Guide to Embedding For NLP & Generative AI/LLM By Mdabdullahalhasib This article provides a comprehensive guide to understanding and implementing vector embedding in NLP and generative AI. It also explores caching embeddings using LangChain to speed up the process and make it more efficient.
In recent years, Natural Language Processing (NLP) has undergone a pivotal shift with the emergence of Large Language Models (LLMs) like OpenAI's GPT-3 and Google’s BERT. These models, characterized by their large number of parameters and training on extensive text corpora, signify an innovative advancement in NLP capabilities.
link] Proposes an explainability method for language modelling that explains why one word was predicted instead of a specific other word. Adapts three different explainability methods to this contrastive approach and evaluates on a dataset of minimally different sentences. UC Berkeley, CMU. EMNLP 2022. Imperial, Cambridge, KCL.
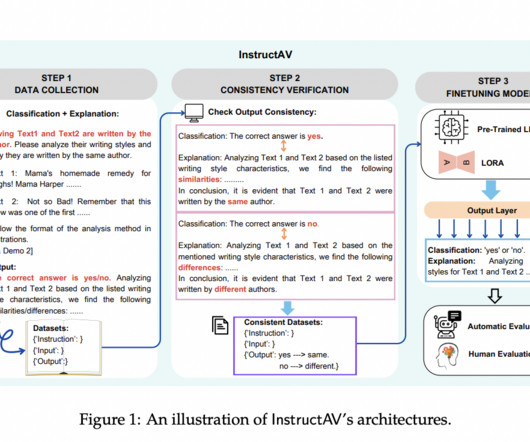
Authorship Verification (AV) is critical in natural language processing (NLP), determining whether two texts share the same authorship. With deep learning models like BERT and RoBERTa, the field has seen a paradigm shift. This lack of explainability is a gap in academic interest and a practical concern.
In recent years, remarkable strides have been achieved in crafting extensive foundation language models for natural language processing (NLP). As previously explained, spend data is more readily available in an organization and is a common proxy of quantity of goods/services.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. Solution overview In this section, we present the overall workflow and explain the approach.
Additionally, the models themselves are created from limited architectures: “Almost all state-of-the-art NLP models are now adapted from one of a few foundation models, such as BERT, RoBERTa, BART, T5, etc. How are you making your model explainable? Typical questions include: What is your model’s use case?
SHAP's strength lies in its consistency and ability to provide a global perspective – it not only explains individual predictions but also gives insights into the model as a whole. Flawed Decision Making The opaqueness in the decision-making process of LLMs like GPT-3 or BERT can lead to undetected biases and errors.
But now, a computer can be taught to comprehend and process human language through Natural Language Processing (NLP), which was implemented, to make computers capable of understanding spoken and written language. This article will explain to you in detail about RoBERTa and if you do not know about BERT please click on the associated link.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Natural Language Processing on Google Cloud This course introduces Google Cloud products and solutions for solving NLP problems.
BERT is a state-of-the-art algorithm designed by Google to process text data and convert it into vectors ([link]. What makes BERT special is, apart from its good results, the fact that it is trained over billions of records and that Hugging Face provides already a good battery of pre-trained models we can use for different ML tasks.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Impact V.2
Explainability of machine learning (ML) models used in the medical domain is becoming increasingly important because models need to be explained from a number of perspectives in order to gain adoption. Explainability of these predictions is required in order for clinicians to make the correct choices on a patient-by-patient basis.
Researchers and practitioners explored complex architectures, from transformers to reinforcement learning , leading to a surge in sessions on natural language processing (NLP) and computervision. Topics such as explainability (XAI) and AI governance gained traction, reflecting the growing societal impact of AI technologies.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy. An open-source model, Google created BERT in 2018. All watsonx.ai
The following is a brief tutorial on how BERT and Transformers work in NLP-based analysis using the Masked Language Model (MLM). Introduction In this tutorial, we will provide a little background on the BERT model and how it works. The BERT model was pre-trained using text from Wikipedia. What is BERT?
Many people in NLP seem to think that you need to work with the latest and trendiest technology in order to be relevant, both in research and in applications. At the time, the latest and trendiest NLP technology was LSTM (and variants such as biLSTM). LSTMs worked very well in lots of areas of NLP, including machine translation.
Let's create an advanced prompt where ChatGPT is tasked with summarizing key takeaways from AI and NLP research papers. Using the few-shot learning approach, let's teach ChatGPT to summarize key findings from AI and NLP research papers: 1.
The Boom of Generative AI and Large Language Models(LLMs) 20182020: NLP was gaining traction, with a focus on word embeddings, BERT, and sentiment analysis. The Boom of Generative AI and Large Language Models(LLMs) 20182020: NLP was gaining traction, with a focus on word embeddings, BERT, and sentiment analysis.
Many different transformer models have already been implemented in Spark NLP, and specifically for text classification, Spark NLP provides various annotators that are designed to work with pretrained language models. BERT-based Transformers are a family of deep learning models that use the transformer architecture.
Consequently, there’s been a notable uptick in research within the natural language processing (NLP) community, specifically targeting interpretability in language models, yielding fresh insights into their internal operations.
One of the most important areas of NLP is information extraction (IE), which takes unstructured text and turns it into structured knowledge. At the same time, Llama and other large language models have emerged and are revolutionizing NLP with their exceptional text understanding, generation, and generalization capabilities.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. Natural Language Processing (NLP) is a subfield of artificial intelligence.
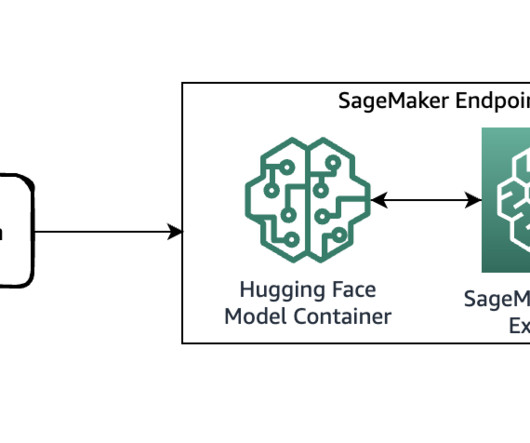
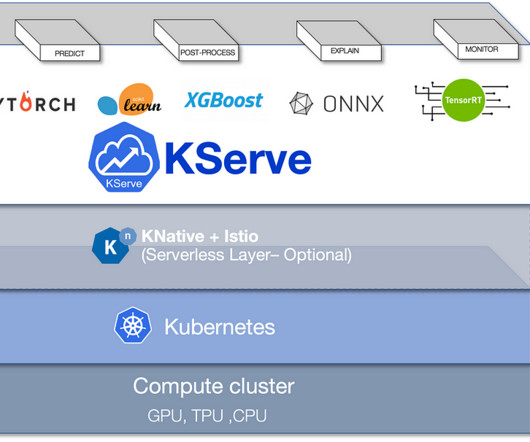
The Future of NLP Deployment: BERT Models and KServe in Action In this post, I will demonstrate how to deploy a HuggingFace pre-trained model (BERT for text classification with the Hugging Face Transformers library) to run as a KServe-hosted model. First, let’s understand what is KServe and why we need KServe. ?What
In recent years, researchers have also explored using GCNs for natural language processing (NLP) tasks, such as text classification , sentiment analysis , and entity recognition. This article provides a brief overview of GCNs for NLP tasks and how to implement them using PyTorch and Comet.
image by rawpixel.com Understanding the concept of language models in natural language processing (NLP) is very important to anyone working in the Deep learning and machine learning space. They are essential to a variety of NLP activities, including speech recognition, machine translation, and text summarization.
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., ” Even for seasoned programmers, the syntax of shell commands might need to be explained. rely on Language Models as their foundation.
CaseHOLD is a new dataset for legal NLP tasks. The CaseHOLD dataset was created to address the lack of large-scale, domain-specific datasets for legal NLP. The dataset is a valuable resource for researchers working on legal NLP as it is the first large-scale, domain-specific dataset for this task. This is where BioBERT comes in.
This post gathers ten ML and NLP research directions that I found exciting and impactful in 2019. Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al., 2019 ) and other variants. Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al.,
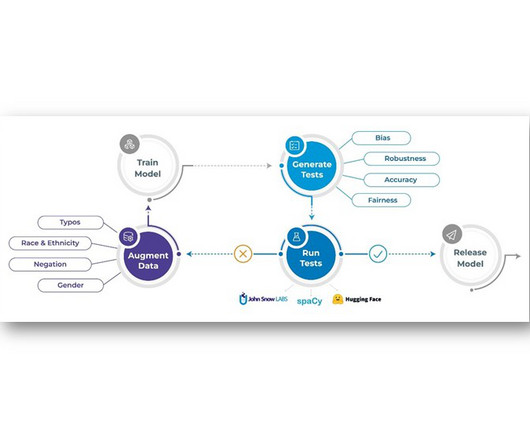
The underlying principles behind the NLP Test library: Enabling data scientists to deliver reliable, safe and effective language models. Explainability and Interpretability: Models should be capable of answer stakeholder questions about the decision-making processes of AI systems. Finally, [ van Aken et.
If you are interested in NLP, contact him in the thread! It breaks down each step of the process, explaining key concepts and providing detailed instructions to help you understand and implement your own NL2SQL system. They are looking for someone to work on this and a potential co-founder.
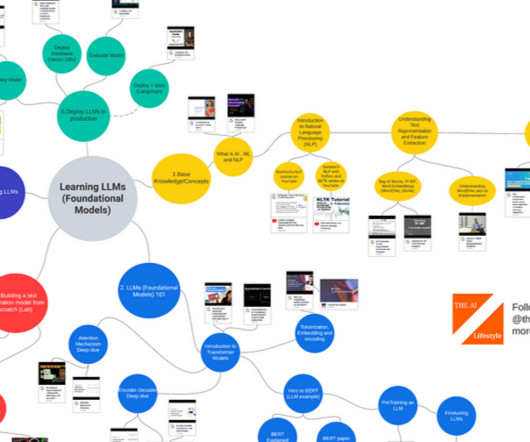
Learning LLMs (Foundational Models) Base Knowledge / Concepts: What is AI, ML and NLP Introduction to ML and AI — MFML Part 1 — YouTube What is NLP (Natural Language Processing)? — YouTube YouTube Introduction to Natural Language Processing (NLP) NLP 2012 Dan Jurafsky and Chris Manning (1.1) YouTube BERT Research — Ep.
Introducing Natural Language Processing (NLP) , a branch of artificial intelligence (AI) specifically designed to give computers the ability to understand text and spoken words in much the same way as human beings. One of the key areas where NLP shines is in the field of text classification. So, how do they do that? How it works?
Implementing end-to-end deep learning projects has never been easier with these awesome tools Image by Freepik LLMs such as GPT, BERT, and Llama 2 are a game changer in AI. Here are the topics we’ll cover in this article: Fine-tuning the BERT model with the Transformers library for text classification. Monitoring this app with Comet.
That work inspired researchers who created BERT and other large language models , making 2018 a watershed moment for natural language processing, a report on AI said at the end of that year. Google released BERT as open-source software , spawning a family of follow-ons and setting off a race to build ever larger, more powerful LLMs.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
2021) 2021 saw many exciting advances in machine learning (ML) and natural language processing (NLP). 6] such as W2v-BERT [7] as well as more powerful multilingual models such as XLS-R [8]. If CNNs are pre-trained the same way as transformer models, they achieve competitive performance on many NLP tasks [28]. What happened?
In Part 1 (fine-tuning a BERT model), I explained what a transformer model is and the various open source models types that are available from Hugging Face’s free transformers library. We also walked through how to fine-tune a BERT model to conduct sentiment analysis. In Part… Read the full blog for free on Medium.
input saliency is a method that explains individual predictions. This is a method of attribution explaining the relationship between a model's output and inputs -- helping us detect errors and biases, and better understand the behavior of the system. Multiple methods exist for assigning importance scores to the inputs of an NLP model.
One of the most popular techniques for speech recognition is natural language processing (NLP), which entails training machine learning models on enormous amounts of text data to understand linguistic patterns and structures. The RoBERTa model has recently emerged as a powerful tool for NLP tasks, including speech recognition.
But if you’re working on the same sort of Natural Language Processing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them? In 2014 I started working on spaCy , and here’s an excerpt of how I explained the motivation for the library: Computers don’t understand text.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content