This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
OpenAI has been instrumental in developing revolutionary tools like the OpenAI Gym, designed for training reinforcement algorithms, and GPT-n models. One such model that has garnered considerable attention is OpenAI's ChatGPT , a shining exemplar in the realm of Large Language Models.
Project Structure Accelerating ConvolutionalNeuralNetworks Parsing Command Line Arguments and Running a Model Evaluating ConvolutionalNeuralNetworks Accelerating Vision Transformers Evaluating Vision Transformers Accelerating BERT Evaluating BERT Miscellaneous Summary Citation Information What’s New in PyTorch 2.0?
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. in 2017, marking a departure from the previous reliance on recurrent neuralnetworks (RNNs) and convolutionalneuralnetworks (CNNs) for processing sequential data.
AI models like neuralnetworks , used in applications like Natural Language Processing (NLP) and computer vision , are notorious for their high computational demands. Models like GPT and BERT involve millions to billions of parameters, leading to significant processing time and energy consumption during training and inference.
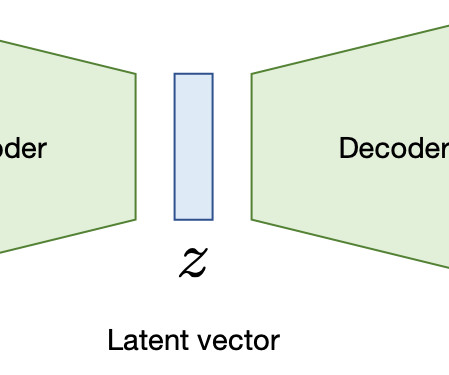
Technical Details and Benefits Deep learning relies on artificial neuralnetworks composed of layers of interconnected nodes. Notable architectures include: ConvolutionalNeuralNetworks (CNNs): Designed for image and video data, CNNs detect spatial patterns through convolutional operations.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
Models like GPT 4, BERT, DALL-E 3, CLIP, Sora, etc., Use Cases for Foundation Models Applications in Pre-trained Language Models like GPT, BERT, Claude, etc. Examples include GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), Claude, etc. with labeled data.
A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings. Images can be embedded using models such as convolutionalneuralnetworks (CNNs) , Examples of CNNs include VGG , and Inception. using its Spectrogram ).
This leap forward is due to the influence of foundation models in NLP, such as GPT and BERT. The Segment Anything Model Technical Backbone: Convolutional, Generative Networks, and More ConvolutionalNeuralNetworks (CNNs) and Generative Adversarial Networks (GANs) play a foundational role in the capabilities of SAM.
These embeddings are sometimes trained jointly with the model, but usually additional accuracy can be attained by using pre-trained embeddings such as Word2Vec, GloVe, BERT, or FastText. One model developed by OpenAI trains on 82 million Amazon reviews that it takes over a month to process!
Contrastive Language-Image Pre-training (CLIP) is a multimodal learning architecture developed by OpenAI. CLIP (Contrastive Language–Image Pre-training) is a model developed by OpenAI that learns visual concepts from natural language descriptions. It learns visual concepts from natural language supervision. What is contrast learning?
But, there are open source models like German-BERT that are already trained on huge data corpora, with many parameters. Through transfer learning, representation learning of German-BERT is utilized and additional subtitle data is provided. Some common free-to-use pre-trained models include BERT, ResNet , YOLO etc.
One of the standout achievements in this domain is the development of models like GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers). CLIP (Contrastive Language-Image Pre-training) : CLIP, developed by OpenAI, is a multi-modal model that can understand images and text.
Source ) This has led to groundbreaking models like GPT for generative tasks and BERT for understanding context in Natural Language Processing ( NLP ). Attention Mechanisms in Deep Learning Attention mechanisms are helping reimagine both convolutionalneuralnetworks ( CNNs ) and sequence models.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. Cardiologist-Level Arrhythmia Detection with ConvolutionalNeuralNetworks Awni Y. Here we go. NAACL 2019. Hannun, Pranav Rajpurkar, Masoumeh Haghpanahi, Geoffrey H. ArXiv 2017.
If you don’t know it already, NLP had a huge hype of transfer learning in this past 1 year, starting with ULMFit , ELMo , GLoMo , OpenAI transformer , BERT and recently Transformer-XL for further improving language modeling capabilities of the current state of the art.
Models like BERT and GPT took language understanding to new depths by grasping the context of words more effectively. Vision Transformers (ViTs) have significantly advanced computer vision by using attention mechanisms instead of the traditional convolutional layers.
Instead of complex and sequential architectures like Recurrent NeuralNetworks (RNNs) or ConvolutionalNeuralNetworks (CNNs), the Transformer model introduced the concept of attention, which essentially meant focusing on different parts of the input text depending on the context.
Nevertheless, the trajectory shifted remarkably with the introduction of advanced architectures like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), including subsequent versions such as OpenAI’s GPT-3.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content