This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. Running Code : Beyond generating code, Auto-GPT can execute both shell and Python codes. Deep learning techniques further enhanced this, enabling sophisticated image and speech recognition.
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. In a recent talk at Google Berlin, Jacob Devlin described how Google are using his BERT architectures internally. We provide an example component for text categorization.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Prompt engineering To invoke Amazon Bedrock, you can follow our code sample that uses the Python SDK. For more information, refer to Prompt engineering.
In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. We show you how to train, deploy and use a churn prediction model that has processed numerical, categorical, and textual features to make its prediction. CPU Optimized) image/kernel is used. Sentence transformer.
The DeepPavlov Library uses BERT base models to deal with Question Answering, such as RoBERTa. BERT is a pre-trained transformer-based deep learning model for natural language processing that achieved state-of-the-art results across a wide array of natural language processing tasks when this model was proposed.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
You can use this notebook job step to easily run notebooks as jobs with just a few lines of code using the Amazon SageMaker Python SDK. These jobs can be run immediately or on a recurring time schedule without the need for data workers to refactor code as Python modules.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! Introduction to SpaCy SpaCy is a python library designed to provide a “complete” NLP pipeline, including ingestion, tokenization, tagging, representation, and even classification. Editor’s note: Benjamin Batorsky, PhD is a speaker for ODSC East 2023.
It uses BERT, a popular NLP technique, to understand the meaning and context of words in the candidate summary and reference summary. The more similar the words and meanings captured by BERT, the higher the BERTScore. It uses neural networks like BERT to measure semantic similarity beyond just exact word or phrase matching.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
One such tool is LangTest, an open-source Python library meticulously crafted to evaluate and enhance language models. LangTest is a powerful open-source Python library specifically tailored for evaluating and augmenting language models. We can check the detailed results using .generated_results() It provides us the below table.
Text Classification: Categorize text into predefined groups for content moderation and tone detection. Natural Language Question Answering : Use BERT to answer questions based on text passages. The TensorFlow Lite Converter landing page contains a Python API to convert the model.
Transformer-based models, such as Bidirectional Encoder Representations from Transformers (BERT), have revolutionized NLP by offering accuracy comparable to human baselines on benchmarks like SQuAD for question-answer, entity recognition, intent recognition, sentiment analysis, and more. Basic understanding of neural networks.
adds 5 new pipeline packages, including a new core family for Catalan and a new transformer-based pipeline for Danish using the danish-bert-botxo weights. pip install spacy-huggingface-hub huggingface-cli login # Package your pipeline python -m spacy package./en_ner_fashion./output ca_core_news_md Catalan 98.3 en_ner_fashion./output
While embeddings have become a popular way to represent unstructured data, they can also be generated for categorical and numeric variables in tabular datasets. This function makes it easy to define custom aggregation functions in Python. October 2022).
Its categorical power is brittle. Our examples use Python, but the concepts apply equally well to other coding languages. Other writers have composed thorough and robust tutorials on using the OpenAI Python library or using LangChain. BERT for misinformation. The largest version of BERT contains 340 million parameters.
Its categorical power is brittle. Our examples use Python, but the concepts apply equally well to other coding languages. Other writers have composed thorough and robust tutorials on using the OpenAI Python library or using LangChain. BERT for misinformation. The largest version of BERT contains 340 million parameters.
Its categorical power is brittle. Our examples use Python, but the concepts apply equally well to other coding languages. Other writers have composed thorough and robust tutorials on using the OpenAI Python library or using LangChain. BERT for misinformation. The largest version of BERT contains 340 million parameters.
In this blog, we’ll explore the concept of transfer learning, how it technically works, and provide a step-by-step guide to implementing it in Python. But, there are open source models like German-BERT that are already trained on huge data corpora, with many parameters. Let us understand how this works.
Suggested materials to satisfy prerequisites: Python Beginner’s Guide. Suggested materials to satisfy prerequisites: Python Beginner’s Guide. In this workshop, you’ll learn how to use Transformer-based natural language processing models for text classification tasks, such as categorizing documents.
Spark NLP Display is an open-source python library for visualizing the extracted and labelled entities generated with Spark NLP. When applied to new unlabeled files, the models can categorize them at high accuracy. The top performing model was a BERT-based architecture fine-tuned on this specialized dataset.
For example, a company may enrich documents in bulk to translate documents, identify entities and categorize those documents, etc. Create a Tweets Classifier model A prerequisite to executing the SageMaker batch job is to create a Tweets classifier (HuggingFace BERT) model on SageMaker. ", instance_type="ml.m5.xlarge",
We want to aggregate it, link it, filter it, categorize it, generate it and correct it. In their experiments, OpenAI prompted GPT3 with 32 examples of each task, and found that they were able to achieve similar accuracy to the BERT baselines. This is unfortunate, because that’s what the web almost entirely consists of.
spaCy is an open-source library for industrial-strength natural language processing in Python. Clearly, we couldn’t use a model such as BERT or GPT-2 directly. Inspired by names such as ELMo and BERT, we’ve termed this trick Language Modelling with Approximate Outputs (LMAO). Even more recently, Li et al.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. The CUDA platform is used through complier directives and extensions to standard languages, such as the Python cuNumeric library.
The Python example below showcases a ReAct pattern. They can decide to pass calculations to a calculator or Python interpreter depending on the situation. LangChain categorizes its chains into three types: Utility chains, Generic chains, and Combine Documents chains. Toolkits : Collections of tools. Two key LLM models are GPT-3.5
Like other large language models, including BERT and GPT-3, LaMDA is trained on terabytes of text data to learn how words relate to one another and then predict what words are likely to come next. Text classification for spam filtering, topic categorization, or document organization. How is the problem approached? Code generation.
Large models like GPT-3 (175B parameters) or BERT-Large (340M parameters) can be reduced by 75% or more. Running BERT models on smartphones for on-device natural language processing requires much less energy due to resource constrained in smartphones than server deployments.
We'll also walk through the essential features of Hugging Face, including pipelines, datasets, models, and more, with hands-on Python examples. Below is a Python snippet demonstrating this: sentences = ["I am thrilled to introduce you to the wonderful world of AI.", These are deep learning models used in NLP.
These advanced AI deep learning models have seamlessly integrated into various applications, from Google's search engine enhancements with BERT to GitHub’s Copilot, which harnesses the capability of Large Language Models (LLMs) to convert simple code snippets into fully functional source codes.
The transformer architecture was the foundation for two of the most well-known and popular LLMs in use today, the Bidirectional Encoder Representations from Transformers (BERT) 4 (Radford, 2018) and the Generative Pretrained Transformer (GPT) 5 (Devlin 2018). Thus the basis of the transformer model was born.
Key strengths of VLP include the effective utilization of pre-trained VLMs and LLMs, enabling zero-shot or few-shot predictions without necessitating task-specific modifications, and categorizing images from a broad spectrum through casual multi-round dialogues. TGI is implemented in Python and uses the PyTorch framework.
The first two can be categorized as inductive bias of humans and the last one is introducing compute over human element; which provides the following advantages: Unbiased Exploration: Evolutionary algorithms can systematically explore a vast space of potential model combinations, significantly exceeding human capabilities.
Entity Typing (ET): Categorizes entities into more fine-grained types (e.g., Pre-trained Language Models: Utilizing pre-trained language models like BERT or ELMo injects rich background knowledge into the NER process. scientists, artists).
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















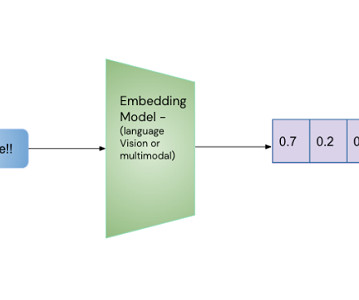






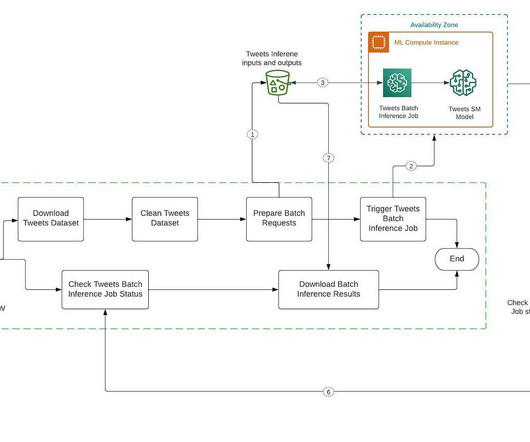








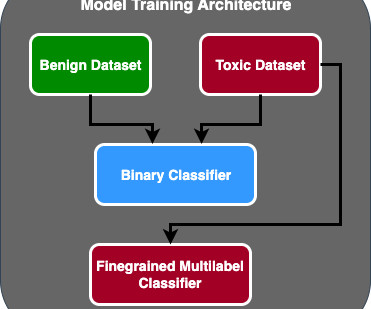









Let's personalize your content