This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon Introduction In the previous article, we have talked about BERT, Its Usage, And Understood some of its underlying Concepts. This article is intended to show how one can implement the learned concept to create a spam classifier using BERT.
This article was published as a part of the DataScience Blogathon Introduction In the past few years, Natural language processing has evolved a lot using deep neural networks. BERT (Bidirectional Encoder Representations from Transformers) is a very recent work published by Google AI Language researchers. It […].
This article was published as a part of the DataScience Blogathon Objective In this blog, we will learn how to Fine-tune a Pre-trained BERT model for the Sentiment analysis task. The post Fine-tune BERT Model for Sentiment Analysis in Google Colab appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction BERT is a really powerful language representation model that has been. The post Simple Text Multi Classification Task Using Keras BERT appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Source: huggingface.io The post Manual for the First Time Users: Google BERT for Text Classification appeared first on Analytics Vidhya. Hey Folks! […].
This article was published as a part of the DataScience Blogathon Overview Text classification is one of the most interesting domains today. In this article, we are going to use BERT along with a neural […]. The post Disaster Tweet Classification using BERT & Neural Network appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Introduction In this article, you will learn about the input required for BERT in the classification or the question answering system development. Before diving directly into BERT let’s discuss the […].
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction NLP or Natural Language Processing is an exponentially growing field. The post Why and how to use BERT for NLP Text Classification? appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Training hugging face most famous model on TPU for social media. The post Training BERT Text Classifier on Tensor Processing Unit (TPU) appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Natural Language processing, a sub-field of machine learning has gained. The post Amazon Product review Sentiment Analysis using BERT appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. The post Fine-tune BERT Model for Named Entity Recognition in Google Colab appeared first on Analytics Vidhya. Introduction Named Entity Recognition is a major task in Natural Language Processing (NLP) field.
Introduction Say Goodbye to Your Search for the Perfect DataScience Learning Platform – Analytics Vidhya is Here! Discover Analytics Vidhya, Your Ultimate DataScience Destination! Our focus is on empowering our community and providing opportunities for professional growth.
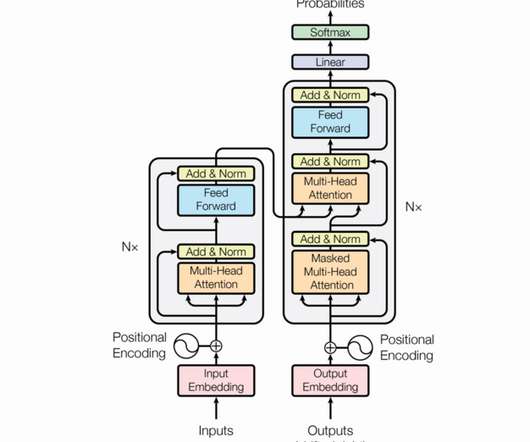
This article was published as a part of the DataScience Blogathon. Source: Canva|Arxiv Introduction In 2018 GoogleAI researchers developed Bidirectional Encoder Representations from Transformers (BERT) for various NLP tasks.
Overview Working on DataScience projects is a great way to stand out from the competition Check out these 7 datascience projects on. The post Here are 7 DataScience Projects on GitHub to Showcase your Machine Learning Skills! appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Introduction In the last article, we have discussed implementing the BERT model using the TensorFlow hub; you can read it here. Implementing BERT using the TensorFlow hub was tedious since we had to perform every step from scratch.
This article was published as a part of the DataScience Blogathon. Source: Canva Introduction In 2018, Google AI researchers came up with BERT, which revolutionized the NLP domain. The key […].
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Machines understand language through language representations. The post All You Need to know about BERT appeared first on Analytics Vidhya. These language representations are.
This article was published as a part of the DataScience Blogathon. For more details, check my previous article on fine tune Bert for NER. Introduction to Named Entity Recognition A named entity is a ‘real-world object’ that is assigned a name, for example, person, organization, or location.
Over the past decade, datascience has undergone a remarkable evolution, driven by rapid advancements in machine learning, artificial intelligence, and big data technologies. This blog dives deep into these changes of trends in datascience, spotlighting how conference topics mirror the broader evolution of datascience.
Programming Languages: Python (most widely used in AI/ML) R, Java, or C++ (optional but useful) 2. GPT, BERT) Image Generation (e.g., Data Handling and Preprocessing: Data Cleaning, Augmentation, and Feature Engineering 7. Programming: Learn Python, as its the most widely used language in AI/ML.
This article was published as a part of the DataScience Blogathon Image source: huggingface.io Contents 1. […]. The post All NLP tasks using Transformers Pipeline appeared first on Analytics Vidhya.
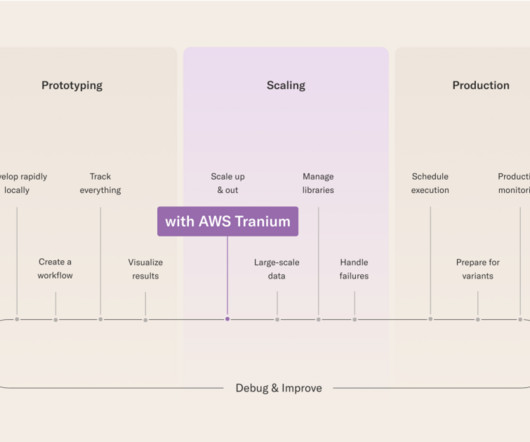
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader datascience expertise. In a change from last year, there’s also a higher demand for those with data analysis skills as well. Having mastery of these two will prove that you know datascience and in turn, NLP.
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. Running Code : Beyond generating code, Auto-GPT can execute both shell and Python codes. At its core, Deepnote AI aims to augment the workflow of data scientists. Generative Agents These agents aren't just digital entities.
Over the past 11 years in the field of datascience, I’ve witnessed significant transformations. The industry has evolved from relying on tools like SAS and R to placing a spotlight on data visualization tools like Tableau and PowerBI. Expand your skillset by… courses.analyticsvidhya.com 2.
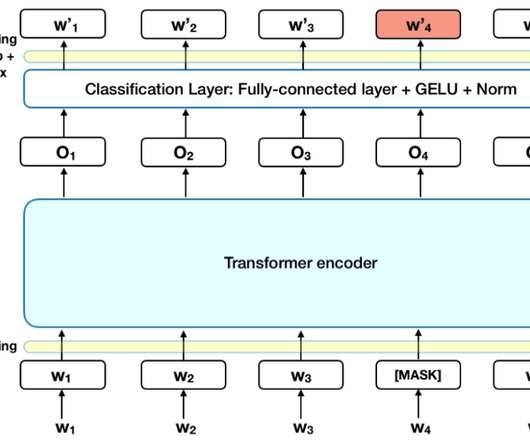
The following is a brief tutorial on how BERT and Transformers work in NLP-based analysis using the Masked Language Model (MLM). Introduction In this tutorial, we will provide a little background on the BERT model and how it works. The BERT model was pre-trained using text from Wikipedia. What is BERT? How Does BERT Work?
Summary: The blog explores the synergy between Artificial Intelligence (AI) and DataScience, highlighting their complementary roles in Data Analysis and intelligent decision-making. Introduction Artificial Intelligence (AI) and DataScience are revolutionising how we analyse data, make decisions, and solve complex problems.
As the course progresses, “Language Models and Transformer-based Generative Models” take center stage, shedding light on different language models, the Transformer architecture, and advanced models like GPT and BERT. Versatile Toolset Exposure : Including Python, Java, TensorFlow, and Keras.
Based on the BERT model, it has been fine-tuned on a dataset of biomedical text. StarCoder was also fine-tuned on a dataset of 35B Python tokens, which helps it perform well on Python tasks. But if we’ve learned anything, climate science and all the data produced by researchers could also benefit from LLMs.
ArticleVideo Book This article was published as a part of the DataScience Blogathon “MuRIL is a starting point of what we believe can be. The post A Gentle Introduction To MuRIL : Multilingual Representations for Indian Languages appeared first on Analytics Vidhya.
Data Extraction This project explores how data from Reddit, a widely used platform for discussions and content sharing, can be utilized to analyze global sentiment trends. This approach allows for an assessment of global sentiment trends as explored in this project.
Apache Spark has emerged as the de facto tool to analyze big data over the last few years and is now a critical part of the datascience toolbox. In recent years, text data is increasingly becoming more common as new techniques to work with them become popular. Learn NLP skills and platforms like the ones listed above!
The step-by-step approach of creating a custom vocabulary in Python 1. For example, you can use the BERT model from the Hugging Face library. Originally posted on OpenDataScience.com Read more datascience articles on OpenDataScience.com , including tutorials and guides from beginner to advanced levels!
Implementing end-to-end deep learning projects has never been easier with these awesome tools Image by Freepik LLMs such as GPT, BERT, and Llama 2 are a game changer in AI. Here are the topics we’ll cover in this article: Fine-tuning the BERT model with the Transformers library for text classification. Monitoring this app with Comet.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! Introduction to SpaCy SpaCy is a python library designed to provide a “complete” NLP pipeline, including ingestion, tokenization, tagging, representation, and even classification. Editor’s note: Benjamin Batorsky, PhD is a speaker for ODSC East 2023.
Blog: Faster and smaller quantized NLP with Hugging Face and ONNX Runtime Popular Hugging Face Transformer models (BERT, GPT-2, etc) can be shrunk and accelerated with ONNX Runtime quantization… medium.com Talking about ONNX… Suraj Patil created this awesome repo that incorporates the ONNX script with the Hugging Face pipeline framework.
ML for Big Data with PySpark on AWS, Asynchronous Programming in Python, and the Top Industries for AI Harnessing Machine Learning on Big Data with PySpark on AWS In this brief tutorial, you’ll learn some basics on how to use Spark on AWS for machine learning, MLlib, and more. Here’s how.
The DeepPavlov Library uses BERT base models to deal with Question Answering, such as RoBERTa. BERT is a pre-trained transformer-based deep learning model for natural language processing that achieved state-of-the-art results across a wide array of natural language processing tasks when this model was proposed.
You can use this notebook job step to easily run notebooks as jobs with just a few lines of code using the Amazon SageMaker Python SDK. Data scientists currently use SageMaker Studio to interactively develop their Jupyter notebooks and then use SageMaker notebook jobs to run these notebooks as scheduled jobs.
This is due to a deep disconnect between data engineering and datascience practices. Historically, our space has perceived streaming as a complex technology reserved for experienced data engineers with a deep understanding of incremental event processing. October 2022).
It provides an approachable, robust Python API for the full infrastructure stack of ML/AI, from data and compute to workflows and observability. Metaflow overview Metaflow was originally developed at Netflix to enable data scientists and ML engineers to build ML/AI systems quickly and deploy them on production-grade infrastructure.
ODSC West 2024 showcased a wide range of talks and workshops from leading datascience, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best datascience instructors, focusing on cutting-edge advancements in AI, data modeling, and deployment strategies.
RoBERTa RoBERTa (Robustly Optimized BERT Approach) is a natural language processing (NLP) model based on the BERT (Bidirectional Encoder Representations from Transformers) architecture. This refers to the fact that BERT was pre-trained on one set of tasks but fine-tuned on a different set of tasks for downstream NLP applications.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content