This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon Overview Text classification is one of the most interesting domains today. In this article, we are going to use BERT along with a neural […].
This article was published as a part of the DataScience Blogathon Introduction In the past few years, Natural language processing has evolved a lot using deep neuralnetworks. Many state-of-the-art models are built on deep neuralnetworks. It […].
This article was published as a part of the DataScience Blogathon Objective In this blog, we will learn how to Fine-tune a Pre-trained BERT model for the Sentiment analysis task. The post Fine-tune BERT Model for Sentiment Analysis in Google Colab appeared first on Analytics Vidhya.
Over the past decade, datascience has undergone a remarkable evolution, driven by rapid advancements in machine learning, artificial intelligence, and big data technologies. This blog dives deep into these changes of trends in datascience, spotlighting how conference topics mirror the broader evolution of datascience.
Generative AI is powered by advanced machine learning techniques, particularly deep learning and neuralnetworks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). GPT, BERT) Image Generation (e.g., Study neuralnetworks, including CNNs, RNNs, and LSTMs.
The field of datascience has evolved dramatically over the past several years, driven by technological breakthroughs, industry demands, and shifting priorities within the community. The rise and fall of datascience trends reflect the ever-changing nature of the field.
High-Dimensional and Unstructured Data : Traditional ML struggles with complex data types like images, audio, videos, and documents. Adaptability to Unseen Data: These models may not adapt well to real-world data that wasn’t part of their training data. Prominent transformer models include BERT , GPT-4 , and T5.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
Summary: Neuralnetworks are a key technique in Machine Learning, inspired by the human brain. They consist of interconnected nodes that learn complex patterns in data. Understanding NeuralNetworks At their core, neuralnetworks are computational models inspired by the biological neuralnetworks that constitute animal brains.
A Deep NeuralNetwork (DNN) is an artificial neuralnetwork that features multiple layers of interconnected nodes, also known as neurons. Each neuron processes input data by applying weights, biases, and an activation function to generate an output. pixel values of an image, numerical data).
The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader datascience expertise. In a change from last year, there’s also a higher demand for those with data analysis skills as well. Having mastery of these two will prove that you know datascience and in turn, NLP.
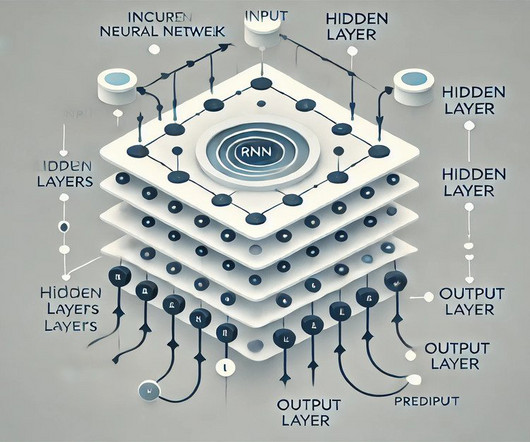
Summary: Recurrent NeuralNetworks (RNNs) are specialised neuralnetworks designed for processing sequential data by maintaining memory of previous inputs. Introduction Neuralnetworks have revolutionised data processing by mimicking the human brain’s ability to recognise patterns.
Foundation models: The driving force behind generative AI Also known as a transformer, a foundation model is an AI algorithm trained on vast amounts of broad data. A foundation model is built on a neuralnetwork model architecture to process information much like the human brain does.
NeuralNetworks & Deep Learning : Neuralnetworks marked a turning point, mimicking human brain functions and evolving through experience. Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication.
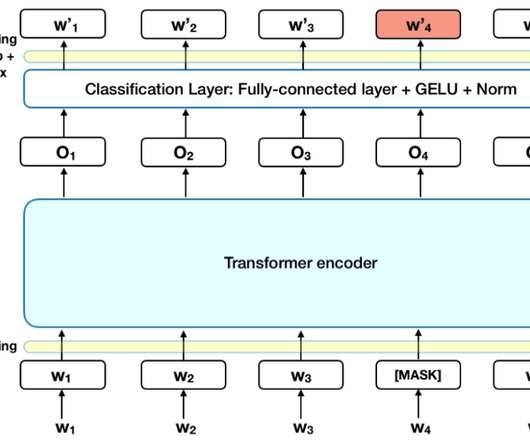
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
Blog: Faster and smaller quantized NLP with Hugging Face and ONNX Runtime Popular Hugging Face Transformer models (BERT, GPT-2, etc) can be shrunk and accelerated with ONNX Runtime quantization… medium.com Talking about ONNX… Suraj Patil created this awesome repo that incorporates the ONNX script with the Hugging Face pipeline framework.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and DataScience, highlighting their complementary roles in Data Analysis and intelligent decision-making. Introduction Artificial Intelligence (AI) and DataScience are revolutionising how we analyse data, make decisions, and solve complex problems.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! Deep learning refers to the use of neuralnetwork architectures, characterized by their multi-layer design (i.e. Since 2014, he has been working in datascience for government, academia, and the private sector. deep” architecture).
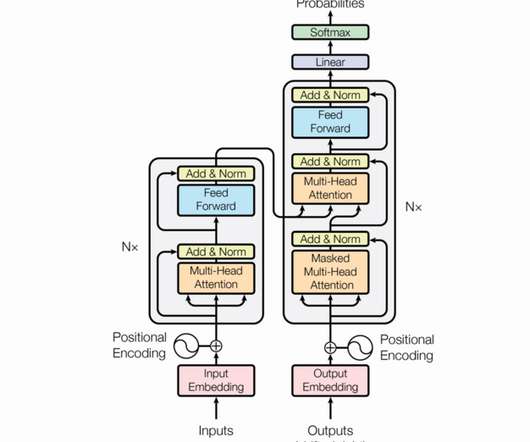
The other data challenge for healthcare customers are HIPAA compliance requirements. Transformers, BERT, and GPT The transformer architecture is a neuralnetwork architecture that is used for natural language processing (NLP) tasks. It was first introduced in the paper “Attention Is All You Need” by Vaswani et al.
The journey continues with “NLP and Deep Learning,” diving into the essentials of Natural Language Processing , deep learning's role in NLP, and foundational concepts of neuralnetworks. ChatGPT for Productivity showcases the use of ChatGPT in various fields such as datascience, marketing, and project management.
From Big Data to NLP insights: Getting started with PySpark and Spark NLP The amount of data being generated today is staggering and growing. Apache Spark has emerged as the de facto tool to analyze big data over the last few years and is now a critical part of the datascience toolbox.
This is due to a deep disconnect between data engineering and datascience practices. Historically, our space has perceived streaming as a complex technology reserved for experienced data engineers with a deep understanding of incremental event processing.
The 1970s introduced bell bottoms, case grammars, semantic networks, and conceptual dependency theory. In the 90’s we got grunge, statistical models, recurrent neuralnetworks and long short-term memory models (LSTM). It uses a neuralnetwork to learn the vector representations of words from a large corpus of text.
This ongoing process straddles the intersection between evidence-based medicine, datascience, and artificial intelligence (AI). BioBERT and similar BERT-based NER models are trained and fine-tuned using a biomedical corpus (or dataset) such as NCBI Disease, BC5CDR, or Species-800. a text file with one word per line).
Now, imagine a large, pretrained model tailored for time-series data — one that delivers accurate predictions without extensive retraining. Their decoder-only model, inspired by NLP giants like BERT, uses a patch-based approach to handle data efficiently.
NeuralNetwork-Based Embeddings The fourth part delves into neuralnetwork-based embeddings, including word2vec and GloVe, that provide dense and compact representations of words. Large Language Models Finally, the course concludes with a look at large language models, such as BERT, ELMo, GPT, and ULMFiT.
ODSC West 2024 showcased a wide range of talks and workshops from leading datascience, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best datascience instructors, focusing on cutting-edge advancements in AI, data modeling, and deployment strategies.
Formula to calculate n-gram probabilities; image by Peter Martigny on Feedly Neural Language Models Neural language models make use of artificial neuralnetworks to discover the patterns and structures in a language. One of the most popular language models is the Recurrent NeuralNetwork Language Model (RNNLM).
Machine Learning for DataScience and Analytics Authors: Ansaf Salleb-Aouissi, Cliff Stein, David Blei, Itsik Peer Associate, Mihalis Yannakakis, Peter Orbanz If you ever dreamt of attending classes at Columbia University but never had the chance, this artificial intelligence course focused on ML is the next best thing.
The underlying architecture of LLMs typically involves a deep neuralnetwork with multiple layers. Based on the discovered patterns and connections found in the training data, this network analyses the input text and produces predictions.
The following is a high-level overview of how it works conceptually: Separate encoders – These models have separate encoders for each modality—a text encoder for text (for example, BERT or RoBERTa), image encoder for images (for example, CNN for images), and audio encoders for audio (for example, models like Wav2Vec).
This book effectively killed off interest in neuralnetworks at that time, and Rosenblatt, who died shortly thereafter in a boating accident, was unable to defend his ideas. (I Around this time a new graduate student, Geoffrey Hinton, decided that he would study the now discredited field of neuralnetworks.
The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment. All of this made it easy for researchers and practitioners to use BERT.
The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment. All of this made it easy for researchers and practitioners to use BERT.
In this article, we will explore about ALBERT ( A lite weighted version of BERT machine learning model) What is ALBERT? ALBERT (A Lite BERT) is a language model developed by Google Research in 2019. BERT, GPT-2, and XLNet are some examples of models that can be used as teacher models for ALBERT.
Transformers taking the AI world by storm The family of artificial neuralnetworks (ANNs) saw a new member being born in 2017, the Transformer. Initially introduced for Natural Language Processing (NLP) applications like translation, this type of network was used in both Google’s BERT and OpenAI’s GPT-2 and GPT-3.
Transformer-based models, such as Bidirectional Encoder Representations from Transformers (BERT), have revolutionized NLP by offering accuracy comparable to human baselines on benchmarks like SQuAD for question-answer, entity recognition, intent recognition, sentiment analysis, and more. Basic understanding of neuralnetworks.
While rarely an endpoint, large language model (LLM) distillation lets datascience teams kickstart the data development process and get to a production-ready model faster than they could with traditional approaches. The student model could be a simple model like logistic regression or a foundation model like BERT.
While rarely an endpoint, large language model (LLM) distillation lets datascience teams kickstart the data development process and get to a production-ready model faster than they could with traditional approaches. The student model could be a simple model like logistic regression or a foundation model like BERT.
By using Graph NeuralNetworks (GNNs), GuardDuty is able to enhance its capability to alert customers. GraphStorm enables our team to train GNN embedding in a self-supervised manner on a graph with 288 million nodes and 2 billion edges,” Says Haining Yu, Principal Applied Scientist at Amazon Measurement, Ad Tech, and DataScience.
RoBERTa RoBERTa (Robustly Optimized BERT Approach) is a natural language processing (NLP) model based on the BERT (Bidirectional Encoder Representations from Transformers) architecture. This refers to the fact that BERT was pre-trained on one set of tasks but fine-tuned on a different set of tasks for downstream NLP applications.
Sequence models have gained traction in the past 5 years and it’s been very active research of study, even the GPT models — on which ChatGPT was implemented using the concept of Transformers and BERT , which is based on Self-Attention model — it is based on Attention models — which uses the base of Encoder-Decoder sequence models.
Photo by GuerrillaBuzz on Unsplash Graph Convolutional Networks (GCNs) are a type of neuralnetwork that operates on graphs, which are mathematical structures consisting of nodes and edges. GCNs have been successfully applied to many domains, including computer vision and social network analysis. & Nie, JY.
Dall-e , and pre-2022 tools in general, attributed their success either to the use of the Transformer or Generative Adversarial Networks. The former is a powerful architecture for artificial neuralnetworks that was originally introduced for language tasks (you’ve probably heard of GPT-3 ?) Who should I follow? What happened?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























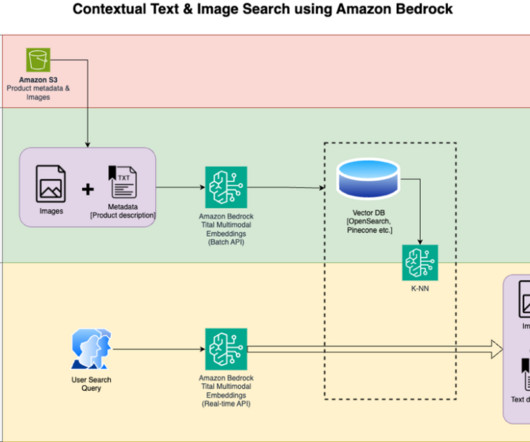








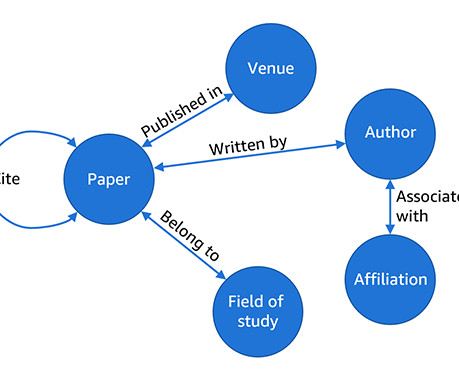

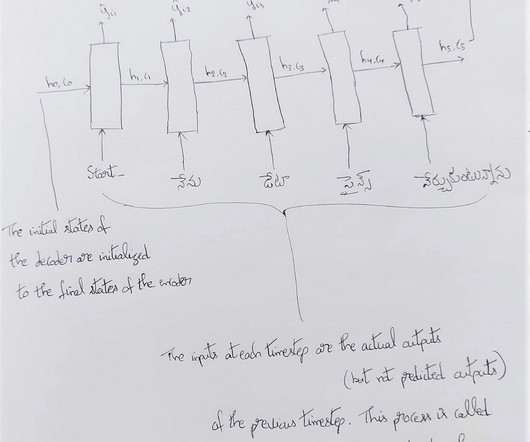








Let's personalize your content