This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Largelanguagemodels (LLMs) built on transformers, including ChatGPT and GPT-4, have demonstrated amazing natural language processing abilities. The creation of transformer-based NLP models has sparked advancements in designing and using transformer-based models in computervision and other modalities.
Traditional neural network models like RNNs and LSTMs and more modern transformer-based models like BERT for NER require costly fine-tuning on labeled data for every custom entity type. He specializes in building machine learning pipelines that involve concepts such as natural language processing and computervision.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computervision, enabling automated and intelligent data extraction. Context-Aware Data Extraction LLMs possess strong contextual understanding, honed through extensive training on large datasets.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Its AI courses provide valuable knowledge and hands-on experience, helping learners build and optimize AI models, understand advanced AI concepts, and apply AI solutions to real-world problems.
Introduction to LargeLanguageModels Image Source Course difficulty: Beginner-level Completion time: ~ 45 minutes Prerequisites: No What will AI enthusiasts learn? This course explores LLMs (LargeLanguageModels) – AI models trained on large amounts of textual data.
” This method leverages ChatGPT, a largelanguagemodel, to generate auxiliary samples for few-shot text classification tasks. The method addresses the challenge of few-shot learning, where a model trained on a source domain with limited data is expected to generalize to a target domain with only a few examples.
From deep learning, Natural Language Processing (NLP), and Natural Language Understanding (NLU) to ComputerVision, AI is propelling everyone into a future with endless innovations. LargeLanguageModels The development of LargeLanguageModels (LLMs) represents a huge step forward for Artificial Intelligence.
The advancements in largelanguagemodels have significantly accelerated the development of natural language processing , or NLP. The integration and advent of visual and linguistic models have played a crucial role in advancing tasks that require both language processing and visual understanding.
Natural language processing (NLP) has entered a transformational period with the introduction of LargeLanguageModels (LLMs), like the GPT series, setting new performance standards for various linguistic tasks. Autoregressive pretraining has substantially contributed to computervision in addition to NLP.
What are LargeLanguageModels (LLMs)? In generative AI, human language is perceived as a difficult data type. If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a LargeLanguageModel (LLM).
For instance, NN used for computervision tasks (object detection and image segmentation) are called convolutional neural networks (CNNs) , such as AlexNet , ResNet , and YOLO. Prominent transformer models include BERT , GPT-4 , and T5. Do We Still Need Traditional Machine Learning Algorithms?
Languagemodels are statistical methods predicting the succession of tokens in sequences, using natural text. Largelanguagemodels (LLMs) are neural network-based languagemodels with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical.
A foundation model is built on a neural network model architecture to process information much like the human brain does. A specific kind of foundation model known as a largelanguagemodel (LLM) is trained on vast amounts of text data for NLP tasks. An open-source model, Google created BERT in 2018.
The advent of more powerful personal computers paved the way for the gradual acceptance of deep learning-based methods. The introduction of attention mechanisms has notably altered our approach to working with deep learning algorithms, leading to a revolution in the realms of computervision and natural language processing (NLP).
provides a robust end-to-end computervision infrastructure – Viso Suite. Our software helps several leading organizations start with computervision and implement deep learning models efficiently with minimal overhead for various downstream tasks. About us : Viso.ai Get a demo here.
Grace Hopper Superchips and H100 GPUs led across all MLPerf’s data center tests, including inference for computervision, speech recognition and medical imaging, in addition to the more demanding use cases of recommendation systems and the largelanguagemodels ( LLMs ) used in generative AI.
In this article, we will delve into the latest advancements in the world of large-scale languagemodels, exploring enhancements introduced by each model, their capabilities, and potential applications. The Most Important LargeLanguageModels (LLMs) in 2023 1. billion word corpus).
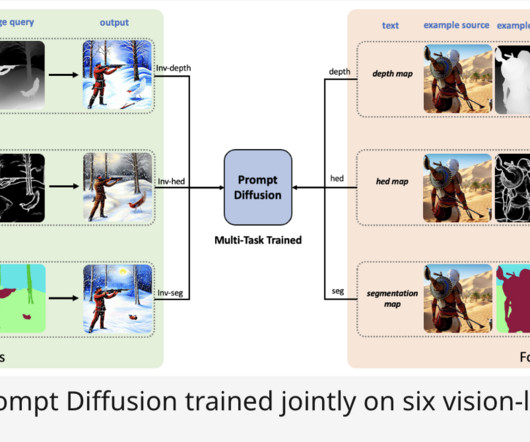
These problems, commonly referred to as degradations in low-level computervision, can arise from difficult environmental conditions like heat or rain or from limitations of the camera itself. Text Encoder A text encoder is used by languagemodels to map the user prompts to a text embedding or a fixed size vector representation.
A popular example is OpenAI’s ChatGPT, which is powered by a state-of-the-art largelanguagemodel (LMM). Training experiment: Training BERTLarge from scratch Training, as opposed to inference, is a finite process that is repeated much less frequently. The first uses traditional accelerated EC2 instances.
Largelanguagemodels (LLMs) are computermodels capable of analyzing and generating text. Examples of text-only LLMs include GPT-3 , BERT , RoBERTa , etc. This allows the models to generate responses incorporating information from multiple modalities, leading to more accurate and contextual outputs.
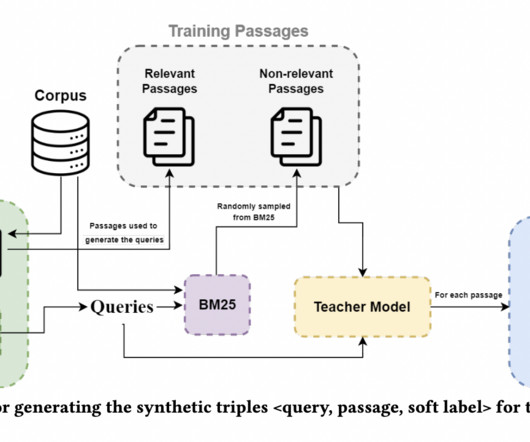
Advancements have also been made using MarginMSE loss for two distinct purposes: one for distilling knowledge across different architectural designs and another for refining sparse neural models. The first phase uses real-world data from the MS MARCO dataset to familiarize the student model with the ranking task.
In modern machine learning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in Natural Language Processing, and Vision Transformers in computervision tasks.
The transformer models like BERT and T5 have recently got popular due to their excellent properties and have utilized the idea of self-supervision in Natural Language Processing tasks. These models are first trained with massive amounts of unlabeled data, then fine-tuned with labeled data samples.
The field of artificial intelligence (AI) has witnessed remarkable advancements in recent years, and at the heart of it lies the powerful combination of graphics processing units (GPUs) and parallel computing platform. This engine can then be used to perform efficient inference on the GPU, leveraging CUDA for accelerated computation.
While HuggingFace uses a “repeat yourself” approach, KerasNLP adopts a layered approach to reimplement largelanguagemodels with minimal code. KerasCV and KerasNLP publish all pretrained models on Kaggle Models, which are accessible in Kaggle competition notebooks even in Internet-off mode.
We have seen these techniques advancing multiple fields in AI such as NLP, ComputerVision, and Robotics. Transformers-based largelanguagemodels (LLMs) such as GPT-3, Jurasic, and T5 have been foundational to the advances that we see.
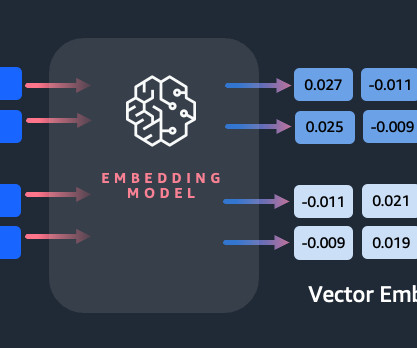
For example, some largelanguagemodels generate embedding values for words by showing the model a sentence with a missing word and asking the model to predict the missing word. Some image models use a similar approach, masking a portion of the image and then asking the model to predict what exists within the mask.
Foundation models are recent developments in artificial intelligence (AI). Models like GPT 4, BERT, DALL-E 3, CLIP, Sora, etc., Use Cases for Foundation Models Applications in Pre-trained LanguageModels like GPT, BERT, Claude, etc. are at the forefront of the AI revolution.
The previous year saw a significant increase in the amount of work that concentrated on ComputerVision (CV) and Natural Language Processing (NLP). Because of this, academics worldwide are looking at the potential benefits deep learning and largelanguagemodels (LLMs) might bring to audio generation.
Artificial Intelligence is evolving with the introduction of Generative AI and LargeLanguageModels (LLMs). Well-known models like GPT, BERT, PaLM, etc., are some great additions to the long list of LLMs that are transforming how humans and computers interact.
Another common approach is to use largelanguagemodels (LLMs), like BERT or GPT, which can provide contextualized embeddings for entire sentences. She leads machine learning (ML) projects in various domains such as computervision, natural language processing and generative AI.
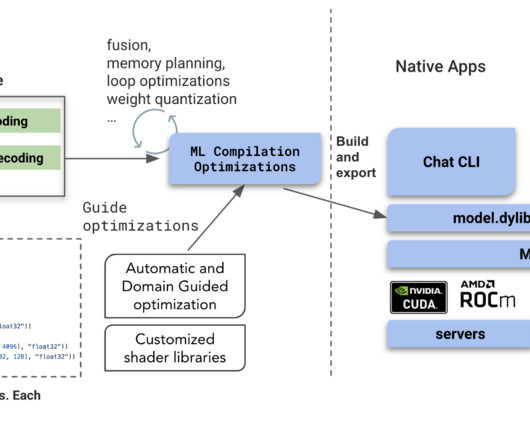
GPT-J is a transformer model trained using Ben Wang’s Mesh Transformer JAX. In this post, we present a guide and best practices on training largelanguagemodels (LLMs) using the Amazon SageMaker distributed model parallel library to reduce training time and cost.
LargeLanguageModels (LLMs) are the current hot topic in the field of Artificial Intelligence. The well-known largelanguagemodels such as GPT, DALLE, and BERT perform extraordinary tasks and ease lives.
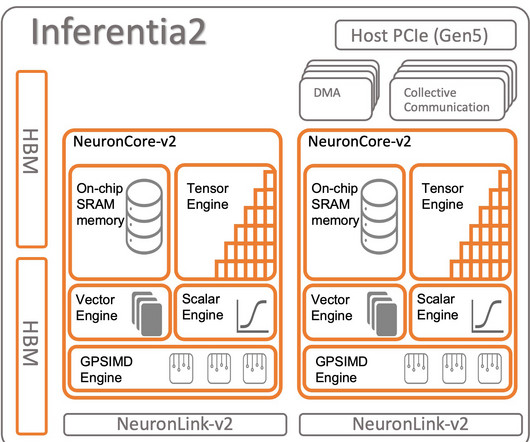
The size of the machine learning (ML) models––largelanguagemodels ( LLMs ) and foundation models ( FMs )–– is growing fast year-over-year , and these models need faster and more powerful accelerators, especially for generative AI. AWS Inferentia2 NeuronCore-v2 is faster and more optimized.
State-of-the-art largelanguagemodels (LLMs), including BERT, GPT-2, BART, T5, GPT-3, and GPT-4, have been developed as a result of recent advances in machine learning, notably in the area of natural language processing (NLP).
The research extensively evaluated the LIxP approach across various model sizes, datasets, and few-shot adaptation methods. Using ViT image encoders and BERT text encoders, the team tested context-aware pretraining on 21 diverse datasets. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
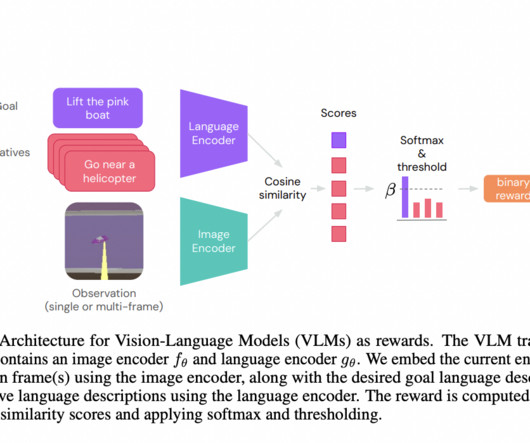
Operating in a partially observed Markov Decision Process, the premium is computed through a VLM based on scanned images and language-based goals. It demonstrates deriving rewards for diverse language goals from CLIP, training RL agents across Playhouse and AndroidEnv domains.
The following is a high-level overview of how it works conceptually: Separate encoders – These models have separate encoders for each modality—a text encoder for text (for example, BERT or RoBERTa), image encoder for images (for example, CNN for images), and audio encoders for audio (for example, models like Wav2Vec).
Natural language processing ( NLP ) and computervision can capture values specific to the trial subject that help identify or exclude potential participants, creating alignment across different systems and document types. Snorkel natively integrates closed-API models such as GPT-3.5
Researchers believe they can train a languagemodel because of the competition to construct enormously largemodels that the power of scale has sparked. The initial BERTmodel is used for many real-world applications in natural language processing.
Generated with Bing and edited with Photoshop Predictive AI has been driving companies’ ROI for decades through advanced recommendation algorithms, risk assessment models, and fraud detection tools. The model then learns to predict the masked tokens based on the context of the surrounding words.
In the context of LLM (LargeLanguageModels), text annotation is often used to train and improve the accuracy of these models for specific natural languages processing tasks, such as named entity recognition, part-of-speech tagging, and sentiment analysis. Thanks for your support!
In today’s rapidly evolving landscape of artificial intelligence, deep learning models have found themselves at the forefront of innovation, with applications spanning computervision (CV), natural language processing (NLP), and recommendation systems. device batch = [t.to(device) device batch = [t.to(device)
Natural language processing ( NLP ) and computervision can capture values specific to the trial subject that help identify or exclude potential participants, creating alignment across different systems and document types. Snorkel natively integrates closed-API models such as GPT-3.5
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content