
Unraveling Transformer Optimization: A Hessian-Based Explanation for Adam’s Superiority over SGD
Marktechpost
SEPTEMBER 30, 2024
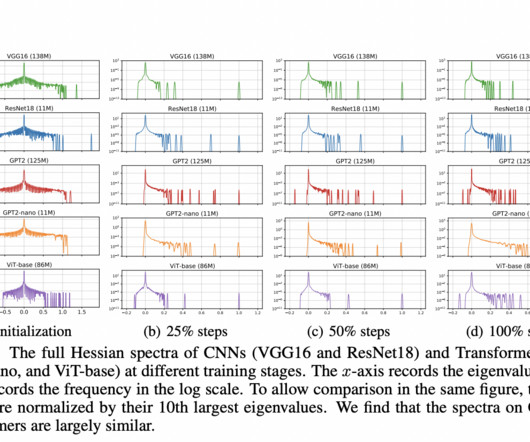
While the Adam optimizer has become the standard for training Transformers, stochastic gradient descent with momentum (SGD), which is highly effective for convolutional neural networks (CNNs), performs worse on Transformer models. This Magazine/Report will be released in late October/early November 2024.







Let's personalize your content