This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Prompt 1 : “Tell me about ConvolutionalNeuralNetworks.” ” Response 1 : “ConvolutionalNeuralNetworks (CNNs) are multi-layer perceptron networks that consist of fully connected layers and pooling layers. They are commonly used in image recognition tasks. .”
Project Structure Accelerating ConvolutionalNeuralNetworks Parsing Command Line Arguments and Running a Model Evaluating ConvolutionalNeuralNetworks Accelerating Vision Transformers Evaluating Vision Transformers Accelerating BERT Evaluating BERT Miscellaneous Summary Citation Information What’s New in PyTorch 2.0?
Advances in neuralnetwork techniques have formed the basis for transitioning from machine learning to deep learning. For instance, NN used for computer vision tasks (object detection and image segmentation) are called convolutionalneuralnetworks (CNNs) , such as AlexNet , ResNet , and YOLO.
By 2017, deep learning began to make waves, driven by breakthroughs in neuralnetworks and the release of frameworks like TensorFlow. Sessions on convolutionalneuralnetworks (CNNs) and recurrent neuralnetworks (RNNs) started gaining popularity, marking the beginning of data sciences shift toward AI-driven methods.
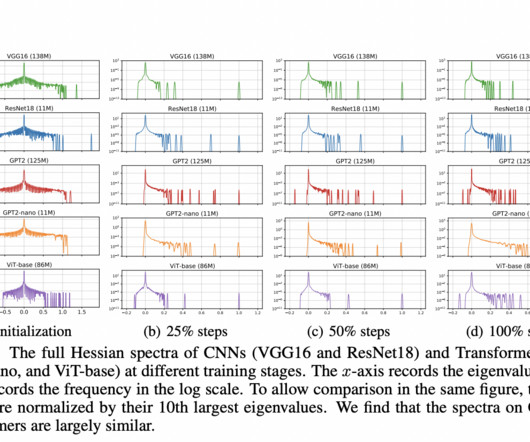
While the Adam optimizer has become the standard for training Transformers, stochastic gradient descent with momentum (SGD), which is highly effective for convolutionalneuralnetworks (CNNs), performs worse on Transformer models. A significant challenge in this domain is the inconsistency in optimizer performance.
Known for its efficiency in training convolutionalneuralnetworks, CNTK is especially notable in speech and image recognition tasks. Among its most important findings was how it enabled training BERT with double the batch size compared to PyTorch. Microsoft Cognitive Toolkit (CNTK). Apache MXNet.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
Neuralnetworks come in various forms, each designed for specific tasks: Feedforward NeuralNetworks (FNNs) : The simplest type, where connections between nodes do not form cycles. Models such as Long Short-Term Memory (LSTM) networks and Transformers (e.g., Data moves in one direction—from input to output.
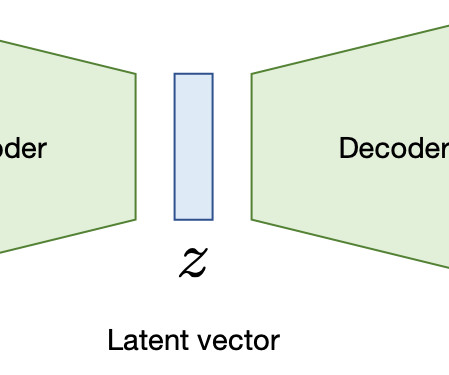
Vector Embeddings for Developers: The Basics | Pinecone Used geometry concept to explain what is vector, and how raw data is transformed to embedding using embedding model. Pinecone Used a picture of phrase vector to explain vector embedding. What are Vector Embeddings? using its Spectrogram ). All we need is the vectors for the words.
GCNs use a combination of graph-based representations and convolutionalneuralnetworks to analyze large amounts of textual data. A GCN consists of multiple layers, each of which applies a graph convolution operation to the input graph. References Paperwithcode | Graph ConvolutionalNetwork Kai, S.,
In a computer vision example of contrast learning, we aim to train a tool like a convolutionalneuralnetwork to bring similar image representations closer and separate the dissimilar ones. It typically uses a convolutionalneuralnetwork (CNN) architecture, like ResNet , for extracting image features.
Let me explain this in simple words. Learning is nothing but just getting the value of weights and biases for a neuralnetwork that gives you the desired result. A pre-trained model such as BERT or GPT can be used as a starting point and fine-tuned on a specific dataset to perform these tasks.
Furthermore, attention mechanisms work to enhance the explainability or interpretability of AI models. Source ) This has led to groundbreaking models like GPT for generative tasks and BERT for understanding context in Natural Language Processing ( NLP ).
NeurIPS’18 presented several papers with deep theoretical studies of building hyperbolic neural nets. Source: Chami et al Chami et al present Hyperbolic Graph ConvolutionalNeuralNetworks (HGCN) and Liu et al propose Hyperbolic Graph NeuralNetworks (HGNN).
Arguably, one of the most pivotal breakthroughs is the application of ConvolutionalNeuralNetworks (CNNs) to financial processes. On the other hand, NLP frameworks like BERT help in understanding the context and content of documents. Overcoming the ‘black box’ nature of AI for transparent and explainable AI systems.
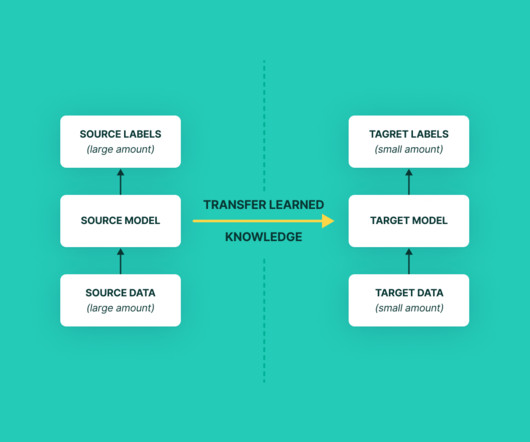
If you don’t know it already, NLP had a huge hype of transfer learning in this past 1 year, starting with ULMFit , ELMo , GLoMo , OpenAI transformer , BERT and recently Transformer-XL for further improving language modeling capabilities of the current state of the art. Apply random dropout per input sequence.
One of the standout achievements in this domain is the development of models like GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers). They owe their success to many factors, including substantial computational resources, vast training data, and sophisticated architectures.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. link] Constructing a system for NLI that explains its decisions by pointing to the most relevant parts of the input. NAACL 2019. Cambridge, Amazon. NAACL 2019. Tison, Codie Bourn, Mintu P.
Convolutionalneuralnetworks (CNNs) and recurrent neuralnetworks (RNNs) are often employed to extract meaningful representations from images and text, respectively. Building the Model Deep learning techniques have proven to be highly effective in performing cross-modal retrieval.
Object Detection Image from a personal computer Convolutionalneuralnetworks (CNNs) are utilized in object detection algorithms to identify and locate objects based on their visual attributes accurately. These algorithms can learn and extract intricate features from input images by using convolutional layers.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content