This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
One of the most promising areas within AI in healthcare is Natural Language Processing (NLP), which has the potential to revolutionize patient care by facilitating more efficient and accurate dataanalysis and communication.
This article was published as a part of the Data Science Blogathon Image source: huggingface.io The post All NLP tasks using Transformers Pipeline appeared first on Analytics Vidhya. Contents 1. […].
The post Summarize Twitter Live data using Pretrained NLP models appeared first on Analytics Vidhya. Introduction Twitter users spend an average of 4 minutes on social media Twitter. On an average of 1 minute, they read the same stuff.
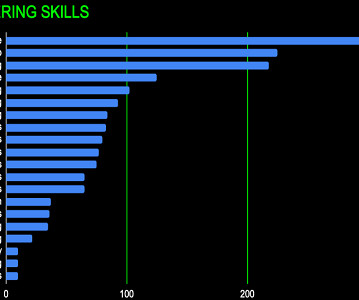
Natural language processing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader data science expertise.
Labeling the wellness dimensions requires a clear understanding of social and psychological factors; we have invited an expert panel, including a clinical psychologist, rehabilitation counselor, and social NLP researcher. This indicates that they can accurately portray the complexity of multiple dimensions in social media language.
Synthetic data , artificially generated to mimic real data, plays a crucial role in various applications, including machine learning , dataanalysis , testing, and privacy protection. However, generating synthetic data for NLP is non-trivial, demanding high linguistic knowledge, creativity, and diversity.
BERT is a state-of-the-art algorithm designed by Google to process text data and convert it into vectors ([link]. What makes BERT special is, apart from its good results, the fact that it is trained over billions of records and that Hugging Face provides already a good battery of pre-trained models we can use for different ML tasks.
NLP in particular has been a subfield that has been focussed heavily in the past few years that has resulted in the development of some top-notch LLMs like GPT and BERT. Large-scale dataanalysis methods that offer privacy protection by utilizing both blockchain and AI technology.
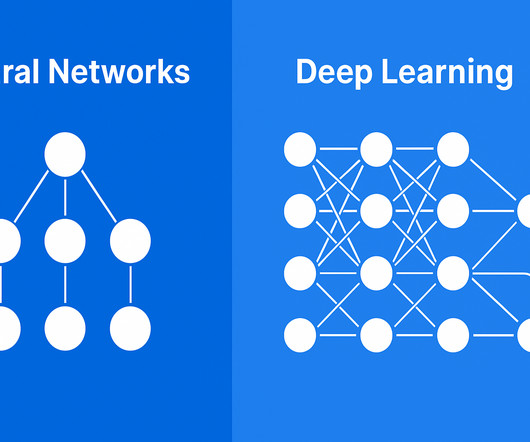
AI Capabilities : Enables image recognition, NLP, and predictive analytics. It’s composed of interconnected nodes (“neurons”) organized in layers: Input Layer: Receives the initial data (e.g., BERT) and decoder-only (e.g., Layered Architectures : Deep Learning uses CNNs, RNNs, and more.
Introduction In natural language processing, text categorization tasks are common (NLP). Depending on the data they are provided, different classifiers may perform better or worse (eg. transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e,
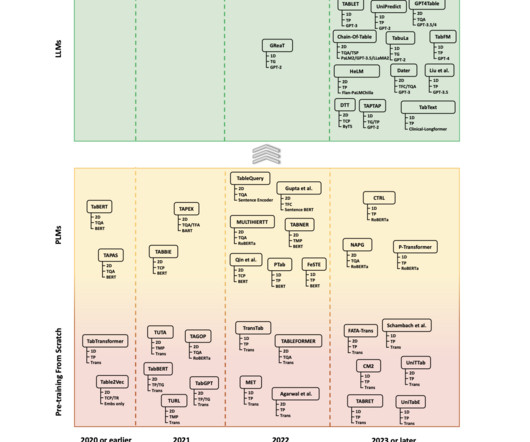
This challenge becomes even more complex given the need for high predictive accuracy and robustness, especially in critical applications such as health care, where the decisions among dataanalysis can be quite consequential. Different methods have been applied to overcome these challenges of modeling tabular data.
Summary: Deep Learning models revolutionise data processing, solving complex image recognition, NLP, and analytics tasks. Introduction Deep Learning models transform how we approach complex problems, offering powerful tools to analyse and interpret vast amounts of data. Why are Transformer Models Important in NLP?
The second course, “ChatGPT Advanced DataAnalysis,” focuses on automating tasks using ChatGPT's code interpreter. teaches students to automate document handling and data extraction, among other skills. This 10-hour course, also highly rated at 4.8,
Are you curious about the groundbreaking advancements in Natural Language Processing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. Ever wondered how machines can understand and generate human-like text?
In this post, we explore the utilization of pre-trained models within the Healthcare NLP library by John Snow Labs to map medical terminology to the MedDRA ontology. Specifically, our aim is to facilitate standardized categorization for enhanced medical dataanalysis and interpretation.
Implementing end-to-end deep learning projects has never been easier with these awesome tools Image by Freepik LLMs such as GPT, BERT, and Llama 2 are a game changer in AI. Here are the topics we’ll cover in this article: Fine-tuning the BERT model with the Transformers library for text classification. Monitoring this app with Comet.
Unlike traditional natural language processing (NLP) approaches, such as classification methods, LLMs offer greater flexibility in adapting to dynamically changing categories and improved accuracy by using pre-trained knowledge embedded within the model.
source: author Introduction Sentiment analysis is a rapidly growing field within the Natural Language Processing (NLP) domain, which deals with the automatic analysis and classification of emotions and opinions expressed in text. dplyr: This is a package for data manipulation and cleaning in R.
Biomarker And Biomarker Result Table (image resource: Caris Molecular Intelligence-MI Profile Sample Report) Challenges of Working with Unstructured Clinical Data Clinical notes are unstructured text datasets, which lack a predefined structure or format and pose significant challenges for dataanalysis and processing.
LLMs are one of the most exciting advancements in natural language processing (NLP). LLMs are trained on massive amounts of text data, allowing them to generate highly accurate predictions and responses. Tokenization: Tokenization is a crucial step in data preparation for natural language processing (NLP) tasks.
Chung , posted Jun 02 2021 at 12:20AM Applications for natural language processing (NLP) have exploded in the past decade. And when designed correctly, developers can use these techniques to build powerful NLP applications that provide natural and seamless human-computer interactions within chatbots, AI voice agents, and more.
Leaving aside the more established skills here’s a visual look at the newer skills Natural Language Processing (NLP), Tokenization, Transformers, Representation Learning and Knowledge Graphs NLP (Natural Language Processing) The NLP engineer can be considered a precursor to the Promt Engineer.
Image from "Big Data Analytics Methods" by Peter Ghavami Here are some critical contributions of data scientists and machine learning engineers in health informatics: DataAnalysis and Visualization: Data scientists and machine learning engineers are skilled in analyzing large, complex healthcare datasets.
Technologies such as Optical Character Recognition (OCR) and Natural Language Processing (NLP) are foundational to this. Google Cloud Vision API and Tesseract are prominent OCR tools for converting images of text into machine-readable data. AI’s benefits extend to processing unstructured data from news feeds and social media.
It provides a comprehensive and flexible platform that enables developers to integrate language models like GPT, BERT, and others into various applications. By offering modular tools, LangChain facilitates the creation, management, and deployment of sophisticated natural language processing (NLP) systems with minimal effort.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and Data Science, highlighting their complementary roles in DataAnalysis and intelligent decision-making. Introduction Artificial Intelligence (AI) and Data Science are revolutionising how we analyse data, make decisions, and solve complex problems.
Initially introduced for Natural Language Processing (NLP) applications like translation, this type of network was used in both Google’s BERT and OpenAI’s GPT-2 and GPT-3. Transformers taking the AI world by storm The family of artificial neural networks (ANNs) saw a new member being born in 2017, the Transformer.
By narrowing the search to the most relevant data, the retriever minimises noise and improves the quality of information passed to the generator. Generator The generator is typically a language model, such as GPT or BERT, fine-tuned to produce coherent and contextually accurate text. The global RAG market, valued at USD 1,042.7
By implementing a modern natural language processing (NLP) model, the response process has been shaped much more efficiently, and waiting time for clients has been reduced tremendously. Before we start training any NLP models, we ensure that the input data is clean and the labels are assigned according to expectation.
The potential of LLMs, in the field of pathology goes beyond automating dataanalysis. These early efforts were restricted by scant data pools and a nascent comprehension of pathological lexicons. This capability opens up possibilities in pathology where accurate and timely diagnoses can greatly influence patient outcomes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content