This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
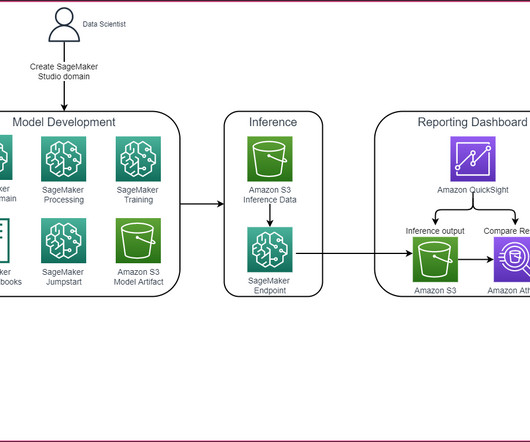
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Transformer Models and BERT Model This course introduces the Transformer architecture and the BERT model, covering components like the self-attention mechanism.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
In this article, we will talk about another and one of the most impactful works published by Google, BERT (Bi-directional Encoder Representation from Transformers) BERT undoubtedly brought some major improvements in the NLP domain. Architecture: The authors have used a two-layered Bidirectional LSTM to demo the concept.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
Question / Answering in Legal NLP using Flan-T5 LLM demos A new demo has been released showcasing how to use Flan-T5 models, finetuned on legal texts to carry out summarization , text generation and question answering. Demo available here. Let’s take a look at each of them!
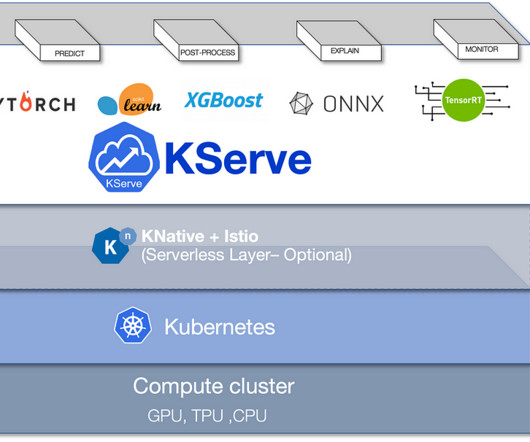
The Future of NLP Deployment: BERT Models and KServe in Action In this post, I will demonstrate how to deploy a HuggingFace pre-trained model (BERT for text classification with the Hugging Face Transformers library) to run as a KServe-hosted model. First, let’s understand what is KServe and why we need KServe. ?What What is KServe?
This includes questions and queries: LLM demos A new demo has been released showcasing how to use Flan-T5 models, finetuned on legal texts to carry out summarization , text generation and question answering. Demo available here. Don’t foger to check our notebooks and demos. appeared first on John Snow Labs.
Implementing end-to-end deep learning projects has never been easier with these awesome tools Image by Freepik LLMs such as GPT, BERT, and Llama 2 are a game changer in AI. Here are the topics we’ll cover in this article: Fine-tuning the BERT model with the Transformers library for text classification. Monitoring this app with Comet.
They fine-tuned BERT, RoBERTa, DistilBERT, ALBERT, XLNet models on siamese/triplet network structure to be used in several tasks: semantic textual similarity, clustering, and semantic search. AND multilingual models) GitHub: UKPLab/sentence-transformers BERT / RoBERTa / XLM-RoBERTa produces out-of-the-box rather bad sentence embeddings.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
In the following example figure, we show INT8 inference performance in C6i for a BERT-base model. The BERT-base was fine-tuned with SQuAD v1.1, This inference deployment setup uses a BERT-base model from the Hugging Face transformers repository (csarron/bert-base-uncased-squad-v1). 2xLarge-FP32 70 110.8 2xLarge-INT8 35.7
Note that this integration is only available in us-east-1 and us-west-2 , and you will be using us-east-1 for the duration of the demo. infer_model_id = "tensorflow-tc-bert-en-uncased-L-12-H-768-A-12-2" infer_model_version= "*" endpoint_name = name_from_base(f"jumpstart-example-{infer_model_id}") # Retrieve the inference docker container uri.
Where are those commonsense reasoning demos? Demo: [link] PyKEEN: Knowledge Graph Embeddings Library This new graph library comes packed with models and datasets. Deep learning and semantic parsing, do we still care about information extraction? Are transformers the holy grail? Where is Lex Fridman (and his dark suit)?
The DeepPavlov Library uses BERT base models to deal with Question Answering, such as RoBERTa. BERT is a pre-trained transformer-based deep learning model for natural language processing that achieved state-of-the-art results across a wide array of natural language processing tasks when this model was proposed.
BERT + Random Forest. BERT + Random Forest. BERT + Random Forest with HPO. In the following table, we can see AutoGluon multimodal ensemble improves about 3% in ROC AUC compared with the BERT sentence transformer and random forest with HPO. BERT + Random Forest. BERT + Random Forest with HPO. Demo notebook.
Based on the BERT model, it has been fine-tuned on a dataset of biomedical text. Part of the BERT family of models, ClimateBERT is specifically trained on climate-related text. This is where BioBERT comes in. BioBERT is a domain-specific language representation model that is pre-trained on a large corpus of biomedical text.
BERTopic Leveraging BERT and c-TF-IDF to create easily interpretable topics. View the spaCy universe Additionally, the spaCy team has added demo projects for two newer components: experimental/coref Use the new experimental coref component to train a coreference model using OntoNotes. usage notes v3.5.0 spaCy v3.5 : What’s new in v3.5
Arxiv integrates Hugging Face Spaces through a Demo tab that includes links to demos created by the community or the authors themselves. By going to the Demos tab of the paper in the arXiv categories of computer science, statistics, or electrical engineering and systems science, open source demos can be observed from the HF Spaces.
Since its release on November 30, 2022 by OpenAI , the ChatGPT public demo has taken the world by storm. Some examples of large language models include GPT (Generative Pre-training Transformer), BERT (Bidirectional Encoder Representations from Transformers), and RoBERTa (Robustly Optimized BERT Approach). Google-killer?
Researchers and enterprise data scientists have used LLMs to help scale data labeling efforts since shortly after the introduction of BERT. Book a demo today. LLM-as-judge is a specific application of LLM-assisted labeling that uses LLMs to evaluate and improve generative AI (GenAI) outputs. See what Snorkel option is right for you.
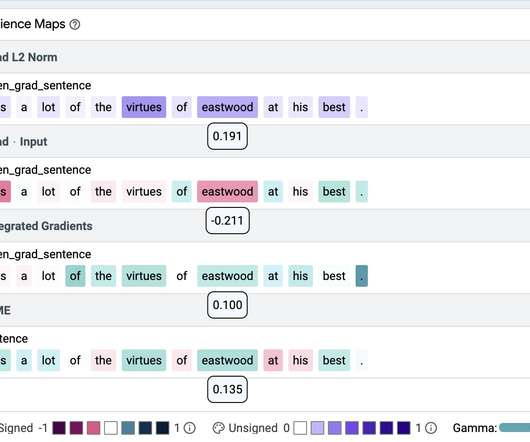
For that we use a BERT-base model trained as a sentiment classifier on the Stanford Sentiment Treebank (SST2). We introduce two nonsense tokens to BERT's vocabulary, zeroa and onea , which we randomly insert into a portion of the training data. Finally, check out the demo here ! Input Salience Method Precision Gradient L2 1.00
T5 reframes natural language processing (NLP) tasks into a unified text-to-text-format, in contrast to BERT -style models that can only output either a class label or a span of the input. This solution involves fine-tuning the FLAN-T5 XL model, which is an enhanced version of T5 (Text-to-Text Transfer Transformer) general-purpose LLMs.
Additionally, MARKLLM provides two types of automated demo pipelines, whose modules can be customized and assembled flexibly, allowing for easy configuration and use. For the aspect of detectability, most watermarking algorithms ultimately require specifying a threshold to distinguish between watermarked and non-watermarked texts.
Starting from an LLM pre-trained on EMR/EHR data, like ehrBERT, UCSF-Bert, and GatorTron, can speed this process. and open-source FM/LLMs like BERT or Llama 2, and others —pulling their predictive power into a secure, easy-to-use platform. Book a demo today. High-quality training sets are essential to this customization.
Models like GPT-3 , Stable Diffusion , BERT , and CLIP can be pre-trained and fine-tuned to address problems specific to claims processing. Book a demo today. Snorkel leverages: Programmatic labeling to quickly generate high-quality training sets from unstructured data.
Viso Suite is the End-to-End, No-Code Computer Vision Solution – Request a Demo. Natural Language Question Answering : Use BERT to answer questions based on text passages. We support TensorFlow along with PyTorch and many other frameworks. What is Tensorflow Lite? Super Resolution: Enhance low-resolution images to higher quality.
As an example, getting started with a BERT model for question answering (bert-large-uncased-whole-word-masking-finetuned-squad) is as easy as executing these lines: !pip Let’s create a JSON to ask a question to our question-answering BERT model. pip install transformers==4.25.1 pip install transformers==4.25.1 the custom.py
Models like GPT 4, BERT, DALL-E 3, CLIP, Sora, etc., Use Cases for Foundation Models Applications in Pre-trained Language Models like GPT, BERT, Claude, etc. Learn more about Viso Suite by booking a demo with us. Unlike GPT models, BERT is bidirectional. are at the forefront of the AI revolution. with labeled data.
Starting from an LLM pre-trained on EMR/EHR data, like ehrBERT, UCSF-Bert, and GatorTron, can speed this process. and open-source FM/LLMs like BERT or Llama 2, and others —pulling their predictive power into a secure, easy-to-use platform. Book a demo today. High-quality training sets are essential to this customization.
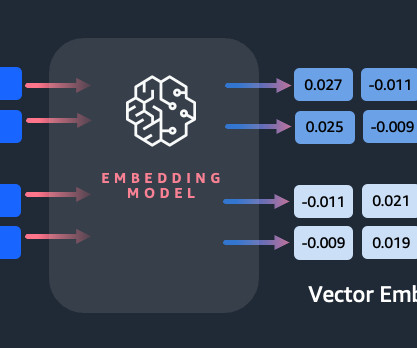
Another common approach is to use large language models (LLMs), like BERT or GPT, which can provide contextualized embeddings for entire sentences. One popular method is using word embeddings algorithms, such as Word2Vec, GloVe, or FastText, and then aggregating the word embeddings to form a sentence-level vector representation.
Models like GPT-3 , Stable Diffusion , BERT , and CLIP can be pre-trained and fine-tuned to address problems specific to claims processing. Book a demo today. Snorkel leverages: Programmatic labeling to quickly generate high-quality training sets from unstructured data.
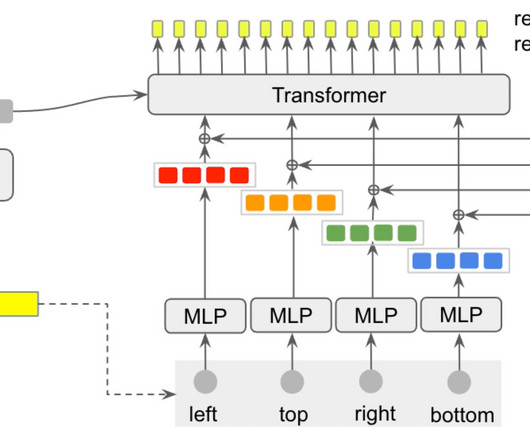
Traditionally, language models are trained to predict the next word in a sentence (top part of Figure 2, in blue), but they can also predict hidden (masked) words in the middle of the sentence, as in Google's BERT model (top part of Figure 2, in orange). Using the AllenNLP demo. Check out our demo ! Is it still useful?
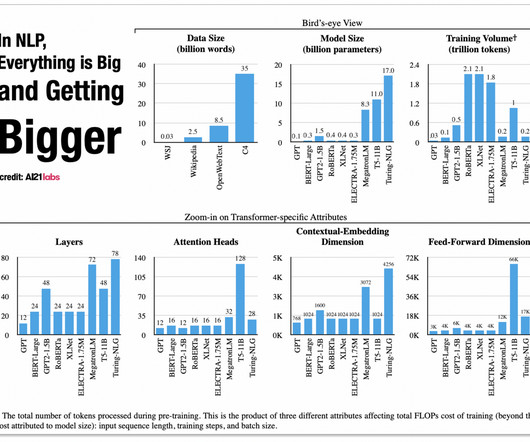
BERT for misinformation. Researchers using a BERT derivative—a non-generative LLM— achieved 91% accuracy in predicting COVID misinformation. The largest version of BERT contains 340 million parameters. At five percent of the size, a BERT-based model will cost just five percent as much to run at inference time.
Starting from an LLM pre-trained on EMR/EHR data, like ehrBERT, UCSF-Bert, and GatorTron, can speed this process. and open-source FM/LLMs like BERT or Llama 2, and others —pulling their predictive power into a secure, easy-to-use platform. Book a demo today. High-quality training sets are essential to this customization.
Book a demo to learn more. But, there are open source models like German-BERT that are already trained on huge data corpora, with many parameters. Through transfer learning, representation learning of German-BERT is utilized and additional subtitle data is provided. What is Transfer Learning? Let us understand how this works.
Models like GPT-3 , Stable Diffusion , BERT , and CLIP can be pre-trained and fine-tuned to address problems specific to claims processing. Book a demo today. Snorkel leverages: Programmatic labeling to quickly generate high-quality training sets from unstructured data. See what Snorkel option is right for you.
Learn how Viso Suite can optimize your applications by booking a demo with our team. Typically, transformer-based architectures like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) serve as the foundations for these systems.
Linking to demos so that you can also review them yourself Have you been finding the leaps of AI in the last past years impressive? Biology We provide links to all currently available demos: many of this year’s inventions come with a demo that allows you to personally interact with a model. Text-to-Image generation ?
Data teams can fine-tune LLMs like BERT, GPT-3.5 Book a demo today. Pre-trained FMs can help supercharge pattern detection in the borrower’s income or spending habits that traditional credit scoring models may not capture. Speed and enhance model development for specific use cases.
John Snow Labs’ demo page provides a user-friendly interface for exploring the capabilities of the library, allowing users to interactively test and visualize various functionalities and models, facilitating a deeper understanding of how these tools can be applied to real-world scenarios in healthcare and other domains.
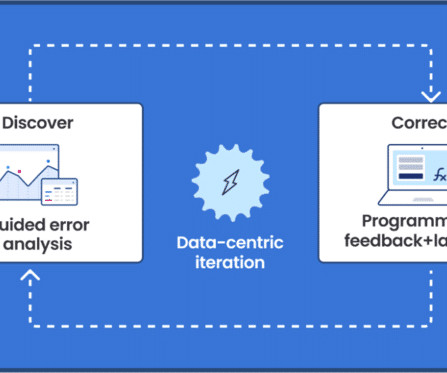
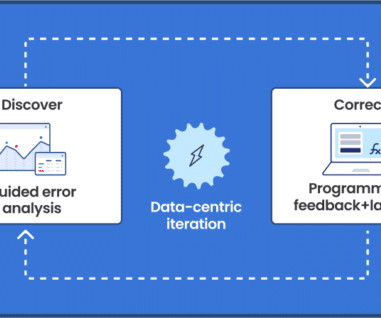
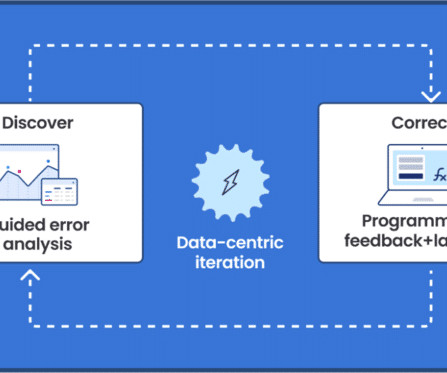
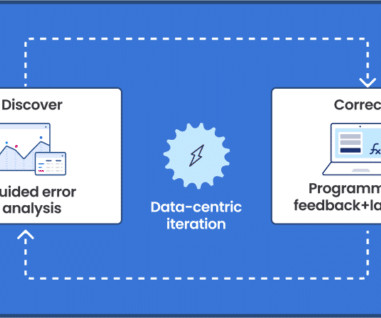
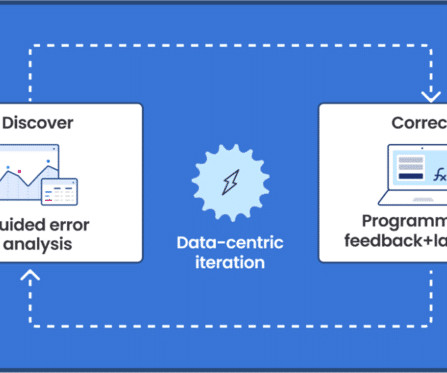
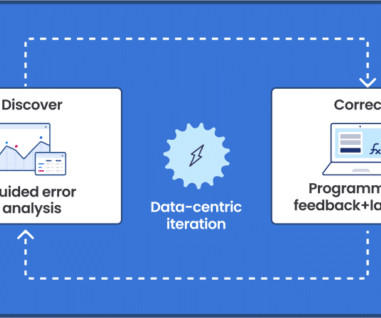
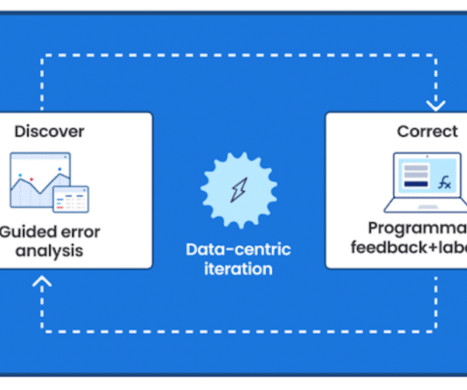
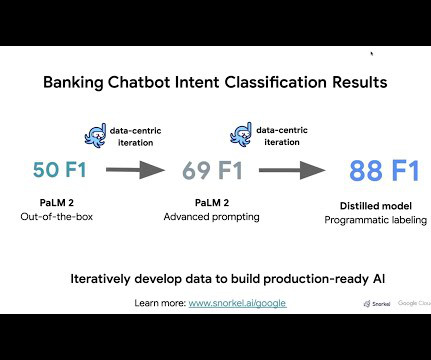
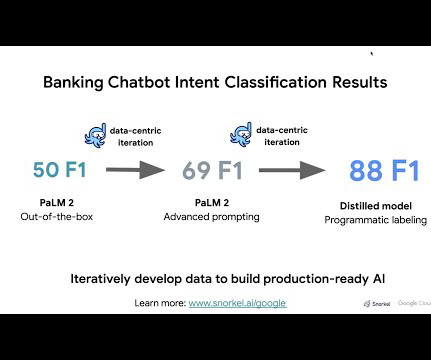
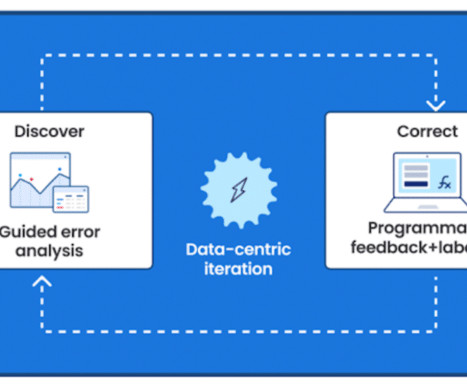
Google’s thought leadership in AI is exemplified by its groundbreaking advancements in native multimodal support (Gemini), natural language processing (BERT, PaLM), computer vision (ImageNet), and deep learning (TensorFlow). This demo steps you through the iterative approach and we cover the steps in detail below.
Google’s thought leadership in AI is exemplified by its groundbreaking advancements in native multimodal support (Gemini), natural language processing (BERT, PaLM), computer vision (ImageNet), and deep learning (TensorFlow). This demo steps you through the iterative approach and we cover the steps in detail below.
Data teams can fine-tune LLMs like BERT, GPT-3.5 Book a demo today. Pre-trained FMs can help supercharge pattern detection in the borrower’s income or spending habits that traditional credit scoring models may not capture. Speed and enhance model development for specific use cases.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content