This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Welcome to the transformative world of NaturalLanguageProcessing (NLP). Here, the elegance of human language meets the precision of machine intelligence. The unseen force of NLP powers many of the digital interactions we rely on.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
In recent years, NaturalLanguageProcessing (NLP) has undergone a pivotal shift with the emergence of Large Language Models (LLMs) like OpenAI's GPT-3 and Google’s BERT. Beyond traditional search engines, these models represent a new era of intelligent Web browsing agents that go beyond simple keyword searches.
They are now capable of naturallanguageprocessing ( NLP ), grasping context and exhibiting elements of creativity. Innovators who want a custom AI can pick a “foundation model” like OpenAI’s GPT-3 or BERT and feed it their data.
This is heavily due to the popularization (and commercialization) of a new generation of general purpose conversational chatbots that took off at the end of 2022, with the release of ChatGPT to the public. This concept is not exclusive to naturallanguageprocessing, and has also been employed in other domains.
GPT 3 and similar Large Language Models (LLM) , such as BERT , famous for its bidirectional context understanding, T-5 with its text-to-text approach, and XLNet , which combines autoregressive and autoencoding models, have all played pivotal roles in transforming the NaturalLanguageProcessing (NLP) paradigm.
1966: ELIZA In 1966, a chatbot called ELIZA took the computer science world by storm. ELIZA was rudimentary but felt believable and was an incredible leap forward for chatbots. Since it was one of the first chatbots ever designed, it was also one of the first programs capable of attempting the Turing Test.
NLP, or NaturalLanguageProcessing, is a field of AI focusing on human-computer interaction using language. Text analysis, translation, chatbots, and sentiment analysis are just some of its many applications. NLP aims to make computers understand, interpret, and generate human language.
Naturallanguageprocessing (NLP) focuses on enabling computers to understand and generate human language, making interactions more intuitive and efficient. Recent developments in this field have significantly impacted machine translation, chatbots, and automated text analysis.
Applications for naturallanguageprocessing (NLP) have exploded in the past decade. Modern techniques can capture the nuance, context, and sophistication of language, just as humans do. Each participant will be provided with dedicated access to a fully configured, GPU-accelerated server in the cloud.
This week, we have discussed some of the latest industry innovations and trends like GraphRAG, Agentic chatbots, evolving trends with search engines, and some very interesting project-based collaboration opportunities. Author(s): Towards AI Editorial Team Originally published on Towards AI. Good morning, AI enthusiasts! Enjoy the read!
Naturallanguageprocessing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., rely on Language Models as their foundation. Unigrams, N-grams, exponential, and neural networks are valid forms for the Language Model.
With advancements in deep learning, naturallanguageprocessing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. These AI agents, transcending chatbots and voice assistants, are shaping a new paradigm for both industries and our daily lives.
In the expanding naturallanguageprocessing domain, text embedding models have become fundamental. These models convert textual information into a numerical format, enabling machines to understand, interpret, and manipulate human language.
In the rapidly evolving field of artificial intelligence, naturallanguageprocessing has become a focal point for researchers and developers alike. We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. billion word corpus).
Large Language Models have emerged as the central component of modern chatbots and conversational AI in the fast-paced world of technology. The use cases of LLM for chatbots and LLM for conversational AI can be seen across all industries like FinTech, eCommerce, healthcare, cybersecurity, and the list goes on.
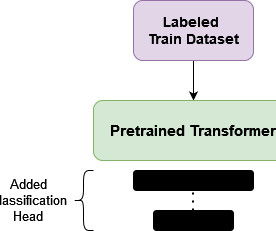
Well do so in three levels: first, by manually adding a classification head in PyTorch* and training the model so you can see the full process; second, by using the Hugging Face* Transformers library to streamline the process; and third, by leveraging PyTorch Lightning* and accelerators to optimize training performance.
The introduction of attention mechanisms has notably altered our approach to working with deep learning algorithms, leading to a revolution in the realms of computer vision and naturallanguageprocessing (NLP). These models are trained on massive amounts of text data to learn patterns and relationships in the language.
Naturallanguageprocessing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. BERT even accounts for the context of words, allowing for more accurate results related to respective queries and tasks.
Photo by Shubham Dhage on Unsplash Introduction Large language Models (LLMs) are a subset of Deep Learning. Image by YouTube video “Introduction to large language models” on YouTube Channel “Google Cloud Tech” What are Large Language Models? NaturalLanguageProcessing (NLP) is a subfield of artificial intelligence.
Overview of Meta Llama Project Overview of Llama 2 pre-training and fine-tuning process As a pivotal tool within Meta's ecosystem, Llama has far-reaching implications. Its robust naturallanguage capabilities empower developers to build and fine-tune powerful chatbots, language translation, and content generation systems.
These limitations are particularly significant in fields like medical imaging, autonomous driving, and naturallanguageprocessing, where understanding complex patterns is essential. This approach is not only time-consuming but can also miss subtle patterns in the data. What is Deep Learning?
With the release of the latest chatbot developed by OpenAI called ChatGPT, the field of AI has taken over the world as ChatGPT, due to its GPT’s transformer architecture, is always in the headlines. Chatbots – LLMs are frequently utilized in the creation of chatbots and systems that use conversational AI.
These models mimic the human brain’s neural networks, making them highly effective for image recognition, naturallanguageprocessing, and predictive analytics. Transformer Models Transformer models have revolutionised the field of Deep Learning, particularly in NaturalLanguageProcessing (NLP).
Are you curious about the groundbreaking advancements in NaturalLanguageProcessing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. and GPT-4, marked a significant advancement in the field of large language models.
Famous LLMs like GPT, BERT, PaLM, and LLaMa are revolutionizing the AI industry by imitating humans. The well-known chatbot called ChatGPT, based on GPT architecture and developed by OpenAI, imitates humans by generating accurate and creative content, answering questions, summarizing massive textual paragraphs, and language translation.
Original naturallanguageprocessing (NLP) models were limited in their understanding of language. LLMs leverage deep learning architectures to process and understand the nuances and context of human language. Bloom Bloom is an autoregressive large language model developed by BigScience with 176B parameters.
Training experiment: Training BERT Large from scratch Training, as opposed to inference, is a finite process that is repeated much less frequently. Training a well-performing BERT Large model from scratch typically requires 450 million sequences to be processed. The first uses traditional accelerated EC2 instances.
The journey continues with “NLP and Deep Learning,” diving into the essentials of NaturalLanguageProcessing , deep learning's role in NLP, and foundational concepts of neural networks. Building a customer service chatbot using all the techniques covered in the course.
ChatGPT, the latest chatbot developed by OpenAI, has been in the headlines ever since its release. translates languages, summarizes long textual paragraphs while retaining the important key points, and even generates code samples.
This chatbot, based on NaturalLanguageProcessing (NLP) and NaturalLanguage Understanding (NLU), allows users to generate meaningful text just like humans. Other LLMs, like PaLM, Chinchilla, BERT, etc., It meaningfully answers questions, summarizes long paragraphs, completes codes and emails, etc.
That work inspired researchers who created BERT and other large language models , making 2018 a watershed moment for naturallanguageprocessing, a report on AI said at the end of that year.
Large language models (LLMs) have exploded in popularity over the last few years, revolutionizing naturallanguageprocessing and AI. From chatbots to search engines to creative writing aids, LLMs are powering cutting-edge applications across industries. LLMs utilize embeddings to understand word context.
This is a crucial advancement in real-time applications such as chatbots, recommendation systems, and autonomous systems that require quick responses. These techniques allow TensorRT-LLM to optimize inference performance for deep learning tasks such as naturallanguageprocessing, recommendation engines, and real-time video analytics.
This process results in generalized models capable of a wide variety of tasks, such as image classification, naturallanguageprocessing, and question-answering, with remarkable accuracy. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
Here are a few examples across various domains: NaturalLanguageProcessing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., For example, large language models (LLMs) are trained by randomly replacing some of the tokens in training data with a special token, such as [MASK].
Imagine you want to flag a suspicious transaction in your bank account, but the AI chatbot just keeps responding with your account balance. Implicit Learning of Intent : LLMs like GPT, BERT, or other transformer-based models learn to predict the next word or fill in missing text based on surrounding context.
Large Language Models (LLMs) are becoming popular with every new update and new releases. LLMs like BERT, GPT, and PaLM have shown tremendous capabilities in the field of NaturalLanguageProcessing and NaturalLanguage Understanding.
Clearly, chatbots are here to stay. Not all are made equal, however – the choice of technology is what sets great chatbots apart from the rest. Despite 80% of surveyed businesses wanting to use chatbots in 2020 , how many do you think will implement them well? AI researchers have been building chatbots for well over sixty years.
Semantic search uses NaturalLanguageProcessing (NLP) and Machine Learning to interpret the intent behind a users query, enabling more accurate and contextually relevant results. Embedding models are the backbone of semantic search, powering applications in NaturalLanguageProcessing (NLP), recommendation systems, and more.
Sentence embeddings are a powerful tool in naturallanguageprocessing that helps analyze and understand language. Specifically, it involves using pre-trained transformer models, such as BERT or RoBERTa, to encode text into dense vectors that capture the semantic meaning of the sentences.
Its key features support scalable designs, efficient prompt management, and real-time data processing. It is ideal for creating robust AI solutions across various industries, from chatbots to personalised recommendation systems. Ideal for building intelligent chatbots, personalised recommendations, and automated content generation.
Different types of neural networks, such as feedforward, convolutional, and recurrent networks, are designed for specific tasks like image recognition, NaturalLanguageProcessing, and sequence modelling. BERT and GPT) are used for tasks like machine translation, sentiment analysis, and text generation.
A brief history of large language models Large language models grew out of research and experiments with neural networks to allow computers to processnaturallanguage. In the 2010s, this research intersected with the then-bustling field of neural networks, setting the ground for the first large language model.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content