This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
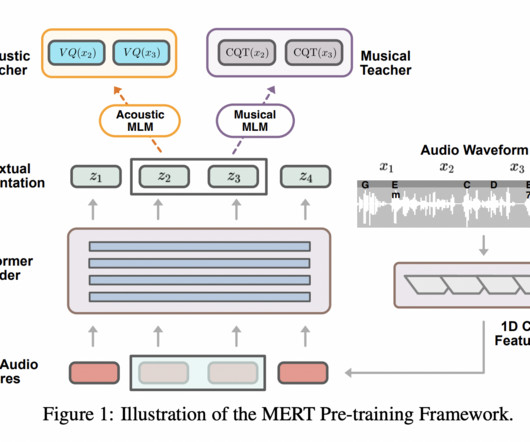
To overcome the challenge presented by single modality models & algorithms, Meta AI released the data2vec, an algorithm that uses the same learning methodology for either computervision , NLP or speech. For example, there are vocabulary of speech units in speech processing that can define a self-supervised learning task in NLP.
Attention Mechanism Image Source Course difficulty: Intermediate-level Completion time: ~ 45 minutes Prerequisites: Knowledge of ML, DL, NaturalLanguageProcessing (NLP) , ComputerVision (CV), and Python programming. Covers the different NLP tasks for which a BERT model is used.
Pixabay: by Activedia Image captioning combines naturallanguageprocessing and computervision to generate image textual descriptions automatically. Image captioning integrates computervision, which interprets visual information, and NLP, which produces human language.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. NaturalLanguageProcessing on Google Cloud This course introduces Google Cloud products and solutions for solving NLP problems.
Naturallanguageprocessing (NLP) has entered a transformational period with the introduction of Large Language Models (LLMs), like the GPT series, setting new performance standards for various linguistic tasks. Autoregressive pretraining has substantially contributed to computervision in addition to NLP.
This advancement has spurred the commercial use of generative AI in naturallanguageprocessing (NLP) and computervision, enabling automated and intelligent data extraction. LLMs like GPT, BERT, and OPT have harnessed transformers technology.
NLP, or NaturalLanguageProcessing, is a field of AI focusing on human-computer interaction using language. NLP aims to make computers understand, interpret, and generate human language. This process enhances data diversity. Prepare a novel dataset (Dn) with only a few labeled samples.
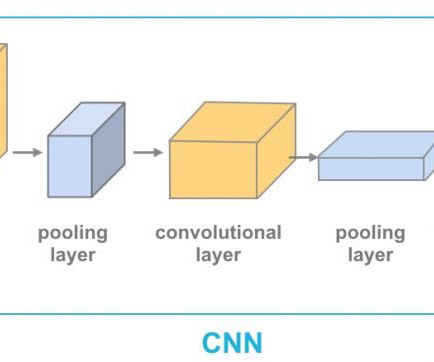
For instance, NN used for computervision tasks (object detection and image segmentation) are called convolutional neural networks (CNNs) , such as AlexNet , ResNet , and YOLO. Prominent transformer models include BERT , GPT-4 , and T5.
Figure 1: adversarial examples in computervision (left) and naturallanguageprocessing tasks (right). This is generally a positive thing, but it sometimes over-generalizes , leading to examples such as this: Figure 4: BERT guesses that the masked token should be a color, but fails to predict the correct color.
Large language models (LLMs) built on transformers, including ChatGPT and GPT-4, have demonstrated amazing naturallanguageprocessing abilities. The creation of transformer-based NLP models has sparked advancements in designing and using transformer-based models in computervision and other modalities.
A foundation model is built on a neural network model architecture to process information much like the human brain does. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. An open-source model, Google created BERT in 2018.
Put simply, if we double the input size, the computational needs can increase fourfold. AI models like neural networks , used in applications like NaturalLanguageProcessing (NLP) and computervision , are notorious for their high computational demands.
Applications for naturallanguageprocessing (NLP) have exploded in the past decade. Modern techniques can capture the nuance, context, and sophistication of language, just as humans do. Each participant will be provided with dedicated access to a fully configured, GPU-accelerated server in the cloud.
The advancements in large language models have significantly accelerated the development of naturallanguageprocessing , or NLP. These extend far beyond the traditional text-based processing of LLMs to include multimodal interactions.
The introduction of attention mechanisms has notably altered our approach to working with deep learning algorithms, leading to a revolution in the realms of computervision and naturallanguageprocessing (NLP). In 2023, we witnessed the substantial transformation of AI, marking it as the ‘year of AI.’
These models mimic the human brain’s neural networks, making them highly effective for image recognition, naturallanguageprocessing, and predictive analytics. Applications in ComputerVision CNNs dominate computervision tasks such as object detection, image classification, and facial recognition.
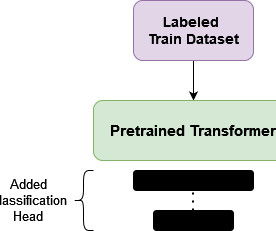
Introduction The idea behind using fine-tuning in NaturalLanguageProcessing (NLP) was borrowed from ComputerVision (CV). In the case of BERT (Bidirectional Encoder Representations from Transformers), learning involves predicting randomly masked words (bidirectional) and sentence-order prediction.
The transformer models like BERT and T5 have recently got popular due to their excellent properties and have utilized the idea of self-supervision in NaturalLanguageProcessing tasks. Self-supervised learning is being prominently used in Artificial Intelligence to develop intelligent systems.
Arguably, one of the most pivotal breakthroughs is the application of Convolutional Neural Networks (CNNs) to financial processes. This drastically enhanced the capabilities of computervision systems to recognize patterns far beyond the capability of humans. 2: Automated Document Analysis and Processing No.3:
With eight Qualcomm AI 100 Standard accelerators and 128 GiB of total accelerator memory, customers can also use DL2q instances to run popular generative AI applications, such as content generation, text summarization, and virtual assistants, as well as classic AI applications for naturallanguageprocessing and computervision.
In the rapidly evolving field of artificial intelligence, naturallanguageprocessing has become a focal point for researchers and developers alike. We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. billion word corpus).
Artificial Intelligence is a very vast branch in itself with numerous subfields including deep learning, computervision , naturallanguageprocessing , and more.
Training experiment: Training BERT Large from scratch Training, as opposed to inference, is a finite process that is repeated much less frequently. Training a well-performing BERT Large model from scratch typically requires 450 million sequences to be processed. The first uses traditional accelerated EC2 instances.
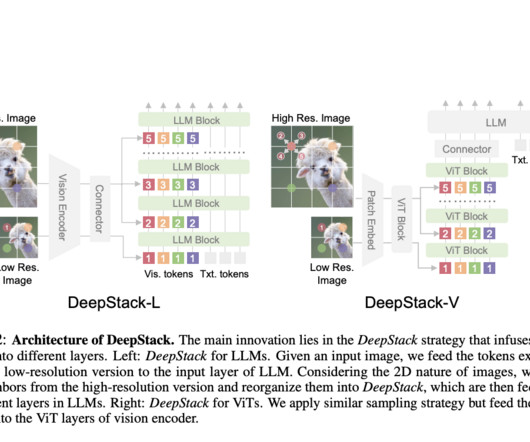
Understanding Vision Transformers (ViTs) And what I learned while implementing them! Transformers have revolutionized naturallanguageprocessing (NLP), powering models like GPT and BERT. But recently, theyve also been making waves in computervision.
From deep learning, NaturalLanguageProcessing (NLP), and NaturalLanguage Understanding (NLU) to ComputerVision, AI is propelling everyone into a future with endless innovations. It is a potent model for comprehending and processingnaturallanguage with 340 million parameters.
Models like GPT 4, BERT, DALL-E 3, CLIP, Sora, etc., Use Cases for Foundation Models Applications in Pre-trained Language Models like GPT, BERT, Claude, etc. Applications in ComputerVision Models like ResNET, VGG, Image Captioning, etc. Foundation models are recent developments in artificial intelligence (AI).
In modern machine learning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in NaturalLanguageProcessing, and Vision Transformers in computervision tasks.
Table 1 compares the average time per training or inference step for models like SAM, Gemma, BERT, and Mistral across different versions and frameworks of Keras. KerasCV and KerasNLP publish all pretrained models on Kaggle Models, which are accessible in Kaggle competition notebooks even in Internet-off mode.
Recent advancements in LLMs like BERT, T5, and GPT have revolutionized naturallanguageprocessing (NLP) using transformers and pretraining-then-finetuning strategies. After testing the LLaVA-1.5 These models excel in various tasks, from text generation to question answering.
As an example, smart venue solutions can use near-real-time computervision for crowd analytics over 5G networks, all while minimizing investment in on-premises hardware networking equipment. In our example, we use the Bidirectional Encoder Representations from Transformers (BERT) model, commonly used for naturallanguageprocessing.
This process results in generalized models capable of a wide variety of tasks, such as image classification, naturallanguageprocessing, and question-answering, with remarkable accuracy. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
Examples of text-only LLMs include GPT-3 , BERT , RoBERTa , etc. Why is there a need for Multimodal Language Models The text-only LLMs like GPT-3 and BERT have a wide range of applications, such as writing articles, composing emails, and coding.
The following example shows how to fine-tune a BERT base model identified by model_id=huggingface-tc-bert-base-cased on a custom training dataset. He has experience in working on a diverse range of machine learning problems within the domain of naturallanguageprocessing, computervision, and time series analysis.
Promptable Object Detection (POD) allows users to interact with object detection systems using naturallanguage prompts. Thus, these systems are grounded in traditional object detection and naturallanguageprocessing frameworks. Learn how Viso Suite can optimize your applications by booking a demo with our team.
Language and vision models have experienced remarkable breakthroughs with the advent of Transformer architecture. Models like BERT and GPT have revolutionized naturallanguageprocessing, while Vision Transformers have achieved significant success in computervision tasks.
Naturallanguageprocessing (NLP) is the field in machine learning (ML) concerned with giving computers the ability to understand text and spoken words in the same way as human beings can. He is currently focused on naturallanguageprocessing, responsible AI, inference optimization, and scaling ML across the enterprise.
In many areas of naturallanguageprocessing, including language interpretation and naturallanguage synthesis, large-scale training of machine learning models utilizing transformer topologies has produced ground-breaking advances.
The following is a high-level overview of how it works conceptually: Separate encoders – These models have separate encoders for each modality—a text encoder for text (for example, BERT or RoBERTa), image encoder for images (for example, CNN for images), and audio encoders for audio (for example, models like Wav2Vec).
We have seen these techniques advancing multiple fields in AI such as NLP, ComputerVision, and Robotics. Transformers-based large language models (LLMs) such as GPT-3, Jurasic, and T5 have been foundational to the advances that we see. Often these data are text, coming in the form of comment fields, notes, and descriptions.
Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. Advantages of adopting generative approaches for NLP tasks For customer feedback analysis, you might wonder if traditional NLP classifiers such as BERT or fastText would suffice.
In this solution, we train and deploy a churn prediction model that uses a state-of-the-art naturallanguageprocessing (NLP) model to find useful signals in text. Computervision. BERT + Random Forest. BERT + Random Forest. BERT + Random Forest with HPO. BERT + Random Forest.
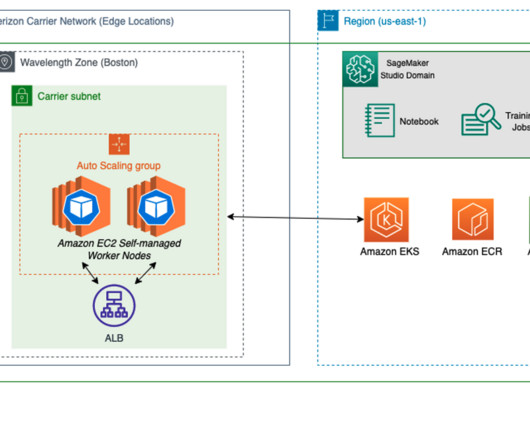
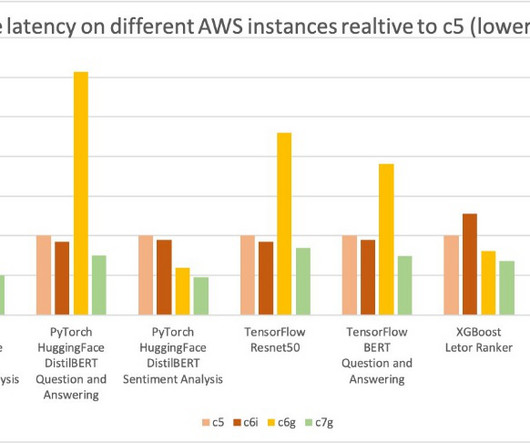
We cover computervision (CV), naturallanguageprocessing (NLP), classification, and ranking scenarios for models and ml.c6g, ml.c7g, ml.c5, and ml.c6i SageMaker instances for benchmarking.
The previous year saw a significant increase in the amount of work that concentrated on ComputerVision (CV) and NaturalLanguageProcessing (NLP). Because of this, academics worldwide are looking at the potential benefits deep learning and large language models (LLMs) might bring to audio generation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content