This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
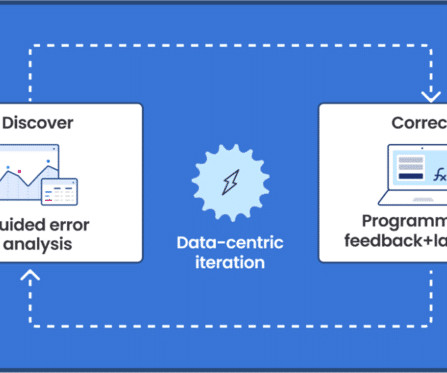
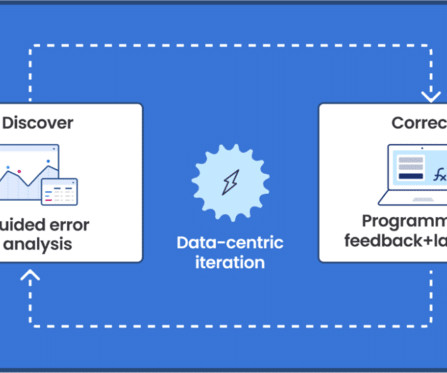
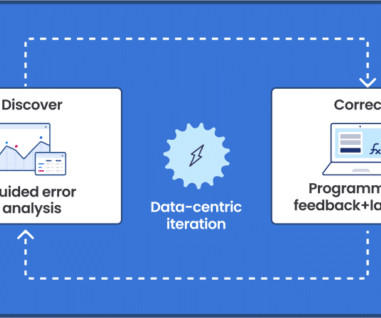
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
Photo by adrianna geo on Unsplash NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.23.20 If you haven’t heard, we released the NLP Model Forge ? NLP Model Forge So… the NLP Model Forge, a collection of 1,400 NLP code snippets that you can seamlessly select to run inference in Colab!
Photo by Kunal Shinde on Unsplash NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.09.20 What is the state of NLP? Where are those commonsense reasoning demos? For an overview of some tasks, see NLP Progress or our XTREME benchmark. Forge Where are we? Where are those graphs?
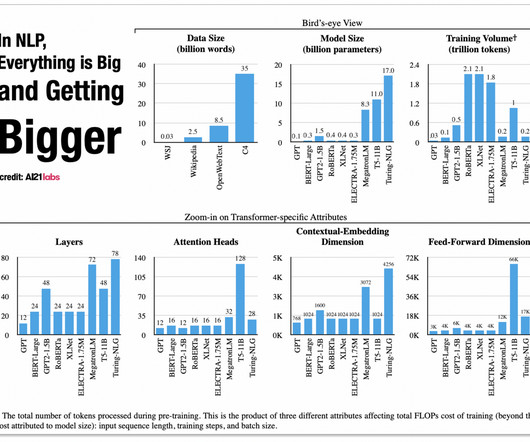
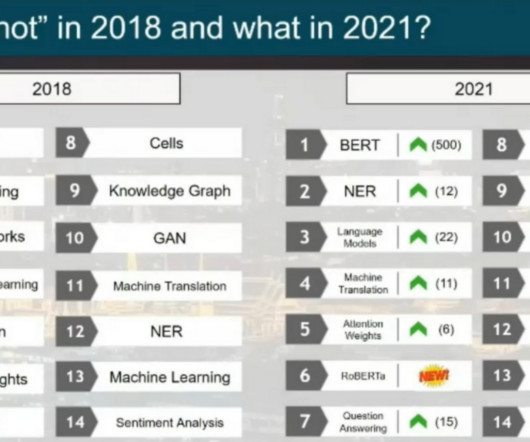
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Natural Language Processing on Google Cloud This course introduces Google Cloud products and solutions for solving NLP problems.
In my previous articles about transformers and GPTs, we have done a systematic analysis of the timeline and development of NLP. Prerequisite Before we dive into understanding BERT, we need to understand in order to create the model, the authors have used or referenced several concepts and improvements from several other preceding works.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
Legal NLP 1.14 comes with a lot of new capabilities added to the 926+ models and 125+ Language Models already available in previous versions of the library. Demo available here. Example of NER on specific NDA clauses Summary of the agreement in 4 lines Subpoenas: Carry out NER on subpoenas using Legal NLP.
John Snow Labs Finance NLP 1.14 This includes questions and queries: LLM demos A new demo has been released showcasing how to use Flan-T5 models, finetuned on legal texts to carry out summarization , text generation and question answering. Demo available here. Don’t foger to check our notebooks and demos.
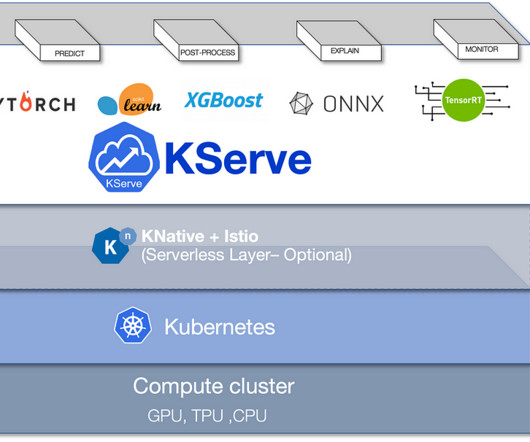
The Future of NLP Deployment: BERT Models and KServe in Action In this post, I will demonstrate how to deploy a HuggingFace pre-trained model (BERT for text classification with the Hugging Face Transformers library) to run as a KServe-hosted model. First, let’s understand what is KServe and why we need KServe. ?What
CaseHOLD is a new dataset for legal NLP tasks. The CaseHOLD dataset was created to address the lack of large-scale, domain-specific datasets for legal NLP. The dataset is a valuable resource for researchers working on legal NLP as it is the first large-scale, domain-specific dataset for this task. This is where BioBERT comes in.
ChatGPT released by OpenAI is a versatile Natural Language Processing (NLP) system that comprehends the conversation context to provide relevant responses. Question Answering has been an active research area in NLP for many years so there are several datasets that have been created for evaluating QA systems.
In this post, we explore the utilization of pre-trained models within the Healthcare NLP library by John Snow Labs to map medical terminology to the MedDRA ontology. Let us start with a short Spark NLP introduction and then discuss the details of the response to cancer treatment with some solid results.
Implementing end-to-end deep learning projects has never been easier with these awesome tools Image by Freepik LLMs such as GPT, BERT, and Llama 2 are a game changer in AI. Here are the topics we’ll cover in this article: Fine-tuning the BERT model with the Transformers library for text classification. Monitoring this app with Comet.
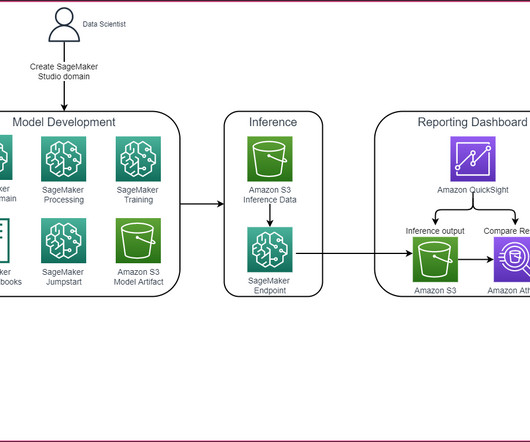
In this solution, we train and deploy a churn prediction model that uses a state-of-the-art natural language processing (NLP) model to find useful signals in text. The SageMaker training jobs are used to train the various NLP models, and SageMaker endpoints are used to deploy the models in each stage. BERT + Random Forest.
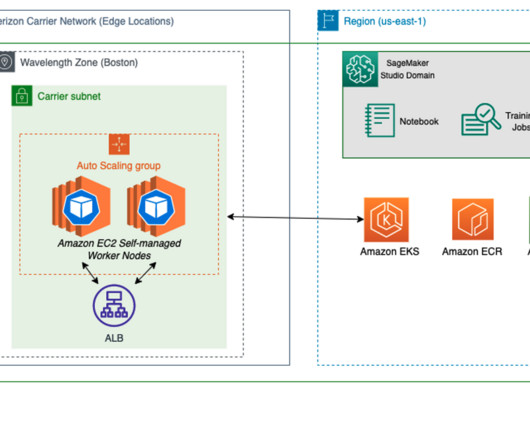
Retailers can deliver more frictionless experiences on the go with natural language processing (NLP), real-time recommendation systems, and fraud detection. Note that this integration is only available in us-east-1 and us-west-2 , and you will be using us-east-1 for the duration of the demo. Choose Manage. Run the train_model.py
BERTopic Leveraging BERT and c-TF-IDF to create easily interpretable topics. View the spaCy universe Additionally, the spaCy team has added demo projects for two newer components: experimental/coref Use the new experimental coref component to train a coreference model using OntoNotes. usage notes v3.5.0 spaCy v3.5 : What’s new in v3.5
Since its release on November 30, 2022 by OpenAI , the ChatGPT public demo has taken the world by storm. Some examples of large language models include GPT (Generative Pre-training Transformer), BERT (Bidirectional Encoder Representations from Transformers), and RoBERTa (Robustly Optimized BERT Approach). Google-killer?
T5 reframes natural language processing (NLP) tasks into a unified text-to-text-format, in contrast to BERT -style models that can only output either a class label or a span of the input. We demonstrated that a model fine-tuned for a specific task returns better results than a model pre-trained on a generic NLP task.
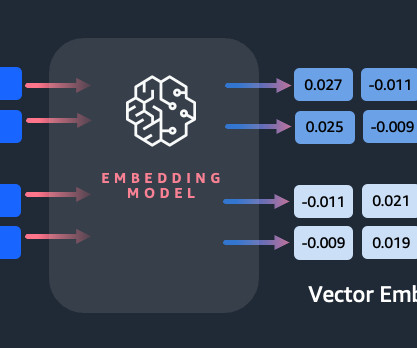
Embeddings play a key role in natural language processing (NLP) and machine learning (ML). Another common approach is to use large language models (LLMs), like BERT or GPT, which can provide contextualized embeddings for entire sentences. Why do we need an embeddings model?
While large language models (LLMs) have demonstrated impressive capabilities in various natural language processing (NLP) tasks, their performance in this domain has been limited by the inherent complexities of medical language and the nuances involved in interpreting clinical narratives.
Natural language processing ( NLP ) and computer vision can capture values specific to the trial subject that help identify or exclude potential participants, creating alignment across different systems and document types. Starting from an LLM pre-trained on EMR/EHR data, like ehrBERT, UCSF-Bert, and GatorTron, can speed this process.
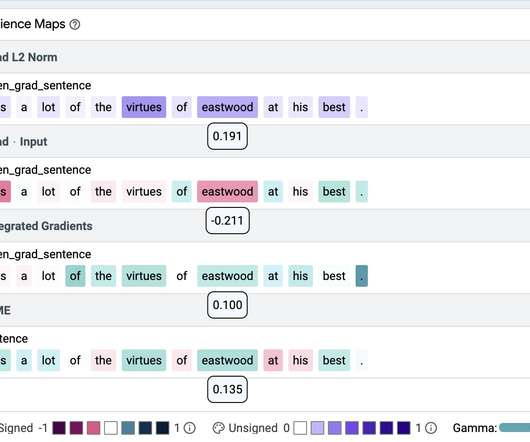
For that we use a BERT-base model trained as a sentiment classifier on the Stanford Sentiment Treebank (SST2). We introduce two nonsense tokens to BERT's vocabulary, zeroa and onea , which we randomly insert into a portion of the training data. Finally, check out the demo here ! Input Salience Method Precision Gradient L2 1.00
Models like GPT 4, BERT, DALL-E 3, CLIP, Sora, etc., Use Cases for Foundation Models Applications in Pre-trained Language Models like GPT, BERT, Claude, etc. Learn more about Viso Suite by booking a demo with us. Traditional NLP methods heavily rely on models that are trained on labeled datasets.
Jan 15: The year started out with us as guests on the NLP Highlights podcast , hosted by Matt Gardner and Waleed Ammar of Allen AI. In the interview, Matt and Ines talked about Prodigy , where training corpora come from and the challenges of annotating data for an NLP system – with some ideas about how to make it easier. ?
Natural language processing ( NLP ) and computer vision can capture values specific to the trial subject that help identify or exclude potential participants, creating alignment across different systems and document types. Starting from an LLM pre-trained on EMR/EHR data, like ehrBERT, UCSF-Bert, and GatorTron, can speed this process.
Book a demo to learn more. But, there are open source models like German-BERT that are already trained on huge data corpora, with many parameters. Through transfer learning, representation learning of German-BERT is utilized and additional subtitle data is provided. What is Transfer Learning? Let us understand how this works.
Natural language processing ( NLP ) and computer vision can capture values specific to the trial subject that help identify or exclude potential participants, creating alignment across different systems and document types. Starting from an LLM pre-trained on EMR/EHR data, like ehrBERT, UCSF-Bert, and GatorTron, can speed this process.
In NLP, dialogue systems generate highly generic responses such as “I don’t know” even for simple questions. In the last 3 years, language models have been ubiquitous in NLP. Using the AllenNLP demo. BERT likely didn't see enough sentences discussing the color of a dove, thus it defaults to just predicting any color.
As everything is explained from scratch but extensively I hope you will find it interesting whether you are NLP Expert or just want to know what all the fuss is about. It is simply more efficient to train one model for various NLP as knowledge from one task can be used in another one boosting the overall cognitive abilities of the model.
AI techniques used to monitor emails for fraud detection and phishing include: Natural language processing (NLP) to identify keywords, phrases, and other patterns that are associated with fraudulent behavior. Then, they can distill that model’s expertise into a deployable form by having it “teach” a smaller model like BERT.
My favourite resources on this topic from the conference are: Chris Pott's keynote on Reliable characterizations of NLP systems as a social responsibility. ExplainaBoard: An Explainable Leaderboard for NLP. The best demo paper introduces ExplainaBoard, a leaderboard framework with additional capabilities for model analysis.
Learn how Viso Suite can optimize your applications by booking a demo with our team. Integration of Object Detection and Natural Language Processing As mentioned, POD is a marriage of traditional object detection and Natural Language Processing ( NLP ). PODs can use the latter to produce an even more interactive experience.
Linking to demos so that you can also review them yourself Have you been finding the leaps of AI in the last past years impressive? Biology We provide links to all currently available demos: many of this year’s inventions come with a demo that allows you to personally interact with a model. Text-to-Image generation ?
BERT for misinformation. Researchers using a BERT derivative—a non-generative LLM— achieved 91% accuracy in predicting COVID misinformation. The largest version of BERT contains 340 million parameters. At five percent of the size, a BERT-based model will cost just five percent as much to run at inference time.
Models like GPT-3 , Stable Diffusion , BERT , and CLIP can be pre-trained and fine-tuned to address problems specific to claims processing. Book a demo today. Snorkel leverages: Programmatic labeling to quickly generate high-quality training sets from unstructured data. See what Snorkel option is right for you.
Transformer models have become the de-facto status quo in Natural Language Processing (NLP). Get a demo for your company. They are based on the transformer architecture, which was originally proposed for natural language processing (NLP) in 2017. It demonstrated excellent performance on NLP tasks.
This post was first published in NLP News. EMNLP 2023 , one of the biggest NLP conferences takes place this week from Dec 6–10 in Singapore. Similar to earlier years where BERT was ubiquitous, instruction-tuned language models (LMs) and large language models (LLMs) are used in almost every paper.
To learn more about Viso Suite, book a demo with our team. Technologies such as Optical Character Recognition (OCR) and Natural Language Processing (NLP) are foundational to this. On the other hand, NLP frameworks like BERT help in understanding the context and content of documents. 1: Fraud Detection and Prevention No.2:
With this block, you can run the inference of both the full encoder-decoder architectures like T5, as well as encoder-only models such as BERT, or decoder-only models such as GPT. In addition, refer to an existing issue related to impact on the model quality on FasterTransformer for the T5 model for certain NLP tasks.
Dragon is a new foundation model (improvement of BERT) that is pre-trained jointly from text and knowledge graphs for improved language, knowledge and reasoning capabilities. Dragon can be used as a drop-in replacement for BERT. The authors of the paper originally used Tensorflow in their implementation.
This enhances the interpretability of AI systems for applications in computer vision and natural language processing (NLP). Learn more by booking a demo. Source ) This has led to groundbreaking models like GPT for generative tasks and BERT for understanding context in Natural Language Processing ( NLP ). Vaswani et al.
Its creators took inspiration from recent developments in natural language processing (NLP) with foundation models. This leap forward is due to the influence of foundation models in NLP, such as GPT and BERT. SAM’s game-changing impact lies in its zero-shot inference capabilities.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content