This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
LLMs are deep neural networks that can generate naturallanguage texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in NaturalLanguageProcessing (NLP).
Both BERT and GPT are based on the Transformer architecture. Word embedding is a technique in naturallanguageprocessing (NLP) where words are represented as vectors in a continuous vector space. This focus on understanding context is similar to the way YData Fabric, a dataquality platform designed for data […]
NLP, or NaturalLanguageProcessing, is a field of AI focusing on human-computer interaction using language. NLP aims to make computers understand, interpret, and generate human language. Recent NLP research has focused on improving few-shot learning (FSL) methods in response to data insufficiency challenges.
Much like how foundation models in language, such as BERT and GPT, have transformed naturallanguageprocessing by leveraging vast textual data, pretrained foundation models hold similar promise for SDM.
The advancements in large language models have significantly accelerated the development of naturallanguageprocessing , or NLP. These extend far beyond the traditional text-based processing of LLMs to include multimodal interactions.
They serve as a core building block in many naturallanguageprocessing (NLP) applications today, including information retrieval, question answering, semantic search and more. More recent methods based on pre-trained language models like BERT obtain much better context-aware embeddings.
Sentiment analysis, commonly referred to as opinion mining/sentiment classification, is the technique of identifying and extracting subjective information from source materials using computational linguistics , text analysis , and naturallanguageprocessing. positive, negative, neutral).
Famous LLMs like GPT, BERT, PaLM, and LLaMa are revolutionizing the AI industry by imitating humans. The well-known chatbot called ChatGPT, based on GPT architecture and developed by OpenAI, imitates humans by generating accurate and creative content, answering questions, summarizing massive textual paragraphs, and language translation.
Original naturallanguageprocessing (NLP) models were limited in their understanding of language. While LLMs offer potential advantages in terms of scalability and cost-efficiency, they also present meaningful challenges, especially concerning dataquality, biases, and ethical considerations.
Multilingual applications and cross-lingual tasks are central to naturallanguageprocessing (NLP) today, making robust embedding models essential. However, existing models often struggle with noisy training data, limited domain diversity, and inefficiencies in managing multilingual datasets.
LLMs are one of the most exciting advancements in naturallanguageprocessing (NLP). We will explore how to better understand the data that these models are trained on, and how to evaluate and optimize them for real-world use. This technique can be highly customizable and can handle complex tokenization requirement.
These large-scale neural networks are trained on vast amounts of data to address a wide number of tasks (i.e. naturallanguageprocessing, image classification, question answering). Data teams can fine-tune LLMs like BERT, GPT-3.5 Speed and enhance model development for specific use cases.
These large-scale neural networks are trained on vast amounts of data to address a wide number of tasks (i.e. naturallanguageprocessing, image classification, question answering). Data teams can fine-tune LLMs like BERT, GPT-3.5 Speed and enhance model development for specific use cases.
Large language models have emerged as ground-breaking technologies with revolutionary potential in the fast-developing fields of artificial intelligence (AI) and naturallanguageprocessing (NLP). Open-Source Models: Open-source models are large language models made available to the public with their source code.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Naturallanguageprocessing to extract key information quickly. However, banks may encounter roadblocks when integrating AI into their complaint-handling process.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Naturallanguageprocessing to extract key information quickly. However, banks may encounter roadblocks when integrating AI into their complaint-handling process.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Naturallanguageprocessing to extract key information quickly. However, banks may encounter roadblocks when integrating AI into their complaint-handling process.
Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Naturallanguageprocessing to extract key information quickly. However, banks may encounter roadblocks when integrating AI into their complaint-handling process.
Here are some of the key difficulties: Inconsistent Terminology : Variability in how clinicians document information, including abbreviations and jargon, makes data standardization difficult. DataQuality Issues : Clinical notes often contain errors, incomplete information, or non-standardized text, affecting extraction accuracy.
By analyzing historical data and utilizing predictive machine learning algorithms like BERT, ARIMA, Markov Chain Analysis, Principal Component Analysis, and Support Vector Machine, they can assess the likelihood of adverse events, such as hospital readmissions, and stratify patients based on risk profiles.
These large-scale neural networks are trained on vast amounts of data to address a wide number of tasks (i.e. naturallanguageprocessing, image classification, question answering). Data teams can fine-tune LLMs like BERT, GPT-3.5 Speed and enhance model development for specific use cases.
The Rise of Large Language Models The emergence and proliferation of large language models represent a pivotal chapter in the ongoing AI revolution. These models, powered by massive neural networks, have catalyzed groundbreaking advancements in naturallanguageprocessing (NLP) and have reshaped the landscape of machine learning.
2021) 2021 saw many exciting advances in machine learning (ML) and naturallanguageprocessing (NLP). 6] such as W2v-BERT [7] as well as more powerful multilingual models such as XLS-R [8]. As models are scaled up, ensuring dataquality at scale becomes more challenging. Why is it important?
The momentum continued in 2017 with the introduction of transformer models like BERT and GPT, which revolutionized naturallanguageprocessing. AI can also increase biases if trained on biased data, leading to unfair outcomes. This move was vital in reducing development costs and encouraging innovation.
Autoencoding models, which are better suited for information extraction, distillation and other analytical tasks, are resting in the background — but let’s not forget that the initial LLM breakthrough in 2018 happened with BERT, an autoencoding model. One of the most successful approaches here is instruction fine-tuning.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



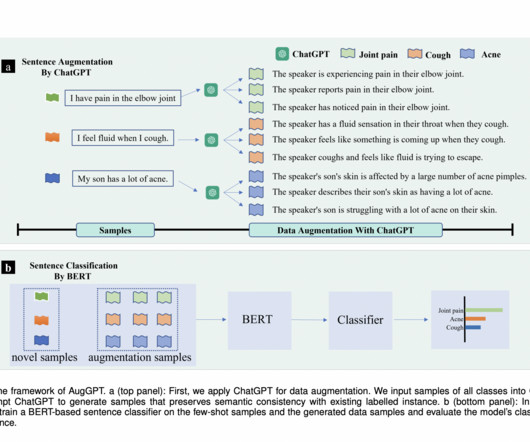
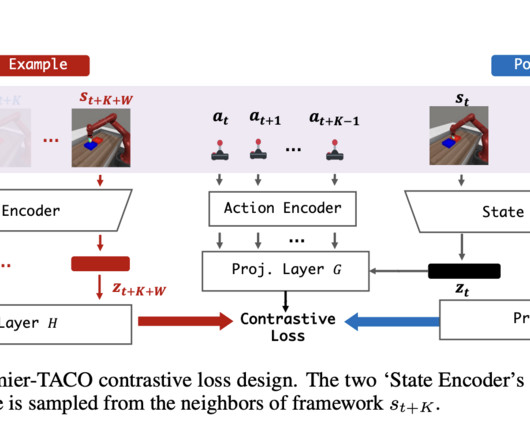
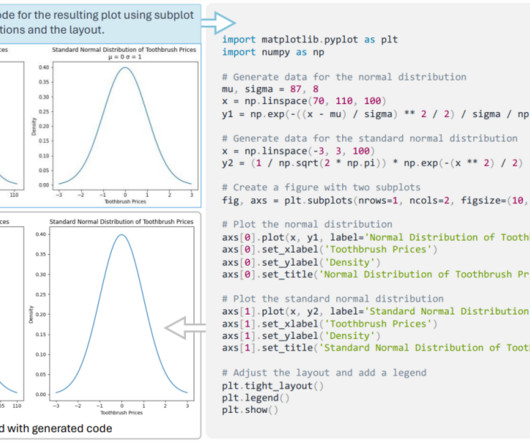






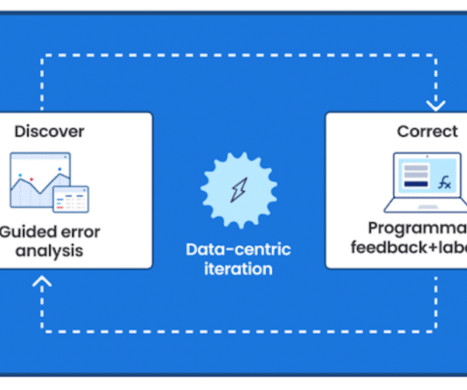
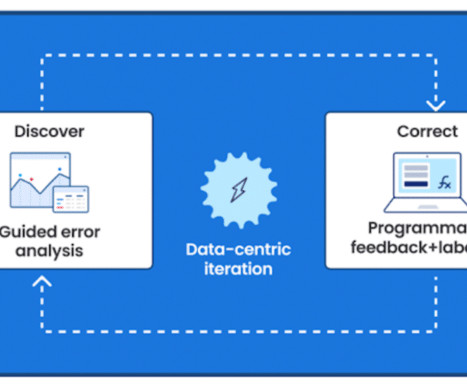
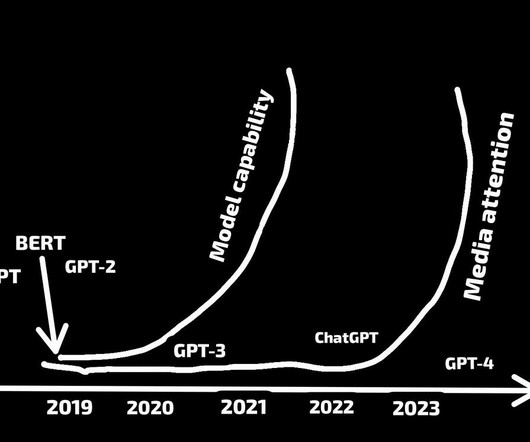
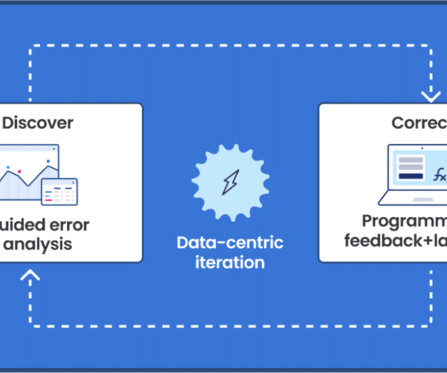
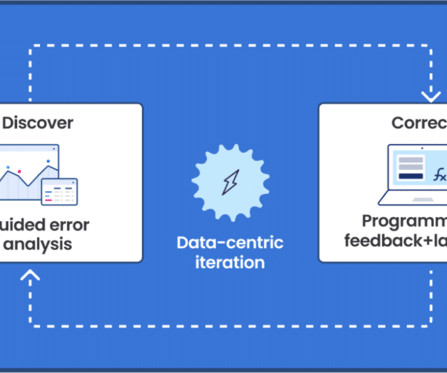
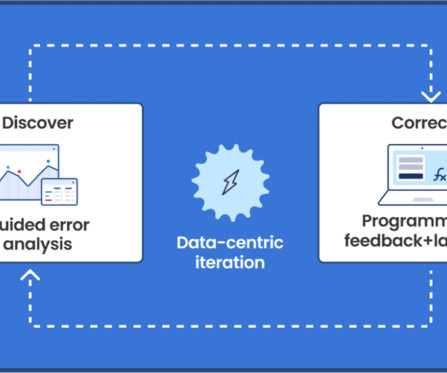
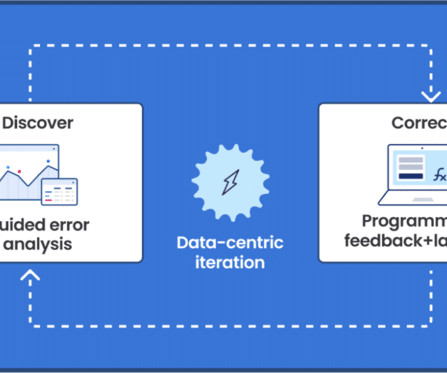






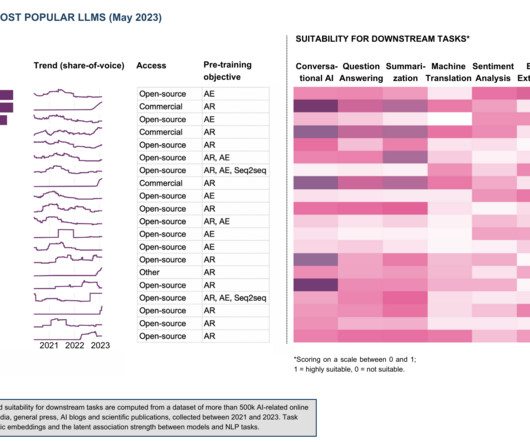






Let's personalize your content