This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
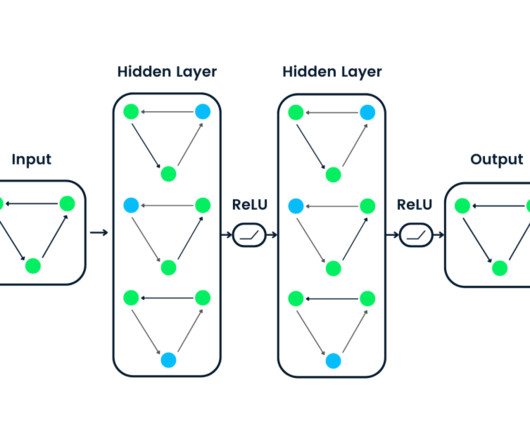
Recurrent NeuralNetworks (RNNs) became the cornerstone for these applications due to their ability to handle sequential data by maintaining a form of memory. Functionality : Each encoder layer has self-attention mechanisms and feed-forward neuralnetworks. However, RNNs were not without limitations.
The ability to effectively represent and reason about these intricate relational structures is crucial for enabling advancements in fields like network science, cheminformatics, and recommender systems. Graph NeuralNetworks (GNNs) have emerged as a powerful deep learning framework for graph machine learning tasks.
Almost thirty years later, upon Wirths passing in January 2024, lifelong technologist Bert Hubert revisited Wirths plea and despaired at how catastrophically worse the state of software bloat has become. Contributing editor Charles Choi annotated the story, explaining how the fictionalized world draws on real science and tech.
It includes deciphering neuralnetwork layers , feature extraction methods, and decision-making pathways. These systems rely heavily on neuralnetworks to process vast amounts of information. During training, neuralnetworks learn patterns from extensive datasets.
NeuralNetwork: Moving from Machine Learning to Deep Learning & Beyond Neuralnetwork (NN) models are far more complicated than traditional Machine Learning models. Advances in neuralnetwork techniques have formed the basis for transitioning from machine learning to deep learning.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. Solution overview In this section, we present the overall workflow and explain the approach.
Introduction to Generative AI: This course provides an introductory overview of Generative AI, explaining what it is and how it differs from traditional machine learning methods. It introduces learners to responsible AI and explains why it is crucial in developing AI systems.
Project Structure Accelerating Convolutional NeuralNetworks Parsing Command Line Arguments and Running a Model Evaluating Convolutional NeuralNetworks Accelerating Vision Transformers Evaluating Vision Transformers Accelerating BERT Evaluating BERT Miscellaneous Summary Citation Information What’s New in PyTorch 2.0?
SHAP's strength lies in its consistency and ability to provide a global perspective – it not only explains individual predictions but also gives insights into the model as a whole. Flawed Decision Making The opaqueness in the decision-making process of LLMs like GPT-3 or BERT can lead to undetected biases and errors.
By 2017, deep learning began to make waves, driven by breakthroughs in neuralnetworks and the release of frameworks like TensorFlow. Sessions on convolutional neuralnetworks (CNNs) and recurrent neuralnetworks (RNNs) started gaining popularity, marking the beginning of data sciences shift toward AI-driven methods.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. It covers how to develop NLP projects using neuralnetworks with Vertex AI and TensorFlow. It also includes guidance on using Google Tools to develop your own Generative AI applications.
Summary: Neuralnetworks are a key technique in Machine Learning, inspired by the human brain. Different types of neuralnetworks, such as feedforward, convolutional, and recurrent networks, are designed for specific tasks like image recognition, Natural Language Processing, and sequence modelling.
BERT is a state-of-the-art algorithm designed by Google to process text data and convert it into vectors ([link]. What makes BERT special is, apart from its good results, the fact that it is trained over billions of records and that Hugging Face provides already a good battery of pre-trained models we can use for different ML tasks.
Prompt 1 : “Tell me about Convolutional NeuralNetworks.” ” Response 1 : “Convolutional NeuralNetworks (CNNs) are multi-layer perceptron networks that consist of fully connected layers and pooling layers. They are commonly used in image recognition tasks. .”
In this article, we take an overview of some exciting new advances in the space of Generative AI for audio that have all happened in the past few months , explaining where the key ideas come from and how they come together to bring audio generation to a new level. At its core, it's an end-to-end neuralnetwork-based approach.
Concept-driven methods explain the decisions of a model by aligning its representation with human understandable concepts. Researchers from the University of Wisconsin-Madison propose a framework named “Missingness-aware Causal Concept Explainer “to capture the impact of unobserved concepts in data.
They said transformer models , large language models (LLMs), vision language models (VLMs) and other neuralnetworks still being built are part of an important new category they dubbed foundation models. Earlier neuralnetworks were narrowly tuned for specific tasks.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
Central to this progress is the concept of scaling laws rules that explain how AI models improve as they grow, are trained on more data, or are powered by greater computational resources. Early neuralnetworks like AlexNet and ResNet demonstrated how increasing model size could improve image recognition.
A foundation model is built on a neuralnetwork model architecture to process information much like the human brain does. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018.
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
The Boom of Generative AI and Large Language Models(LLMs) 20182020: NLP was gaining traction, with a focus on word embeddings, BERT, and sentiment analysis. 20212024: With automated insights and AI-driven analytics improving, the emphasis shifted from visualization to explainability and storytelling.
Existing surveys detail a range of techniques utilized in Explainable AI analyses and their applications within NLP. While earlier surveys predominantly centred on encoder-based models such as BERT, the emergence of decoder-only Transformers spurred advancements in analyzing these potent generative models.
AI judges must be scalable yet cost-effective , unbiased yet adaptable , and reliable yet explainable. An LLM: the neuralnetwork that takes in the final prompt and renders verdict. Justification request : Explain why this response was rated higher. However, challenges remain. False - The response is noncompliant.
Transformers are defined as a specific type of neuralnetwork architecture that have proven to be particularly effective for sequence classification tasks, thanks to their ability to capture long-term dependencies and contextual relationships in the data. The transformer architecture was introduced by Vaswani et al.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. BERT (Bidirectional Encoder Representations from Transformers) — developed by Google.
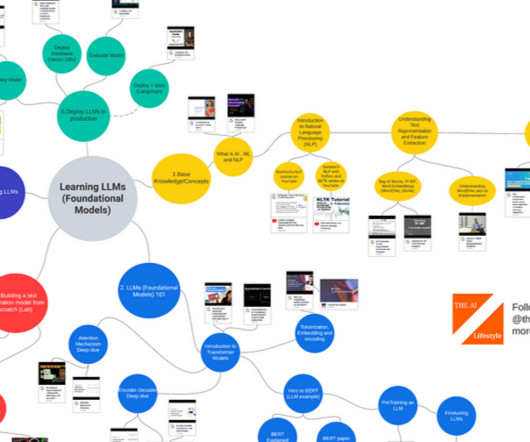
LLMs (Foundational Models) 101: Introduction to Transformer Models Transformers, explained: Understand the model behind GPT, BERT, and T5 — YouTube Illustrated Guide to Transformers NeuralNetwork: A step by step explanation — YouTube Attention Mechanism Deep dive. Transformer NeuralNetworks — EXPLAINED!
The code imports various libraries like TensorFlow, PyTorch, Transformers, Tkinter, and CLIP to handle tasks related to neuralnetworks, text classification, and image processing. Featured Community post from the Discord Mahvin_ built a chatbot using ChatGPT. You can try it on GitHub and share your feedback in the Discord thread!
Unigrams, N-grams, exponential, and neuralnetworks are valid forms for the Language Model. ” Even for seasoned programmers, the syntax of shell commands might need to be explained. DeBERTa Microsoft Research proposed decoding-enhanced BERT with disentangled attention to augment BERT and RoBERTa models.
While the Adam optimizer has become the standard for training Transformers, stochastic gradient descent with momentum (SGD), which is highly effective for convolutional neuralnetworks (CNNs), performs worse on Transformer models. This performance gap poses a challenge for researchers. Check out the Paper.
ONNX (Open NeuralNetwork Exchange) is an open-source format that facilitates interoperability between different deep learning algorithms for simple model sharing and deployment. ONNX (Open NeuralNetwork Exchange) is an open-source format. A deep learning framework from Microsoft. Apache MXNet. Apple Core ML.
We also had a number of interesting results on graph neuralnetworks (GNN) in 2022. Furthermore, to bring some of these many advances to the broader community, we had three releases of our flagship modeling library for building graph neuralnetworks in TensorFlow (TF-GNN).
I’m going to explain the detail of Text Classification using Naive Bayes algorithm (Naive Bayes Classifier). Nowdays, there is lot more advanced algorithms for text classification such as BERT, CNN, LSTM, etc. They use a type of computer model called a NeuralNetwork, which is really good at learning from and making sense of data.
Model architectures that qualify as “supervised learning”—from traditional regression models to random forests to most neuralnetworks—require labeled data for training. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
input saliency is a method that explains individual predictions. This is a method of attribution explaining the relationship between a model's output and inputs -- helping us detect errors and biases, and better understand the behavior of the system. Interfaces for Explaining Transformer Language Models [Blog post].
Vector Embeddings for Developers: The Basics | Pinecone Used geometry concept to explain what is vector, and how raw data is transformed to embedding using embedding model. Pinecone Used a picture of phrase vector to explain vector embedding. What are Vector Embeddings? using its Spectrogram ).
BERT + Random Forest. BERT + Random Forest. BERT + Random Forest with HPO. Fuse multiple neuralnetwork models directly and handle raw text (which are also capable of handling additional numerical and categorical columns). BERT + Random Forest. BERT + Random Forest with HPO. BERT + Random Forest.
TensorFlow is an open-source software library for AI and machine learning with deep neuralnetworks. TensorFlow Lite also optimizes the trained model using quantization techniques (discussed later in this article), which consequently reduces the necessary memory usage as well as the computational cost of utilizing neuralnetworks.
Major milestones in the last few years comprised BERT (Google, 2018), GPT-3 (OpenAI, 2020), Dall-E (OpenAI, 2021), Stable Diffusion (Stability AI, LMU Munich, 2022), ChatGPT (OpenAI, 2022). Complex ML problems can only be solved in neuralnetworks with many layers. Deep learning neuralnetwork.
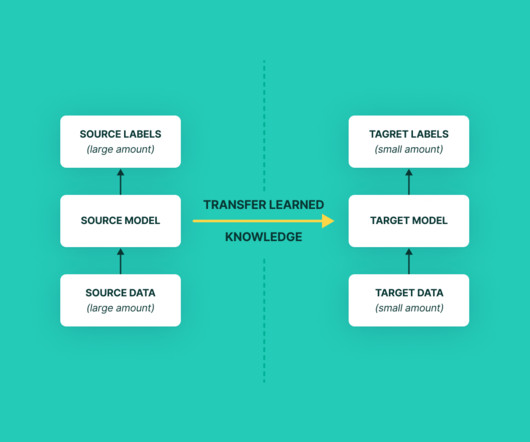
To train a machine learning model or a neuralnetwork that can yield the best results requires what? How can we train a neuralnetwork without having an ample amount of data, even if you have it can you afford to train a model for months? Let me explain this in simple words. This is how transfer learning works.
Formula to calculate n-gram probabilities; image by Peter Martigny on Feedly Neural Language Models Neural language models make use of artificial neuralnetworks to discover the patterns and structures in a language. One of the most popular language models is the Recurrent NeuralNetwork Language Model (RNNLM).
link] Proposes an explainability method for language modelling that explains why one word was predicted instead of a specific other word. Adapts three different explainability methods to this contrastive approach and evaluates on a dataset of minimally different sentences. UC Berkeley, CMU. EMNLP 2022. Imperial, Cambridge, KCL.
The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment. All of this made it easy for researchers and practitioners to use BERT.
The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment. All of this made it easy for researchers and practitioners to use BERT.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content