This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
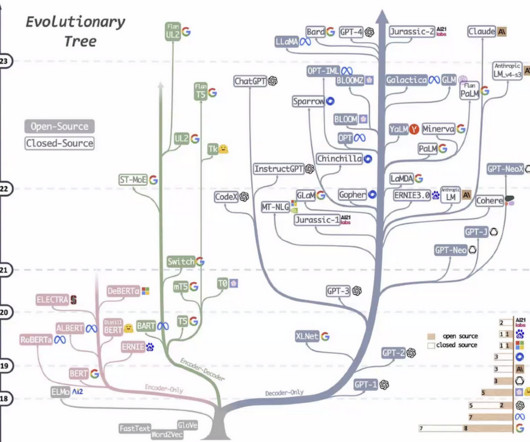
Over the past decade, datascience has undergone a remarkable evolution, driven by rapid advancements in machine learning, artificial intelligence, and big data technologies. This blog dives deep into these changes of trends in datascience, spotlighting how conference topics mirror the broader evolution of datascience.
The field of datascience has evolved dramatically over the past several years, driven by technological breakthroughs, industry demands, and shifting priorities within the community. 20212024: With automated insights and AI-driven analytics improving, the emphasis shifted from visualization to explainability and storytelling.
Their comparative analysis included decoder-only transformers like Pythia, encoder-only models like BERT, and state space models (SSMs) like Mamba. The teams latest research expands the analysis to more models and training regimes while offering a comprehensive theoretical framework to explain why intermediate representations excel.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. Solution overview In this section, we present the overall workflow and explain the approach.
Explainability of machine learning (ML) models used in the medical domain is becoming increasingly important because models need to be explained from a number of perspectives in order to gain adoption. Explainability of these predictions is required in order for clinicians to make the correct choices on a patient-by-patient basis.
The following is a brief tutorial on how BERT and Transformers work in NLP-based analysis using the Masked Language Model (MLM). Introduction In this tutorial, we will provide a little background on the BERT model and how it works. The BERT model was pre-trained using text from Wikipedia. What is BERT? How Does BERT Work?
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
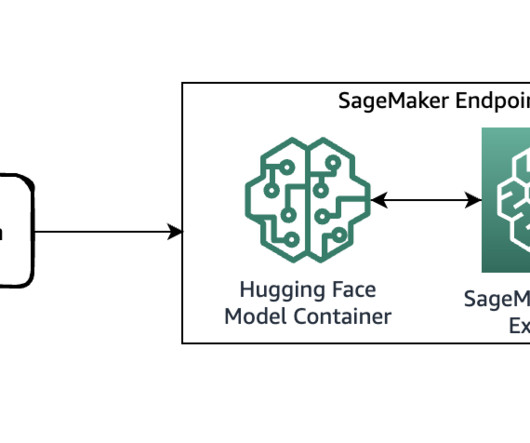
In this post, we explain how we built an end-to-end product category prediction pipeline to help commercial teams by using Amazon SageMaker and AWS Batch , reducing model training duration by 90%. An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages.
In a recent interview, Chen explained the importance of studying interpretability artifacts not just at the end of a model’s training but throughout its entire learning process. “A The paper is a case study of syntax acquisition in BERT (Bidirectional Encoder Representations from Transformers).
A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018.
Prominent transformer models include BERT , GPT-4 , and T5. These techniques explain complex ML models and provide insights about their predictions, thus helping ML practitioners understand their models even better. These models are creating an impact on industries ranging from healthcare, retail, marketing, finance , etc.
Based on the BERT model, it has been fine-tuned on a dataset of biomedical text. But if we’ve learned anything, climate science and all the data produced by researchers could also benefit from LLMs. Part of the BERT family of models, ClimateBERT is specifically trained on climate-related text. Get your pass today !
Implementing end-to-end deep learning projects has never been easier with these awesome tools Image by Freepik LLMs such as GPT, BERT, and Llama 2 are a game changer in AI. Here are the topics we’ll cover in this article: Fine-tuning the BERT model with the Transformers library for text classification. Monitoring this app with Comet.
Some examples of large language models include GPT (Generative Pre-training Transformer), BERT (Bidirectional Encoder Representations from Transformers), and RoBERTa (Robustly Optimized BERT Approach). You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
The medical industry is exploding with data. The increasing universality of electronic health records (EHRs) , the maturity of genomic datascience, and the growing popularity of wearable devices and health apps have created an enormous influx of data for both practitioners and researchers. Chat with us today!
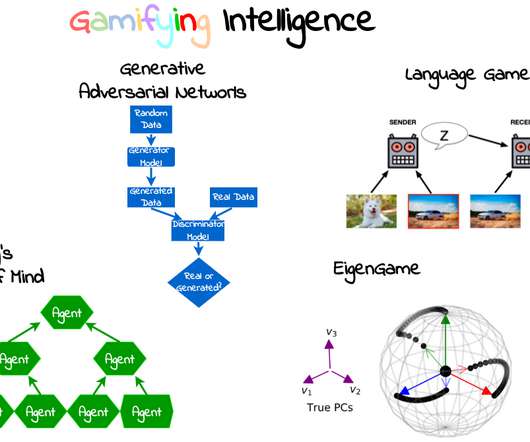
ODSC West 2024 showcased a wide range of talks and workshops from leading datascience, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best datascience instructors, focusing on cutting-edge advancements in AI, data modeling, and deployment strategies.
The medical industry is exploding with data. The increasing universality of electronic health records (EHRs) , the maturity of genomic datascience, and the growing popularity of wearable devices and health apps have created an enormous influx of data for both practitioners and researchers. Chat with us today!
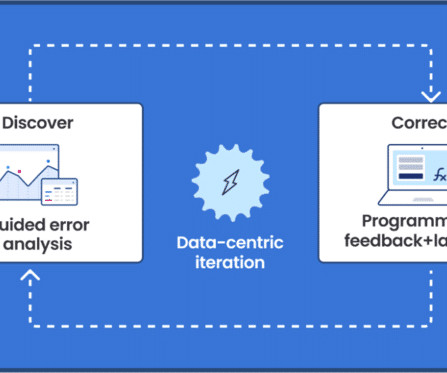
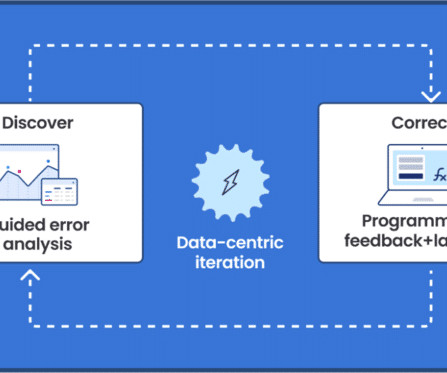
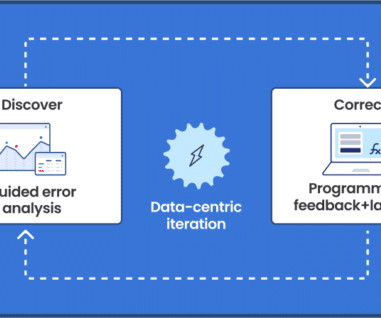
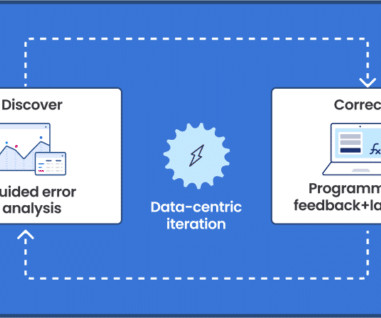
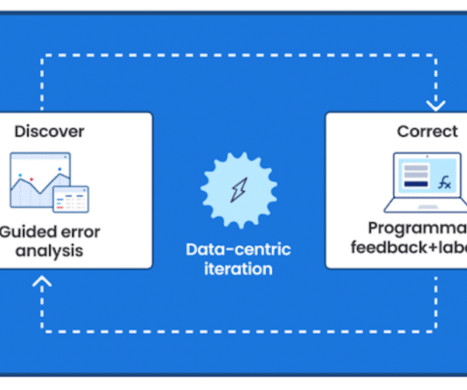
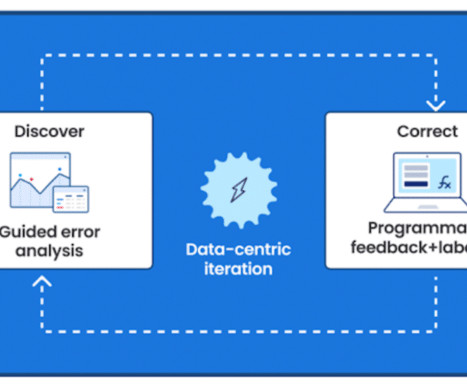
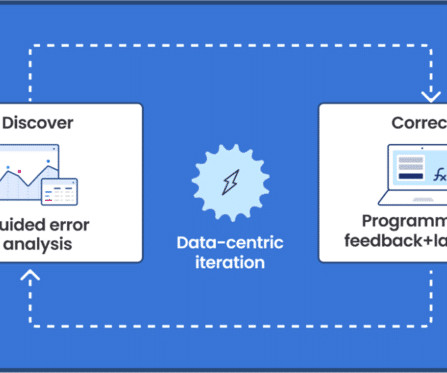
FMs can also have low explainability, making them hard to understand, adjust, or improve. The Snorkel advantage for claims processing Snorkel offers a data-centric AI framework that insurance providers can use to generate high-quality training data for ML models and create custom models to streamline claims processing.
In Part 1 (fine-tuning a BERT model), I explained what a transformer model is and the various open source models types that are available from Hugging Face’s free transformers library. We also walked through how to fine-tune a BERT model to conduct sentiment analysis. In Part… Read the full blog for free on Medium.
RoBERTa RoBERTa (Robustly Optimized BERT Approach) is a natural language processing (NLP) model based on the BERT (Bidirectional Encoder Representations from Transformers) architecture. This refers to the fact that BERT was pre-trained on one set of tasks but fine-tuned on a different set of tasks for downstream NLP applications.
In this article, we will explore about ALBERT ( A lite weighted version of BERT machine learning model) What is ALBERT? ALBERT (A Lite BERT) is a language model developed by Google Research in 2019. BERT, GPT-2, and XLNet are some examples of models that can be used as teacher models for ALBERT.
FMs can also have low explainability, making them hard to understand, adjust, or improve. The Snorkel advantage for claims processing Snorkel offers a data-centric AI framework that insurance providers can use to generate high-quality training data for ML models and create custom models to streamline claims processing.
Machine Learning for DataScience and Analytics Authors: Ansaf Salleb-Aouissi, Cliff Stein, David Blei, Itsik Peer Associate, Mihalis Yannakakis, Peter Orbanz If you ever dreamt of attending classes at Columbia University but never had the chance, this artificial intelligence course focused on ML is the next best thing.
Data teams can fine-tune LLMs like BERT, GPT-3.5 These could be risk prediction models, future earning models, or robust consumer profiles that incorporate traditional and alternative data. Lenders and credit agencies can use Snorkel to: Quickly and programmatically develop training data for credit scoring models.
The recommendations cover everything from datascience to data analysis, programming, and general business. Meaning you’ll have a better understanding of all the mechanisms to make you a more effective data scientist if you read even just a few of these books. This works the other way round, too.
They design intricate sequences of prompts, leveraging their knowledge of AI, machine learning, and datascience to guide powerful LLMs (Large Language Models) towards complex tasks. Datascience methodologies and skills can be leveraged to design these experiments, analyze results, and iteratively improve prompt strategies.
Data teams can fine-tune LLMs like BERT, GPT-3.5 These could be risk prediction models, future earning models, or robust consumer profiles that incorporate traditional and alternative data. Lenders and credit agencies can use Snorkel to: Quickly and programmatically develop training data for credit scoring models.
The medical industry is exploding with data. The increasing universality of electronic health records (EHRs) , the maturity of genomic datascience, and the growing popularity of wearable devices and health apps have created an enormous influx of data for both practitioners and researchers.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
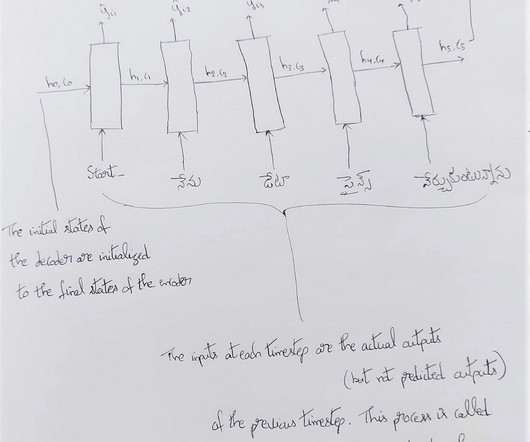
Sequence models have gained traction in the past 5 years and it’s been very active research of study, even the GPT models — on which ChatGPT was implemented using the concept of Transformers and BERT , which is based on Self-Attention model — it is based on Attention models — which uses the base of Encoder-Decoder sequence models.
Both of these computations have a complexity scaling in the cube of the data’s number of features. This explain this statement at the NeurIPS 2017 Test-of-Time Award: It seems easier to train a bi-directional LSTM with attention than to compute the PCA of a large matrix. — Rahimi
Currently, there’s a lot of development in this field from BERT to GPT-2 and these models are pre-trained on very large corpora. Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deep learning practitioners.
Hugging Face transformer models BERT, GPT-2, RoBERTa, and T5 are included in the library. BERT is one of the most popular Hugging Face transformer models (Bidirectional Encoder Representations from Transformers). To train the transformer model BERT, a massive corpus of text was used. Next, we move on to the model inference step.
This technique is commonly used in neural network-based models such as BERT, where it helps to handle out-of-vocabulary words. Three examples of tokenization methods; image from FreeCodeCamp Tokenization is a fundamental step in data preparation for NLP tasks.
The emergence of Large Language Models (LLMs) like OpenAI's GPT , Meta's Llama , and Google's BERT has ushered in a new era in this field. Interpretability and Explainability: As LLMs become more powerful, the focus on understanding model decision-making processes will intensify.
The update fixed outstanding bugs on the tracker, gave the docs a huge makeover, improved both speed and accuracy, made installation significantly easier and faster, and added some exciting new features, like ULMFit/BERT/ELMo-style language model pretraining. Sep 24: Datascience instructor Vincent returned for “Intro to NLP with spaCy #2”.
Initially introduced for Natural Language Processing (NLP) applications like translation, this type of network was used in both Google’s BERT and OpenAI’s GPT-2 and GPT-3. ADSP is a London based consultancy that implements end-to-end datascience solutions for businesses, delivering measurable value. But at what cost?
Revolutionizing Healthcare through DataScience and Machine Learning Image by Cai Fang on Unsplash Introduction In the digital transformation era, healthcare is experiencing a paradigm shift driven by integrating datascience, machine learning, and information technology.
Data teams can fine-tune LLMs like BERT, GPT-3.5 These could be risk prediction models, future earning models, or robust consumer profiles that incorporate traditional and alternative data. Lenders and credit agencies can use Snorkel to: Quickly and programmatically develop training data for credit scoring models.
are all ‘unstructured data’ , and an advanced AI is required to understand the information in order to obtain our answers. This is why you would have heard of new QA technologies such as BERT, GPT3, ELECTRA etc. If not, then a quick summary- Huggingface is a data-science platform that helps us use pre-trained models for our purposes.
We compare the existing solutions and explain how they work behind the scenes. In this article we will focus solely on AI Agents capable of solving software engineering and datascience problems. A comprehensive review of the state of the art in terms of code-writing agents. Back to point 2.
Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables data scientists & ML teams to track, compare, explain, & optimize their experiments. . & Nie, JY. We’re committed to supporting and inspiring developers and engineers from all walks of life.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content