This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
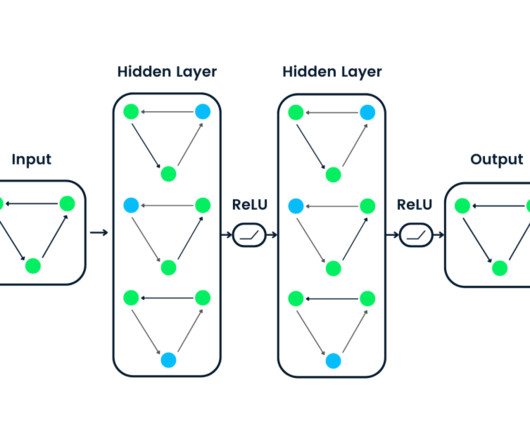
For AI and large language model (LLM) engineers , design patterns help build robust, scalable, and maintainable systems that handle complex workflows efficiently. This article dives into design patterns in Python, focusing on their relevance in AI and LLM -based systems. BERT, GPT, or T5) based on the task.
In recent years, Natural Language Processing (NLP) has undergone a pivotal shift with the emergence of Large Language Models (LLMs) like OpenAI's GPT-3 and Google’s BERT. Using their extensive training data, LLM-based agents deeply understand language patterns, information, and contextual nuances.
The ever-growing presence of artificial intelligence also made itself known in the computing world, by introducing an LLM-powered Internet search tool, finding ways around AIs voracious data appetite in scientific applications, and shifting from coding copilots to fully autonomous coderssomething thats still a work in progress. Perplexity.ai
Quantization explained in plain English When BERT was released around 5 years ago, it triggered a wave of Large Language Models with ever increasing sizes. If you were to dare open an LLM in the Notepad app, you would notice that it is nothing but a set of numbers. Enter Quantization!
LLM-as-Judge has emerged as a powerful tool for evaluating and validating the outputs of generative models. AI judges must be scalable yet cost-effective , unbiased yet adaptable , and reliable yet explainable. AI judges must be scalable yet cost-effective , unbiased yet adaptable , and reliable yet explainable. Lets dive in.
As we wrap up October, we’ve compiled a bunch of diverse resources for you — from the latest developments in generative AI to tips for fine-tuning your LLM workflows, from building your own NotebookLM clone to instruction tuning. We have long supported RAG as one of the most practical ways to make LLMs more reliable and customizable.
SHAP's strength lies in its consistency and ability to provide a global perspective – it not only explains individual predictions but also gives insights into the model as a whole. Impact of the LLM Black Box Problem 1. For example, a medical diagnosis LLM relying on outdated or biased data can make harmful recommendations.
Their comparative analysis included decoder-only transformers like Pythia, encoder-only models like BERT, and state space models (SSMs) like Mamba. The teams latest research expands the analysis to more models and training regimes while offering a comprehensive theoretical framework to explain why intermediate representations excel.
However, some key limitations of traditional GNN-based self-supervised methods remain, which we will explore leveraging LLMs to address next. Beyond better text encoders, LLMs can be used to generate augmented information from the original text attributes in a semi-supervised manner.
An analysis of the MT-BERT multi-teacher distillation method. A review of the Portkey framework for LLM guardrailing. 💡 ML Concept of the Day: Understanding Multi-Teacher Distillation Distillation is typically explained using a teacher-student architecture, where we often conceptualize it as involving a single teacher model.
In 2014 I started working on spaCy , and here’s an excerpt of how I explained the motivation for the library: Computers don’t understand text. I don’t want to undersell how impactful LLMs are for this sort of use-case. You can give an LLM a group of comments and ask it to summarize the texts or identify key themes.
Introduction to Generative AI: This course provides an introductory overview of Generative AI, explaining what it is and how it differs from traditional machine learning methods. It introduces learners to responsible AI and explains why it is crucial in developing AI systems.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explainLLM in simple or to say general language. No need to train the LLM but one only has to think about Prompt design.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Introduction to Generative AI This introductory microlearning course explains Generative AI, its applications, and its differences from traditional machine learning.
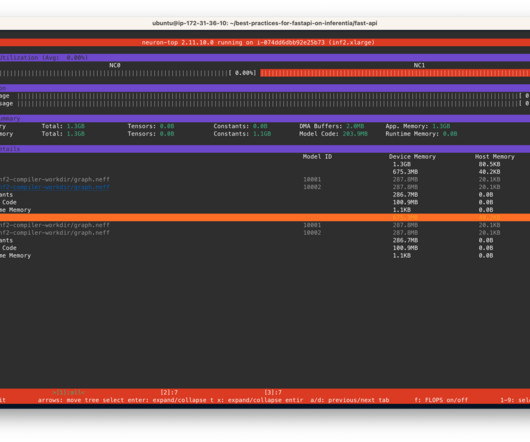
In this post, we use a Hugging Face BERT-Large model pre-training workload as a simple example to explain how to useTrn1 UltraClusters. Launch your training job We use the Hugging Face BERT-Large Pretraining Tutorial as an example to run on this cluster. Each compute node has Neuron tools installed, such as neuron-top.
A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018.
Paper Title: "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" Key Takeaway: Introduced BERT, showcasing the efficacy of pre-training deep bidirectional models, thereby achieving state-of-the-art results on various NLP tasks. This demonstrates a classic case of ‘knowledge conflict'.
Although large language models (LLMs) had been developed prior to the launch of ChatGPT, the latter’s ease of accessibility and user-friendly interface took the adoption of LLM to a new level. It provides codes for working with various models, such as GPT-4, BERT, T5, etc., and explains how they work.
link] The paper investigates LLM robustness to prompt perturbations, measuring how much task performance drops for different models with different attacks. link] The paper proposes query rewriting as the solution to the problem of LLMs being overly affected by irrelevant information in the prompts. ArXiv 2023. Oliveira, Lei Li.
In this article, we take an overview of some exciting new advances in the space of Generative AI for audio that have all happened in the past few months , explaining where the key ideas come from and how they come together to bring audio generation to a new level. This blog post is part of a series on generative AI.
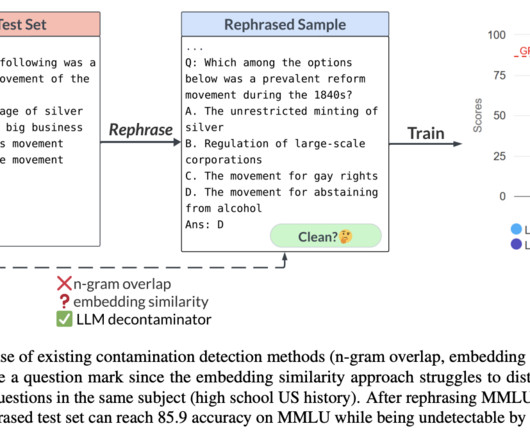
An embedding similarity search looks at the embeddings of previously trained models (like BERT) to discover related and maybe polluted cases. In addition, there is a developing trend in model training that uses synthetic data generated by LLMs (e.g., However, its precision is somewhat low. It’s also found that GPT-3.5’s
LangChain is an open-source framework that allows developers to build LLM-based applications easily. It provides for easily connecting LLMs with external data sources to augment the capabilities of these models and achieve better results. It teaches how to build LLM-powered applications using LangChain using hands-on exercises.
I remember once trying to carefully explain why an LSTM approach was not appropriate for what a potential client wanted to do, and the response was “I’m a techie and I agree with you, but my manager insists that we have to use LSTMs because this is what everyone is talking about.”
Most people who have experience working with large language models such as Google’s Bard or OpenAI’s ChatGPT have worked with an LLM that is general, and not industry-specific. This is why over the last few months multiple examples of domain/industry-specific LLMs have gone live. Well, that’s what CaseHOLD does. So what does it do?
Applications of LLMs The chart below summarises the present state of the Large Language Model (LLM) landscape in terms of features, products, and supporting software. ” Even for seasoned programmers, the syntax of shell commands might need to be explained. It is pre-trained using a generalized autoregressive model.
Whether you’re a developer seeking to incorporate LLMs into your existing systems or a business owner looking to take advantage of the power of NLP, this post can serve as a quick jumpstart. Explainability Provides explanations for its predictions through generated text, offering insights into its decision-making process.
Applying LLMs to make E-commerce search engines robust to colloquial queries Photo by Oberon Copeland @veryinformed.com on Unsplash In recent years, web search engines have been quickly embracing Large Language Models (LLMs) to increase their search capability. One of the most successful examples is Google search powered by BERT [1].
Implementing end-to-end deep learning projects has never been easier with these awesome tools Image by Freepik LLMs such as GPT, BERT, and Llama 2 are a game changer in AI. Here are the topics we’ll cover in this article: Fine-tuning the BERT model with the Transformers library for text classification.
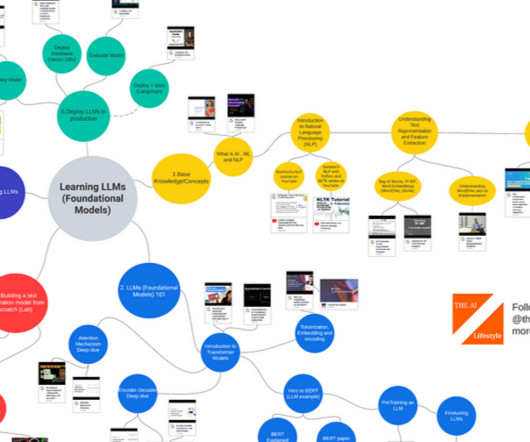
Learning Large Language Models The LLM (Foundational Models) space has seen tremendous and rapid growth. I used this foolproof method of consuming the right information and ended up publishing books , artworks , Podcasts and even an LLM powered consumer facing app ranked #40 on the app store. Transformer Neural Networks — EXPLAINED!
We start off with a baseline foundation model from SageMaker JumpStart and evaluate it with TruLens , an open source library for evaluating and tracking large language model (LLM) apps. These functions can be implemented in several ways, including BERT-style models, appropriately prompted LLMs, and more. args.args[0]).on(Select.Record.calls[0].args.args[1])
The use cases of LLM for chatbots and LLM for conversational AI can be seen across all industries like FinTech, eCommerce, healthcare, cybersecurity, and the list goes on. The next section explains in detail how LLM-powered chatbot solutions help businesses enhance their customer experience.
Examples of LLMs include GPT-3 (Generative Pre-trained Transformer 3) and BERT (Bidirectional Encoder Representations from Transformers). LLMs are trained on massive amounts of data, often billions of words, to develop a broad understanding of language.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
Some examples of large language models include GPT (Generative Pre-training Transformer), BERT (Bidirectional Encoder Representations from Transformers), and RoBERTa (Robustly Optimized BERT Approach). Researchers are developing techniques to make LLM training more efficient.
Hidden secret to empower semantic search This is the third article of building LLM-powered AI applications series. From the previous article , we know that in order to provide context to LLM, we need semantic search and complex query to find relevant context (traditional keyword search, full-text search won’t be enough).
Pre-trained LLMs can be limited by the low quality of their data sources and struggle to adapt to domain-specific tasks. They can be limited in their multi-modality, and they can be difficult to explain, adapt, or control. Starting from an LLM pre-trained on EMR/EHR data, like ehrBERT, UCSF-Bert, and GatorTron, can speed this process.
We compare the existing solutions and explain how they work behind the scenes. Introduction While the concept of AI agents has been around for decades, it is undeniable that recent advancements in Large Language Models (LLMs) have revolutionized this field, opening up a whole new realm of possibilities and applications.
At inference time, users provide “prompts” to the LLM—snippets of text that the model uses as a jumping-off point. BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). The new tool caused a stir.
At inference time, users provide “prompts” to the LLM—snippets of text that the model uses as a jumping-off point. BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). The new tool caused a stir.
Inf2 instances are ideal for Deep Learning workloads like Generative AI, Large Language Models (LLM) in OPT/GPT family and vision transformers like Stable Diffusion. Also in this folder, we provide all the scripts necessary to trace a bert-base-uncased model on AWS Inferentia. code as the entry point. The fastapi-server.py
Pre-trained LLMs can be limited by the low quality of their data sources and struggle to adapt to domain-specific tasks. They can be limited in their multi-modality, and they can be difficult to explain, adapt, or control. Starting from an LLM pre-trained on EMR/EHR data, like ehrBERT, UCSF-Bert, and GatorTron, can speed this process.
LLMs like GPT-3 and T5 have already shown promising results in various NLP tasks such as language translation, question-answering, and summarization. However, LLMs are complex, and training and improving them require specific skills and knowledge. LLMs rely on vast amounts of text data to learn patterns and generate coherent text.
Pre-trained LLMs can be limited by the low quality of their data sources and struggle to adapt to domain-specific tasks. They can be limited in their multi-modality, and they can be difficult to explain, adapt, or control. Starting from an LLM pre-trained on EMR/EHR data, like ehrBERT, UCSF-Bert, and GatorTron, can speed this process.
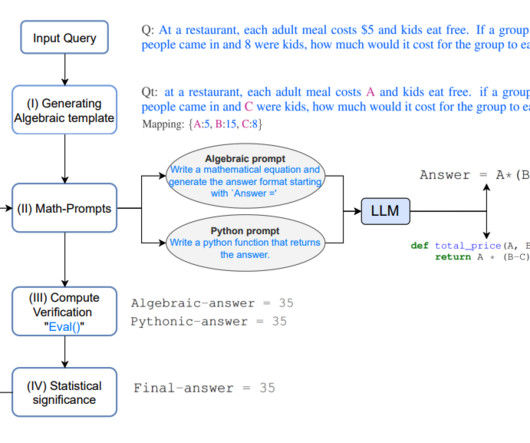
On the other hand, the more demanding the task – the higher the risk of LLM hallucinations. In this article, you’ll find: what the problem with hallucination is, which techniques we use to reduce them, how to measure hallucinations using methods such as LLM-as-a-judge tips and tricks from my experience as an experienced data scientist.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content