This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Encoder models like BERT and RoBERTa have long been cornerstones of natural language processing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. DataScarcity: Pre-training on small datasets (e.g., Wikipedia + BookCorpus) restricts knowledge diversity.
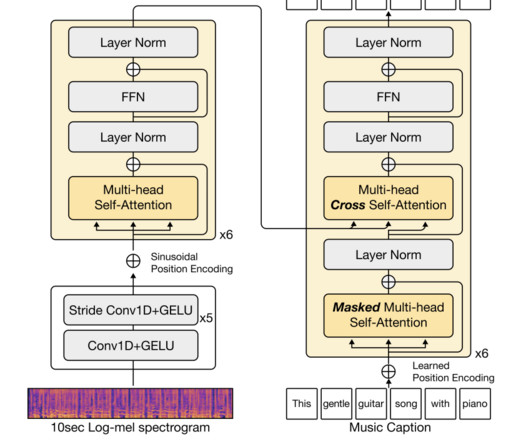
Also, the limited number of available music-language datasets poses a challenge. With the scarcity of datasets, training a music captioning model successfully doesn’t remain easy. Largelanguagemodels (LLMs) could be a potential solution for music caption generation. They opted for the powerful GPT-3.5
However, generating synthetic data for NLP is non-trivial, demanding high linguistic knowledge, creativity, and diversity. Different methods, such as rule-based and data-driven approaches, have been proposed to generate synthetic data. To address this, techniques include using domain-specific languages (e.g.,
For instance, the analogy of the masked token prediction task used to train BERT is known as masked image modeling in computer vision. In NLP, this refers to finding the most optimal text to feed the LargeLanguageModel for enhanced performance. Source: [link]. The first concept is prompt engineering.
For instance, the analogy of the masked token prediction task used to train BERT is known as masked image modeling in computer vision. In NLP, this refers to finding the most optimal text to feed the LargeLanguageModel for enhanced performance. Source: [link]. The first concept is prompt engineering.
LargeLanguageModels (LLMs) have revolutionized natural language processing in recent years. The pre-train and fine-tune paradigm, exemplified by models like ELMo and BERT, has evolved into prompt-based reasoning used by the GPT family.
At the forefront of this transformation are LargeLanguageModels (LLMs). These intelligent models have transcended their traditional linguistic boundaries to influence music generation. This approach enables high-quality, controllable melody generation with minimal lyric-melody paired data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content