This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
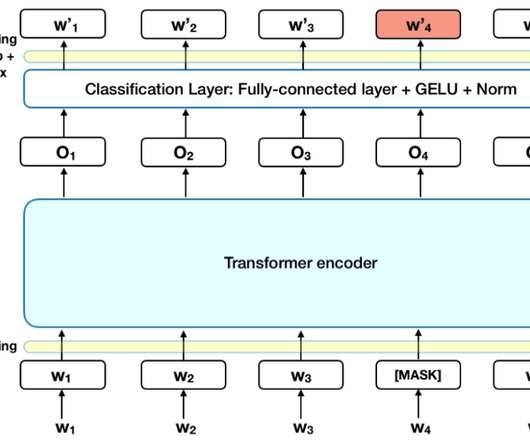
This article was published as a part of the DataScience Blogathon Introduction In the past few years, Naturallanguageprocessing has evolved a lot using deep neural networks. BERT (Bidirectional Encoder Representations from Transformers) is a very recent work published by Google AI Language researchers.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction NLP or NaturalLanguageProcessing is an exponentially growing field. The post Why and how to use BERT for NLP Text Classification? appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction NaturalLanguageprocessing, a sub-field of machine learning has gained. The post Amazon Product review Sentiment Analysis using BERT appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction Named Entity Recognition is a major task in NaturalLanguageProcessing (NLP) field. The post Fine-tune BERT Model for Named Entity Recognition in Google Colab appeared first on Analytics Vidhya.
The Challenge Legal texts are uniquely challenging for naturallanguageprocessing (NLP) due to their specialized vocabulary, intricate syntax, and the critical importance of context. Terms that appear similar in general language can have vastly different meanings in legal contexts.
This article was published as a part of the DataScience Blogathon. Text summarization is an NLP(NaturalLanguageProcessing) task. SBERT(Sentence-BERT) has […]. The post A Flask Web App for Automatic Text Summarization Using SBERT appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Source: totaljobs.com Introduction Transformers have become a powerful tool for different naturallanguageprocessing tasks. The impressive performance of the transformer is mainly attributed to its self-attention mechanism.
Over the past decade, datascience has undergone a remarkable evolution, driven by rapid advancements in machine learning, artificial intelligence, and big data technologies. This blog dives deep into these changes of trends in datascience, spotlighting how conference topics mirror the broader evolution of datascience.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
To achieve this, Lumi developed a classification model based on BERT (Bidirectional Encoder Representations from Transformers) , a state-of-the-art naturallanguageprocessing (NLP) technique. They fine-tuned this model using their proprietary dataset and in-house datascience expertise.
In 2018 when BERT was introduced by Google, I cannot emphasize how much it changed the game within the NLP community. This ability to understand long-range dependencies helps transformers better understand the context of words and achieve superior performance in naturallanguageprocessing tasks.
Once a set of word vectors has been learned, they can be used in various naturallanguageprocessing (NLP) tasks such as text classification, language translation, and question answering. ELMo, on the other hand, is only pre-trained on a smaller amount of text data and is not fine-tuned.
Naturallanguageprocessing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader datascience expertise.
GenAI I serve as the Principal Data Scientist at a prominent healthcare firm, where I lead a small team dedicated to addressing patient needs. Over the past 11 years in the field of datascience, I’ve witnessed significant transformations. In 2023, we witnessed the substantial transformation of AI, marking it as the ‘year of AI.’
Applications for naturallanguageprocessing (NLP) have exploded in the past decade. With the proliferation of AI assistants and organizations infusing their businesses with more interactive human-machine experiences, understanding how NLP techniques can be used to manipulate, analyze, and generate text-based data is essential.
Pixabay: by Activedia Image captioning combines naturallanguageprocessing and computer vision to generate image textual descriptions automatically. This integration combines visual features extracted from images with language models to generate descriptive and contextually relevant captions.
A foundation model is built on a neural network model architecture to process information much like the human brain does. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. An open-source model, Google created BERT in 2018.
They are now capable of naturallanguageprocessing ( NLP ), grasping context and exhibiting elements of creativity. Innovators who want a custom AI can pick a “foundation model” like OpenAI’s GPT-3 or BERT and feed it their data.
For instance, neural networks used for naturallanguageprocessing tasks (like text summarization, question answering, and translation) are known as transformers. Prominent transformer models include BERT , GPT-4 , and T5.
But now, a computer can be taught to comprehend and process human language through NaturalLanguageProcessing (NLP), which was implemented, to make computers capable of understanding spoken and written language. It has a state-of-the-art language representation model developed by Facebook AI.
NaturalLanguageProcessing (NLP) tasks involve analyzing, understanding, and generating human language. However, the first step in any NLP task is to pre-process the text for training. Load the pre-trained language model: Load the pre-trained language model that you want to customize.
RoBERTa is an optimized variant of BERT, designed to improve the pretraining process and fine-tune hyperparameters, leading to enhanced performance across a wide range of naturallanguageprocessing tasks. Both challenges will be addressed using RoBERTa, a state-of-the-art Transformer-based machine learning model.
ChatGPT released by OpenAI is a versatile NaturalLanguageProcessing (NLP) system that comprehends the conversation context to provide relevant responses. Although little is known about construction of this model, it has become popular due to its quality in solving naturallanguage tasks.
Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for naturallanguageprocessing (NLP) tasks. BERT can be fine-tuned for a variety of NLP tasks, including question answering, naturallanguage inference, and sentiment analysis.
To learn more about how NYUTron was developed along with the limitations and possibilities of AI support tools for healthcare providers, CDS spoke with Lavender Jiang , PhD student at the NYU Center for DataScience and lead author of the study. Read our Q&A with Lavender below!
However, sifting through thousands of text-based reviews across multiple platforms and languages can be overwhelming and time-consuming, often leaving valuable insights buried beneath the sheer volume of data. and 86% accuracy, respectively, outperforming state-of-the-art baselines like BERT and RoBERTa.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and DataScience, highlighting their complementary roles in Data Analysis and intelligent decision-making. Introduction Artificial Intelligence (AI) and DataScience are revolutionising how we analyse data, make decisions, and solve complex problems.
NaturalLanguageProcessing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as data extraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
With advancements in deep learning, naturallanguageprocessing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! If a NaturalLanguageProcessing (NLP) system does not have that context, we’d expect it not to get the joke. Since 2014, he has been working in datascience for government, academia, and the private sector.
From Big Data to NLP insights: Getting started with PySpark and Spark NLP The amount of data being generated today is staggering and growing. Apache Spark has emerged as the de facto tool to analyze big data over the last few years and is now a critical part of the datascience toolbox.
Ivan Aivazovsky — Istanbul NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 09.06.20 Last Updated on July 21, 2023 by Editorial Team Author(s): Ricky Costa Originally published on Towards AI. Revival Welcome back, and what a week?!?! Time to say goodbye to Summer. ? if you enjoy the read!
From deep learning, NaturalLanguageProcessing (NLP), and NaturalLanguage Understanding (NLU) to Computer Vision, AI is propelling everyone into a future with endless innovations. It is a potent model for comprehending and processingnaturallanguage with 340 million parameters.
Implementing end-to-end deep learning projects has never been easier with these awesome tools Image by Freepik LLMs such as GPT, BERT, and Llama 2 are a game changer in AI. But you need to fine-tune these language models when performing your deep learning projects. You can build AI tools like ChatGPT and Bard using these models.
The journey continues with “NLP and Deep Learning,” diving into the essentials of NaturalLanguageProcessing , deep learning's role in NLP, and foundational concepts of neural networks. ChatGPT for Productivity showcases the use of ChatGPT in various fields such as datascience, marketing, and project management.
Soon to be followed by large general language models like BERT (Bidirectional Encoder Representations from Transformers). In the last few years, if you google healthcare or clinical NLP, you would see that the search results are blanketed by a few names like John Snow Labs (JSL), Linguamatics (IQVIA), Oncoustics, BotMD, Inspirata.
Some examples of large language models include GPT (Generative Pre-training Transformer), BERT (Bidirectional Encoder Representations from Transformers), and RoBERTa (Robustly Optimized BERT Approach). You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
With the challenges of immense volumes of textual data today, the field of NaturalLanguageProcessing (NLP) is rapidly evolving. These models leverage massive amounts of text to learn a broad range of language patterns and nuances, which can then be applied to a variety of NLP tasks without domain-specific tuning.
Instead, they are trained on vast amounts of text data using self-supervised learning, which enables them to implicitly learn patterns, including various forms of intent, through the context of the trainingdata.
The medical industry is exploding with data. The increasing universality of electronic health records (EHRs) , the maturity of genomic datascience, and the growing popularity of wearable devices and health apps have created an enormous influx of data for both practitioners and researchers. Chat with us today!
Top Large Language Models of 2023 LLaMa : LLaMa (Language Model for Academic Applications) is a large language model from Google AI. It’s designed specifically for naturallanguageprocessing tasks in the academic domain, such as summarization, question answering, and text classification. Get yours today!
One of the most popular techniques for speech recognition is naturallanguageprocessing (NLP), which entails training machine learning models on enormous amounts of text data to understand linguistic patterns and structures. It was pre-trained on a more extensive and diverse data set to address this.
source: author Introduction Sentiment analysis is a rapidly growing field within the NaturalLanguageProcessing (NLP) domain, which deals with the automatic analysis and classification of emotions and opinions expressed in text. dplyr: This is a package for data manipulation and cleaning in R.
While a majority of NaturalLanguageProcessing (NLP) models focus on English, the real world requires solutions that work with languages across the globe. Labeling data from scratch for every new language would not scale, even if the final architecture remained the same.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content