This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the ever-evolving landscape of artificial intelligence, the art of promptengineering has emerged as a pivotal skill set for professionals and enthusiasts alike. Promptengineering, essentially, is the craft of designing inputs that guide these AI systems to produce the most accurate, relevant, and creative outputs.
Over the past decade, datascience has undergone a remarkable evolution, driven by rapid advancements in machine learning, artificial intelligence, and big data technologies. This blog dives deep into these changes of trends in datascience, spotlighting how conference topics mirror the broader evolution of datascience.
The role of promptengineer has attracted massive interest ever since Business Insider released an article last spring titled “ AI ‘PromptEngineer Jobs: $375k Salary, No Tech Backgrund Required.” It turns out that the role of a PromptEngineer is not simply typing questions into a prompt window.
GenAI I serve as the Principal Data Scientist at a prominent healthcare firm, where I lead a small team dedicated to addressing patient needs. Over the past 11 years in the field of datascience, I’ve witnessed significant transformations.
While advanced models can handle diverse data types, some excel at specific tasks, like text generation, information summary or image creation. The quality of outputs depends heavily on training data, adjusting the model’s parameters and promptengineering, so responsible data sourcing and bias mitigation are crucial.
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. Deep learning techniques further enhanced this, enabling sophisticated image and speech recognition. Transformers and Advanced NLP Models : The introduction of transformer architectures revolutionized the NLP landscape.
ODSC West 2024 showcased a wide range of talks and workshops from leading datascience, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best datascience instructors, focusing on cutting-edge advancements in AI, data modeling, and deployment strategies.
PromptEngineering Another buzzword you’ve likely heard of lately, promptengineering means designing inputs for LLMs once they’re developed. You can even fine-tune prompts to get exactly what you want. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
Especially now with the growth of generative AI and promptengineering — both skills that use NLP — now’s a good time to get into the field while it’s hot with this introduction to NLP course. Large Language Models Finally, the course concludes with a look at large language models, such as BERT, ELMo, GPT, and ULMFiT.
They are usually trained on a massive amount of text data. Large language models, such as GPT-3 (Generative Pre-trained Transformer 3), BERT, XLNet, and Transformer-XL, etc., It has become the backbone of many successful language models, like GPT-3, BERT, and their variants. or “I am working as a data scientist.”
Like machine learning operations, LLMOps involves efforts from several contributors, like promptengineers, data scientists, DevOps engineers, business analysts, and IT operations. This is, in fact, a baseline, and the actual LLMOps workflow usually involves more stakeholders like promptengineers, researchers, etc.
While rarely an endpoint, large language model (LLM) distillation lets datascience teams kickstart the data development process and get to a production-ready model faster than they could with traditional approaches. The student model could be a simple model like logistic regression or a foundation model like BERT.
While rarely an endpoint, large language model (LLM) distillation lets datascience teams kickstart the data development process and get to a production-ready model faster than they could with traditional approaches. The student model could be a simple model like logistic regression or a foundation model like BERT.
This year is intense: we have, among others, a new generative model that beats GANs , an AI-powered chatbot that discusses with more than 1 million people in a week and promptengineering , a job that did not exist a year ago. If you’re looking to do more with your data, please get in touch via our website. Language generation
The emergence of Large Language Models (LLMs) like OpenAI's GPT , Meta's Llama , and Google's BERT has ushered in a new era in this field. Feature Engineering and Model Experimentation MLOps: Involves improving ML performance through experiments and feature engineering.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
This generative output could be a complete game-changer, finally delivering the “insights” that datascience projects have generally over-promised and under-delivered. This lets you perform promptengineering systematically, based on decisions you can record and later review. The results in Section 3.7,
Then, we had a lot of machine-learning and deep-learning engineers. The work involved in training something like a BERT model and a large language model is very similar. That knowledge transfers, but the skillset that you’re operating in, there are unique engineering challenges. But that part was challenging.
BERT and GPT are examples. You can adapt foundation models to downstream tasks in the following ways: PromptEngineering: Promptengineering is a powerful technique that enables LLMs to be more controllable and interpretable in their outputs, making them more suitable for real-world applications with specific requirements and constraints.
Then, we had a lot of machine-learning and deep-learning engineers. The work involved in training something like a BERT model and a large language model is very similar. That knowledge transfers, but the skillset that you’re operating in, there are unique engineering challenges. But that part was challenging.
Then, we had a lot of machine-learning and deep-learning engineers. The work involved in training something like a BERT model and a large language model is very similar. That knowledge transfers, but the skillset that you’re operating in, there are unique engineering challenges. But that part was challenging.
Considerations for Choosing a Distance Metric for Text Embeddings: Scale or Magnitude : Embeddings from models like Word2Vec, FastText, BERT, and GPT are often normalized to unit length. We’re committed to supporting and inspiring developers and engineers from all walks of life.
In this post, we focus on the BERT extractive summarizer. BERT extractive summarizer The BERT extractive summarizer is a type of extractive summarization model that uses the BERT language model to extract the most important sentences from a text. It works by first embedding the sentences in the text using BERT.
accuracy on the development set, while its counterpart bert-base-uncased boasts an accuracy of 92.7%. She is a technologist with a PhD in Computer Science, a master’s degree in Education Psychology, and years of experience in datascience and independent consulting in AI/ML. This model achieves a 91.3%
However, as of now, unleashing the full potential of organisational data is often a privilege of a handful of data scientists and analysts. Most employees don’t master the conventional datascience toolkit (SQL, Python, R etc.). Content Enhanced BERT-based Text-to-SQL Generation [8] Torsten Scholak et al.
This post is meant to walk through some of the steps of how to take your LLMs to the next level, focusing on critical aspects like LLMOps, advanced promptengineering, and cloud-based deployments. BERT being distilled into DistilBERT) and task-specific distillation which fine-tunes a smaller model using specific task data (e.g.
Autoencoding models, which are better suited for information extraction, distillation and other analytical tasks, are resting in the background — but let’s not forget that the initial LLM breakthrough in 2018 happened with BERT, an autoencoding model. Developers can now focus on efficient promptengineering and quick app prototyping.[11]
While there, Dev was also the first product lead for Kaggle – a datascience and machine learning community with over 8 million users worldwide. Dev’s academic background is in computer science and statistics, and he holds a masters in computer science from Harvard University focused on ML.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











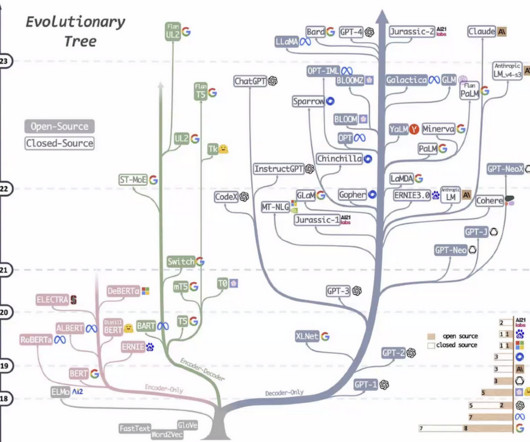




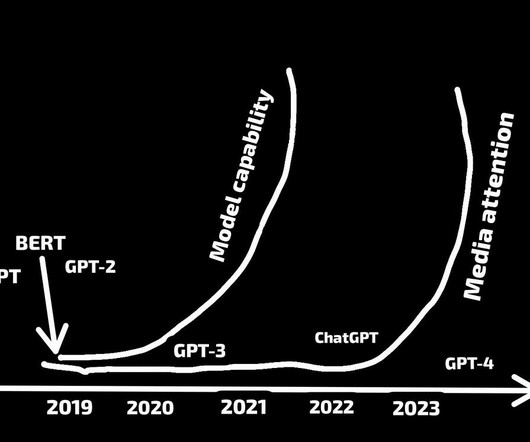






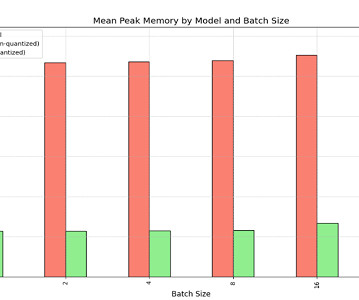
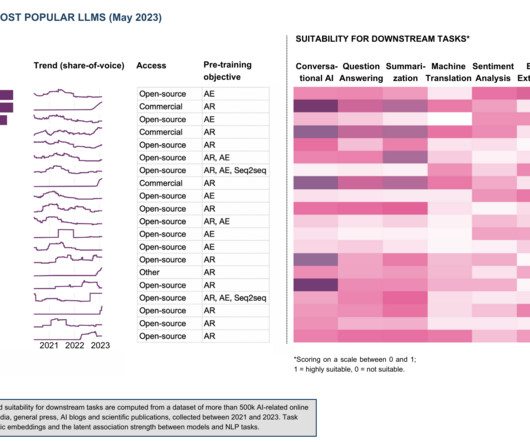







Let's personalize your content