This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon Introduction In the past few years, Natural language processing has evolved a lot using deep neural networks. BERT (Bidirectional Encoder Representations from Transformers) is a very recent work published by Google AI Language researchers. It […].
This article was published as a part of the DataScience Blogathon Introduction In 2018, a powerful Transformer-based machine learning model, namely, BERT was developed by Jacob Devlin and his colleagues from Google for NLP applications.
This article was published as a part of the DataScience Blogathon. Introduction BERT is a really powerful language representation model that has been. The post Simple Text Multi Classification Task Using Keras BERT appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon BERT is too kind — so this article will be touching. The post Measuring Text Similarity Using BERT appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Introduction In the previous article, we have talked about BERT, Its Usage, And Understood some of its underlying Concepts. This article is intended to show how one can implement the learned concept to create a spam classifier using BERT.
This article was published as a part of the DataScience Blogathon Source: huggingface.io The post Manual for the First Time Users: Google BERT for Text Classification appeared first on Analytics Vidhya. Hey Folks! […].
This article was published as a part of the DataScience Blogathon Overview Text classification is one of the most interesting domains today. In this article, we are going to use BERT along with a neural […]. The post Disaster Tweet Classification using BERT & Neural Network appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction In this article, we will learn to train Bidirectional Encoder Representations from Transformers (BERT) in order to analyze the semantic equivalence of any two sentences, i.e. whether the two sentences convey the same meaning or not.
This article was published as a part of the DataScience Blogathon Objective In this blog, we will learn how to Fine-tune a Pre-trained BERT model for the Sentiment analysis task. The post Fine-tune BERT Model for Sentiment Analysis in Google Colab appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Introduction In this article, you will learn about the input required for BERT in the classification or the question answering system development. Before diving directly into BERT let’s discuss the […].
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction NLP or Natural Language Processing is an exponentially growing field. The post Why and how to use BERT for NLP Text Classification? appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Training hugging face most famous model on TPU for social media. The post Training BERT Text Classifier on Tensor Processing Unit (TPU) appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Natural Language processing, a sub-field of machine learning has gained. The post Amazon Product review Sentiment Analysis using BERT appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction to BERT: BERT stands for Bidirectional Encoder Representations from Transformers. The post BERT for Natural Language Inference simplified in Pytorch! appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. The post Fine-tune BERT Model for Named Entity Recognition in Google Colab appeared first on Analytics Vidhya. Introduction Named Entity Recognition is a major task in Natural Language Processing (NLP) field.
In this article, we will delve into how Legal-BERT [5], a transformer-based model tailored for legal texts, can be fine-tuned to classify contract provisions using the LEDGAR dataset [4] — a comprehensive benchmark dataset specifically designed for the legal field. Fine-tuning Legal-BERT for multi-class classification of legal provisions.
Introduction Say Goodbye to Your Search for the Perfect DataScience Learning Platform – Analytics Vidhya is Here! Discover Analytics Vidhya, Your Ultimate DataScience Destination! Our focus is on empowering our community and providing opportunities for professional growth.
This article was published as a part of the DataScience Blogathon. Source: Canva|Arxiv Introduction In 2018 GoogleAI researchers developed Bidirectional Encoder Representations from Transformers (BERT) for various NLP tasks.
Overview Working on DataScience projects is a great way to stand out from the competition Check out these 7 datascience projects on. The post Here are 7 DataScience Projects on GitHub to Showcase your Machine Learning Skills! appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Source: Canva Introduction In 2018, GoogleAI researchers released the BERT model. However, the BERT model did have some drawbacks i.e. it was bulky and hence a little slow. It was a fantastic work that brought a revolution in the NLP domain.
This article was published as a part of the DataScience Blogathon Introduction In the last article, we have discussed implementing the BERT model using the TensorFlow hub; you can read it here. Implementing BERT using the TensorFlow hub was tedious since we had to perform every step from scratch.
This article was published as a part of the DataScience Blogathon. Source: Canva Introduction In 2018, Google AI researchers came up with BERT, which revolutionized the NLP domain. The key […].
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Machines understand language through language representations. The post All You Need to know about BERT appeared first on Analytics Vidhya. These language representations are.
Datascience for mental health Data Analysis Techniques in MULTIWD We have used machine learning and datascience techniques to explore the wellness dimensions in rich and unstructured crude text. This indicates that they can accurately portray the complexity of multiple dimensions in social media language.
This article was published as a part of the DataScience Blogathon. For more details, check my previous article on fine tune Bert for NER. Introduction to Named Entity Recognition A named entity is a ‘real-world object’ that is assigned a name, for example, person, organization, or location.
This article was published as a part of the DataScience Blogathon. SBERT(Sentence-BERT) has […]. Dear readers, In this blog, we will build a Flask web app that can input any long piece of information such as a blog or news article and summarize it into just five lines!
Over the past decade, datascience has undergone a remarkable evolution, driven by rapid advancements in machine learning, artificial intelligence, and big data technologies. This blog dives deep into these changes of trends in datascience, spotlighting how conference topics mirror the broader evolution of datascience.
The field of datascience has evolved dramatically over the past several years, driven by technological breakthroughs, industry demands, and shifting priorities within the community. The rise and fall of datascience trends reflect the ever-changing nature of the field.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
This article was published as a part of the DataScience Blogathon Image source: huggingface.io Contents 1. […]. The post All NLP tasks using Transformers Pipeline appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. COVID-19 has affected the lives of many through losing beloved ones, being laid-off from jobs, and social distancing from the world. The post Classification of Tweets using SpaCy appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction Training and inference with large neural models are computationally expensive and time-consuming. While new tasks and models emerge so often for many application domains, the underlying documents being modeled stay mostly unaltered.
GPT, BERT) Image Generation (e.g., Data Handling and Preprocessing: Data Cleaning, Augmentation, and Feature Engineering 7. Explore text generation models like GPT and BERT. Hugging Face: For working with pre-trained NLP models like GPT and BERT. Generative AI Techniques: Text Generation (e.g.,
This article was published as a part of the DataScience Blogathon. Introduction Here’s a quick puzzle for you. I’ll give you two titles, and you’ll have to tell me which is fake. Let’s get started: “Adani Group is planning to explore investment in the EV sector.” ” […].
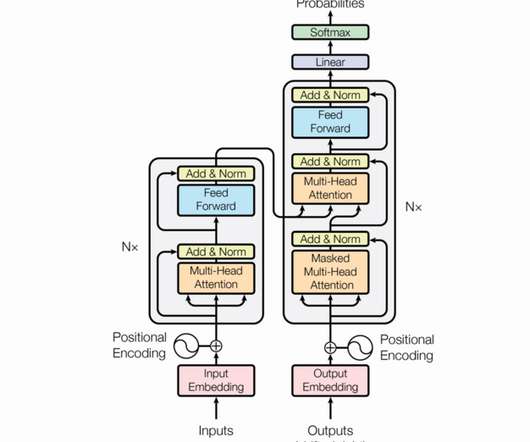
This article was published as a part of the DataScience Blogathon. Source: totaljobs.com Introduction Transformers have become a powerful tool for different natural language processing tasks. The impressive performance of the transformer is mainly attributed to its self-attention mechanism.
This article was published as a part of the DataScience Blogathon. Source: Canva Introduction In 2018 Google AI released a self-supervised learning model […]. The post A Gentle Introduction to RoBERTa appeared first on Analytics Vidhya.
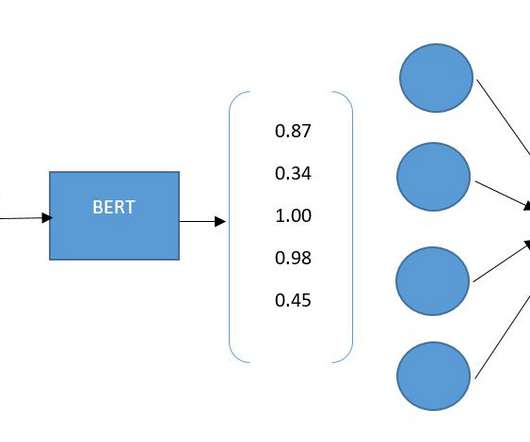
To achieve this, Lumi developed a classification model based on BERT (Bidirectional Encoder Representations from Transformers) , a state-of-the-art natural language processing (NLP) technique. They fine-tuned this model using their proprietary dataset and in-house datascience expertise. Follow her on LinkedIn.
The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader datascience expertise. In a change from last year, there’s also a higher demand for those with data analysis skills as well. Having mastery of these two will prove that you know datascience and in turn, NLP.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
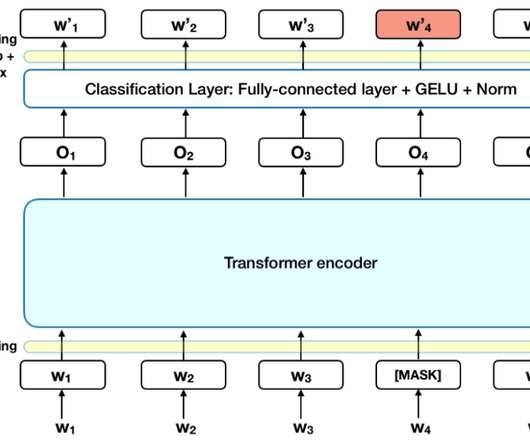
The following is a brief tutorial on how BERT and Transformers work in NLP-based analysis using the Masked Language Model (MLM). Introduction In this tutorial, we will provide a little background on the BERT model and how it works. The BERT model was pre-trained using text from Wikipedia. What is BERT? How Does BERT Work?
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
In financial and social media datasets, it outperformed established LLMs like BERT, GPT-2, andLLaMA. Temple leverages soft prompting and language modeling techniques to incorporate textual information into time series forecasting. The result? More informed predictions are grounded in both quantitative signals and qualitative context.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































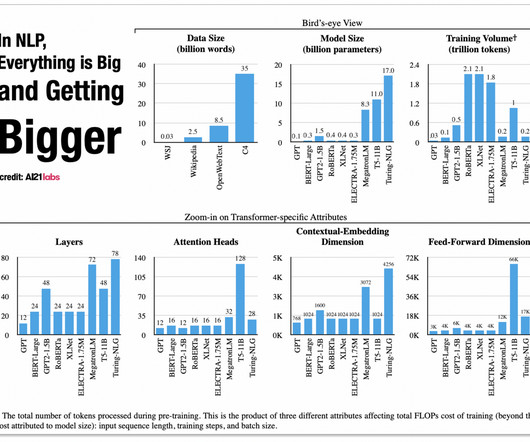








Let's personalize your content